
以前,有一位测试主管并不认同敏捷开发。每当团队谈论减少浪费、冲刺和小规模交付时,她总是礼貌地点头。然而,她转身却按照自己的方式行事,而她的方式确实奏效了。她的项目通常都能按时完成,保持了很高的质量标准,而且发布过程通常都是平静且顺畅的。
然而,有一天,她遇到了难题。一个“简单”的迁移项目,其简单目标就是“让它像以前一样工作”,只不过是优化和迁移,看起来易如反掌。但是,这是一个新组建的团队。该应用程序可能有成百上千万种可能的测试组合。之前的测试活动记录得很糟糕。需求和预期行为不明确、缺失甚至相互矛盾,有许多棘手的缺陷隐藏在过于复杂的代码中。这个项目开始看起来像是一个无法克服的挑战。此外,与用户和管理层之间紧张的关系也给团队带来了压力,称这是他们的最后机会。这次必须成功,否则他们再也不能重构任何东西了。时间紧迫,压力巨大。
我们这位陷入困境的测试主管试图坚守阵地,但命运就是不给她所需的6到12个月时间。当她几乎要放弃时,团队中一位眼神明亮的测试人员突然建议研究思维导图。在一天之内,多亏了思维导图,我们的英雄彻底改变了她的看法。他们成功地将测试活动从缓慢、重复和混乱转变为高效、基于风险和上下游驱动的测试机器。那位测试主管就是我,我想分享一些我对可视化模型的热爱,以及它如何也能帮助到你。
我们稍后再回到那个项目。首先,让我们深入探讨模型,特别是可视化模型。
可视化模型——它们是如何工作的,以及为什么有效?
模型是对现实的一种简化与抽象,具有特定的目的。它从来都不是全部真相——而是我们可以用来实现某些目标真相的一个方面。
把所有信息都汇聚在一起不是更好吗?嗯,其实并不一定。你有没有看过建筑设计图纸,比如一栋房子的设计图纸?当你建造一栋房子或者想要改造它时,你需要很多信息。比如你需要知道电线的位置,水管的位置,你需要知道哪些墙是承重墙等等。如果你正在规划如何布置家具——你还需要知道房间的大小、门窗的位置,也许还有电源插座的位置,也许还有你可以安装吊灯的地方。但是,如果你把所有这些信息都放在一张图片上——那它将没有任何用处。相反,我们可能会有多个相同房子的模型,每个模型都有不同的用途。你甚至可能想将其中一些模型结合起来,但如果你把它们都叠放在一起——那它们也将没有任何用处——因为这样会有太多的冗余信息。而如果你正在做一些完全不同的事情,比如规划你的花园或者在哪里建篱笆,你可能需要缩小视野并专注于土地边界,一个包含房屋位置和花坛、草坪、树篱轮廓的土地概览,也许还有你可以安装游泳池或客房的地方。你需要一个包含恰好适合你自己目的的信息模型——不多也不少,非常精准。
模型有各种形状和大小,各自具有不同的目的、优点和缺点。我们有物理模型,如天体仪(太阳系的机械模型)、分子模型、建筑模型、解剖模型以及飞机比例模型。所有这些模型都极大地简化了以更直观的方式展示物体的不同方面。想象一下,如果能够展示行星如何相互运动、内脏在体内的外观和位置,或者分子中原子是如何连接的,这将带来多大的好处。想想看,如果没有这些模型,要讲授这些知识会有多么复杂。
然后我们有数学或统计模型,我们将一组数据通过不同类型的计算,以尝试找出其关系和模式,并根据模型的结果进行预测。我们还有概念模型,我们试图描述和表示现实世界系统或概念的某些方面,以便使其更易于理解。此外,我们有流程图、状态图、系统图、数据模型、过程图、用户故事图、沃德利图(Wardley Maps)和思维导图等。本文的其余部分将重点介绍这些模型,并且从现在开始,我将使用“可视化模型”这一术语。
建模并不一定能呈现出问题内容的完整画面。这意味着模型中未包含的内容将不会被考虑,也意味着我们的任何偏见都会在模型中反映出来。然而,建模也是一种超能力——因为它允许我们剔除所有不相关的信息,并将注意力集中在对我们而言特别重要的方面。以我的例子为例,几乎一半的(理论上)可能的功能组合在现实生活中是永远不会发生的。仅仅通过阅读需求文档很难看出这一信息,但一旦将所有信息放入可视化模型(即我的思维导图)中,就变得一目了然了。
任何模型都非常擅长于消除噪音。可视化模型尤其像是你记忆的作弊代码。与书面交流和文档相比,它们能在相对较短的时间内传达出更多的信息。
这当然在很大程度上归功于抽象消除噪音的作用。有趣的是,还有一个叫做“图形优越性效应”(PSE)的概念,可以描述为:“输入图形越直观,人们识别、理解和回忆其内容的可能性就越大”。
为了解释这种效应有多强,请想象以下情况:
让一群人只通过文本记住一个单词或一句话。72小时后,大约只有10%的信息能被记住。如果你加上一张图片,这个比例就会上升到65%。如果图片是彩色的,那么记忆率会高达85%!这可能是因为彩色图像在记忆中的表示更为“丰富”。最好的记忆方式是文字和图片的结合。
视觉是迄今为止我们最主要的一种感觉,占据了我们大脑资源的一半左右。而且其中大部分是图片化的,而不是书面文字。
首先,图像是并行处理的,这意味着我们可以同时接收多张图片,而语言信息是顺序处理的——意味着我们一次处理一个片段,它们也在大脑的不同部位进行处理。
因此,通过使用图片和模型,我们既可以减轻阅读和记忆的心理负担,又可以大大提高读者实际记住信息的可能性。此外,与将信息写成文本相比,在模型(如思维导图)中浓缩信息要容易得多。即使使用信息列表等方式,为了传达相同的信息,你也需要拼写出更多的内容。
最后,由于这种方法的优越性,它也更有可能引发讨论并发现错误的假设,而不是发送一份文字繁杂的文字文档。它创造了一种共同的语言,不仅可用于测试场景,还可用于系统文档、需求规范等。当然,你可能需要调整模型以表示不同的方面,但这比重写一份文字文档要容易得多。
可视化模型实例
让我们来探究几种不同类型的常见模型,以及你可以在何时如何使用它们。
流程图
流程图将一个过程分解成一系列的顺序步骤。它是一个非常通用的工具,可以适应各种不同的目的,也可以用于基本上任何类型的流程。它对于更好地理解一个流程、沟通、记录或识别流程中的缺陷(改进空间)是非常有用的。
但另一方面,流程图很容易变得非常复杂,因为流程很少像我们希望的那样黑白分明。在之前的例子中,你看到的是一个保险索赔流程的非常抽象的流程图。在现实中,这通常包含多个不同的泳道和可能的节点流向,因此必须能够找到足够小且简单的流程部分进行记录,以使流程图更加有用。但话说回来,如果做得太小,它又变得不那么有用了。
状态图
状态图旨在通过状态来可视化系统,其中每个状态都有一组与其他状态不同的特定特征。它根据状态、转换以及这些转换所导致的事件来描述系统。只要潜在的状态和转换较少,它就是展示系统行为的一种好方法。就像流程图一样,它很容易变得过于复杂,或者需要太多的抽象简化才能真正有用。
在软件开发中,它是一种识别测试场景的好方法,因为状态转换是发现可能出错的地方(即风险)的重要条件。
数据库模型
数据库模型是表、字段以及它们之间关系的可视化模型。
在下面的示例中,你看到一个极其简单的表,包含客户、订单、订单行和商品。在这个例子中,一个客户可以有多个订单,但每个订单只对应一个客户;一个订单可以有多个订单行,但每个订单行只属于一个订单;每个订单行引用一个商品,而每个商品可以存在于多个订单行中。实际上,数据库要复杂得多,数据库图表可以包含更多信息,如索引、字段格式、适用的规则等。
时间管理模型——紧急与重要
可视化模型有很多种形式。紧急与重要矩阵是一个很好的可视化模型例子,它与软件没有特别的联系。它是一个管理时间和优先处理任务的好工具,可以确保你最终能够按照正确的顺序完成最重要的事情。我们经常会花太多时间在紧急但不重要的事情上,而实际上,如果提前计划好时间,这些事情就不会变得紧急,或者我们可能会把时间浪费在非紧急且不重要的事情上,而这些事情我们最好根本就不要去做。此外,这个矩阵还非常适合找出可以委托给他人的事情,即那些重要但很可能由其他人完成的事情(如果需要的话,我们可以在背后提供支持)。
卡诺模型
卡诺模型将功能分为两类:如果提供或未提供这些功能,它们会让客户感到多么满意。该理论指出,如果我们没有提供客户期望的功能(尽管他们可能没有明确表示过这种期望),那么客户将会非常失望。我们需要识别出这些功能。提供客户没有预料到的功能可能会让他们感到惊喜,而不提供这些功能则不会影响客户的满意度。这个模型是一个很好的优先级排序工具,既可以帮助你管理待办事项,也可以帮助你优先安排测试活动。
思维导图作为预测工具
我倾向于依赖的可视化模型是思维导图,我发现它对我来说是测试场景、产品需求和系统描述的完美表达方式。思维导图可以用来可视化计划和场景之间的关系,可以取代状态报告,而且最重要的是:它非常擅长定义需求、业务规则和详细的系统行为。
和所有模型一样,思维导图也有局限性,尤其是当对象开始变得复杂时。在某一时刻,它们基本上会变得太复杂而无法追踪。但公平地说,文字性文档也是如此,它们往往会变得太大而失去实用性。
我发现,思维导图有一种为信息提供结构、增加边界和上下文而几乎不产生额外负担的方法。我知道这是个人喜好的问题,但对我来说,思维导图使我的大脑能够以适当的抽象层次理解非常复杂的领域,而不会局限于单一格式,并允许我根据发现的更多信息调整和改变模型。
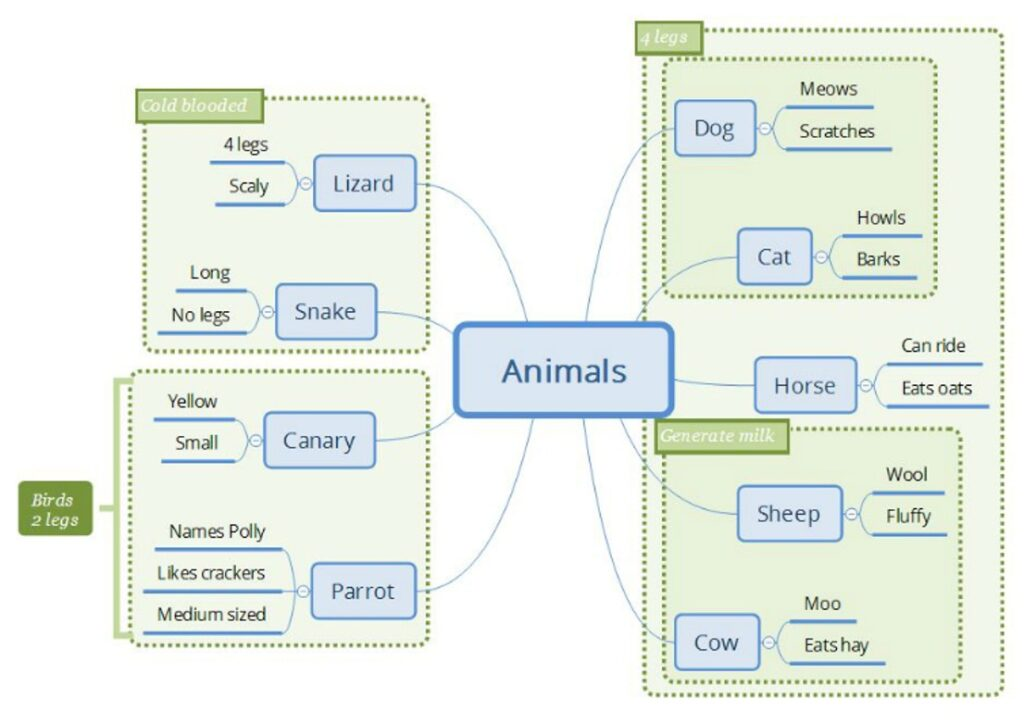
以数字方式制作思维导图最符合我的工作方式,因为我可以一边工作一边拖动和移动对象,以便更深入地进行理解。这也是一个很好的开始对话的方式,而且修改它所需的工作量很少,非常适合协作工作。
回顾我们的项目和测试负责人
我为自己设定了三个基本原则,以便让这件事变得可行:
- 从已知开始——弄清楚你知道什么,不要对未知的事情感到恐慌。
- 可实现性——我们将首先关注简单的情况(80%),如果时间允许,再增加复杂性。
- 简化——将类似的行为进行分组,并尽可能多地使用可视化元素而不是文本。
“有些事情是我们已知的已知,即我们知道自己知道的事情。我们也知道有已知的未知,也就是说,我们知道有些事情是我们不知道的。但还有未知的未知。”
——唐纳德·拉姆斯菲尔德
首先,我们试图弄清楚我们知道什么,并列出了所有我们需要更好理解的事情。
为了做到这一点,我查阅了大量的文档、数据库设计和代码。我把所有可能相关的信息,包括不同的领域、配置、业务规则等,都放入了一个巨大的思维导图中。
利用我的不同信息来源(文档、旧测试用例、代码和业务专家),我形成了一系列可以验证或证伪的假设。反复进行这个过程,直到我们都能够得到一个感觉“正确”的模型。
我们进行了分组,就共同语言达成了一致,我们获得了理解。我们从一个沮丧和紧张的团队,以及一群愤怒的用户,转变为协作并感觉像是一个有共同目标的团队。我们开始从审查转变为讨论。
作为起点,我们共同制定了一个我们认为可以实现的标准,以帕累托原则为基础。你可能以不同的名称知道这一点:80/20法则、少数关键因素法则、因素稀疏原则。该原则表明,对于许多结果来说,80%的后果来自20%的原因。这一原则由约瑟夫·M·朱兰提出,并且神奇地似乎可以适用于你试图将其放入的任何领域。
80%的错误出在20%的代码中,你的系统80%的使用量将来自20%的功能点,80%的工作可以在总时间的20%内完成,你的80%的销售额将来自20%的客户等等。我们认可在团队内部和与我们的主要利益相关者之间,首先要关注“简单事务”,如果需要,出现的复杂情况可以手动解决。
“帕累托原则——80%的效果来自20%的原因”
在工作过程中,我们取得了一些有趣的发现!我们发现许多字段和业务规则已经不再使用,有些甚至可能从未使用过。这些可以从模型、代码和数据库中删除。我们还发现需求文档、业务专家期望的工作方式和代码之间存在差异。这一点变得如此重要,以至于我们决定放弃最初的“优化和迁移”方法。最初的计划是尽可能少地更改代码,只要足以使新的SQL数据库和旧的Oracle数据库工作完全相同。在查看这些差异时,我们意识到通过修复代码中的问题(即让所需的行为与代码相匹配)可以节省时间,这反过来又使我们能够删除大量代码。例如,一个不再需要的手动调整功能。之所以构建整个功能,是因为开发人员和业务专家之间无法相互理解。
我们通过将思维导图打印在纸上,运行测试并逐一检查来进行验证测试。有了这些模型,我可以轻松地组合和重用测试用例。我通过传统的等价类和成对测试减少了我最初的组合数量。我可以在几分钟内轻松覆盖我最初的10-20个测试用例——在几天的测试中覆盖所有相关情况,并且我对测试的覆盖率感到非常自信。当我们的业务验收测试人员接手时,他们发现的错误非常少,交付工作也从一种痛苦变成了乐趣。
最后,我花了三天时间覆盖了我估计的7,188,480种组合(或者更确切地说:所有实际可能且相关的组合)。
通过使用这些可视化模型,我们在减少测试时间的同时提高了测试覆盖率。我们找到了一种更易于维护的方式来记录测试场景和需求,从而减少了误解。这增强了我们对业务的理解,并使新员工更容易上手。由于思维导图的格式不允许使用太多文字,因此你必须去除所有多余的部分,直达事物的核心。没有业务术语,没有技术术语,只有示例、图片和少量文字。你无法隐藏任何繁杂多余的内容。
总结
模型是有缺陷但有用的工具。
一图胜千言。
如果我们改变视角,勇于尝试新事物,那么不可能也会变成可能。
大胆去尝试吧,让我为你感到骄傲!
