
想象一下你有几千个测试用例在你的回归测试库中。再想象一下,你每天都要找出最佳的测试用例进行隔夜回归测试。让我们再复杂一点,假设你只能在夜间运行大约一千个测试用例。你该怎么做呢?我或许有一个解决方案。不过请注意,我只会分享这个想法的概述,并留给读者根据他们的环境灵活地应用。
测试用例的重要性
我们首先必须定义如何计算一个测试用例的重要性。对于任何给定的一天/隔夜回归,测试用例TC1是否比另一个测试用例TC2更重要?如果是,我们如何量化呢?假设每个测试用例每天根据某些属性被分配一个分数。我们如何决定哪些属性将有助于定义测试用例的重要性?
我提出了计算测试用例分数的三个关键属性,它们是:
- 历史失败分数
- 测试用例复杂性
- 缺陷暴露能力
如果你将所有测试用例的分数绘制成图表,它可能看起来像这样:
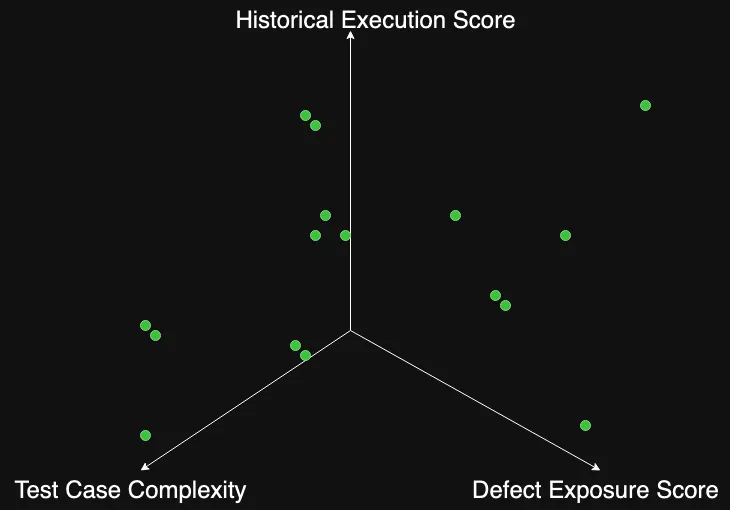
历史失败分数
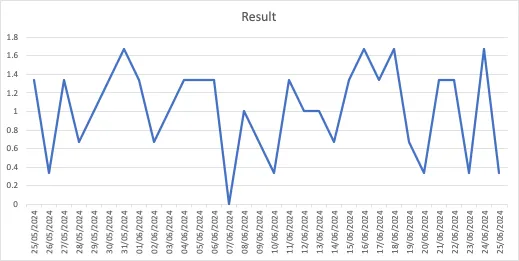
假设我们正在考虑的测试用例是回归测试用例,并且至少在过去已经执行过几次。这给了我们一个关于测试用例结果的历史趋势,即通过、失败、崩溃等。在本文中,我们将只考虑通过、失败和崩溃这三种可能的测试结果。如果我们将它们编码为整数值,即通过:0,失败:1,崩溃:2,我们可以为大多数测试用例得出其历史执行趋势的曲线。
下面是一个此类趋势的假设示例:
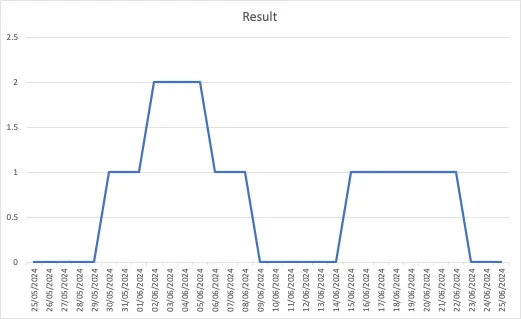
测试用例的执行历史
上面的图表来自于一个类似如下的表格数据:
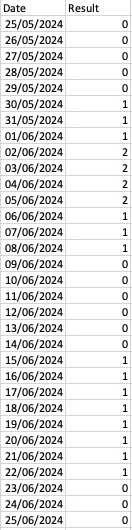
表格格式
现在,假设我们的测试用例在多个测试环境中并行执行。在这种情况下,我们可能会得到如下数据,其中我们有3个不同的测试环境执行了同一个测试用例。在这种情况下,我们可以每天对所有结果取平均值并绘制趋势线。
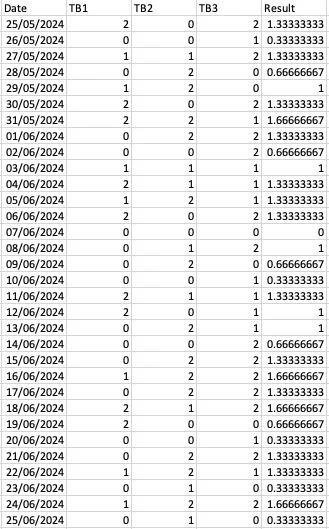
历史执行
你可能会问,为什么我们需要这个历史执行趋势?我会反问:你在这里看到什么样的数据?你看到了时间序列数据吗?是的,这当然是时间序列数据。那么,当你看到时间序列数据时,想到的显而易见的机器学习问题是什么?对我来说,是回归问题。
现在想象一下,如果你使用LSTM模型来学习测试用例的执行趋势,并预测第二天会发生什么,那将给我们一个我称之为“历史失败分数”的分数。你甚至可以称之为“历史执行分数”。例如如下所示:
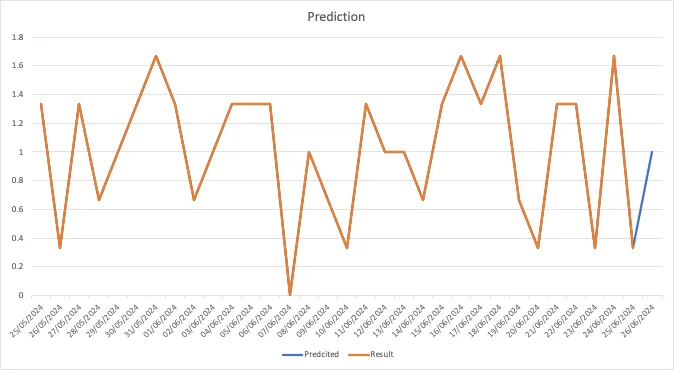
预测趋势
如果我们可能没有每个测试用例的相同数据维度(某些测试用例可能是新的或不常运行),我们为每个测试用例训练一个LSTM模型。它们是轻量级的,最多可以在2-3秒内训练完毕。
测试用例复杂性
上述讨论的历史分数不足以为测试用例打分。我们再添加一个属性来定义测试用例的复杂性。其目的在于,我们希望确保运行足够复杂的测试用例,无论它过去是否暴露过任何缺陷。我们不仅要关注过去,还要选择足够复杂的测试用例,以确保它们有潜力在未来暴露缺陷。
在计算测试用例复杂性分数时,这个话题可能显得非常模糊。我们可以通过使用工具测试测试用例的代码覆盖率来确定复杂性。例如,我使用基于测试用例配置的公式来计算复杂性分数(这取决于具体领域知识,例如通信测试)。但最终,你可以为每个测试用例定义一个复杂性分数。
缺陷暴露能力
最后,我们讨论缺陷暴露能力。这个属性的背后思路是尽可能多地捕捉与哪些代码文件对哪些测试用例有高影响相关的信息。我们有两种方法为每个测试用例计算这个分数。
- 将历史失败与文件变更进行映射:假设某个测试用例在某天失败/崩溃,并且你知道代码库中哪些文件被修改过。我们可以将失败的测试用例与变更的文件进行映射。我们建立一个矩阵,其中行表示文件,列表示测试用例,每天更新其值。例如,TC1过去失败过5次,每次失败时文件1被修改,而文件2只被修改过一次。因此,我们将文件1的TC1分数增加到5,将文件2的分数增加到1。虽然这种关联在某种程度上是盲目的,但如果你建立起历史数据,你会开始观察到真正的关联模式。当然,总会有一些异常值。例如,一个测试用例由于硬件问题失败了很长时间,但它在代码中定期修改的文件上仍然具有很高的分数。
- 将历史缺陷映射:想象一下,你的团队曾经修复了一个bug,并使用TC1来验证他们的修复。我们能不能将修复该缺陷时代码中更改的文件与用于验证该修复的测试用例进行映射呢?这为我们提供了代码文件与测试用例的直接关联。
我们希望得到一个类似于下面的矩阵:
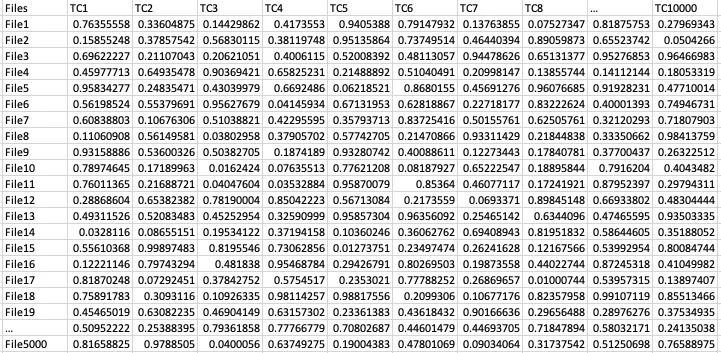
File VS TC
每天,当你需要进行隔夜回归测试时,你可以通过git检查今天回归标签下修改了哪些文件,过滤出这些文件,并在上面的数据框/矩阵中加总每个测试用例的分数,从而得到一个缺陷暴露分数。这个分数告诉我们对于今天修改的文件,哪个测试用例最有可能暴露缺陷或最有可能失败/崩溃。
测试用例分数
最后,每天我们处理数据来计算所有三个不同的分数,并为每个测试用例得出最终的测试用例分数。我将这一点留给读者自己去尝试不同的方法,因为我发现简单的所有三项值的加总对我有效。对于某些人来说,可能使用加权总和会有帮助,例如他们希望对缺陷暴露分数或复杂性分数赋予更多权重。
将测试用例按从高到低的分数排序,你将得到优先排序的测试用例列表,用于隔夜回归测试。由于历史执行分数和缺陷暴露分数中的两个属性可能每天都会改变,因此这个列表会每天动态变化。
结论
在当前敏捷的工作方式中,测试用例的优先级划分不应是静态的。通过应用上述的思路,你可以得到一个动态的测试用例优先级列表,从而提供更好的测试并避免缺陷的漏检。
