
在测试自动化中,干净的代码是一个有争议的话题。网上有很多关于这个的不同意见。干净代码本身就在开发人员中引发了许多讨论。有一些一般规则,开发人员通常会遵循。这些规则被收录在罗伯特·“Uncle Bob”·马丁所著的《Clean Code》一书中。这本书非常全面,其中大部分建议在测试自动化中也适用。不幸的是,测试自动化常常因缺乏对干净代码在测试中的重要性理解而受到不良编码实践的困扰。由于测试自动化工程师的广泛流入,快速生产测试的需要常常牺牲了编写干净代码的实践。QA工程师的工作进度往往滞后,因此不得不走捷径以完成所有工作。而干净代码的意义远不止是“美观”。
干净代码的好处
当我们编写杂乱的代码时,即使是作者本人也很难维护或调试它。我们应该始终致力于让代码更容易理解。阅读者应该能够仅通过查看方法、类和变量的名称来理解代码的意图。在团队中工作时,这也是一个很好的理由让我们编写干净的代码,因为我们的同事可能无法理解我们在这段代码中想要实现的意图。
有时,当某个功能没有适当的文档时,了解它如何工作的唯一方法就是阅读代码。如果代码杂乱无章,开发人员在试图理解其工作原理时会浪费更多时间。
对于经验丰富的软件工程师来说,花费60%以上的工作时间浏览代码是很常见的。在修复bug之前,他们会先通过静态代码分析或调试来阅读代码。如果代码干净,他们就不会遇到理解和找到问题根源的困难。否则,他们只会浪费时间绕圈子。同样的逻辑也适用于需要维护和调试的测试自动化逻辑。
命名约定
代码中的所有名称,无论是函数、类还是变量,都必须具有有意义。函数应使用动词命名,而类应使用名词。这不言自明,名称中不应该有拼写错误。根据使用的语言,它们应该以小写或大写字母开头,并在整个代码中保持一致的模式。缩写名称应以大写字母开头,其他字母为小写。
let a = 4; // 不好
let circleRadius = 4; // 好
function readPdfFile() // 好
function readPDFFile() // 不好
函数名称应显示意图,以便阅读者无需阅读代码即可理解函数的目的。应避免重复明显的信息。
// 不好
class User {
string UserAddress;
string UserName;
string UserPhone;
}
// 好
class User {
string Address;
string Name;
string Phone;
}
不要因为名称过长而困扰。一些名称本身可能较长,尽管看起来有些尴尬,但如果没有更好的方式描述函数,这就不成问题。可能在以后你会想到一个更好的名字,这完全没问题。类、方法、属性和变量的名称是可以重构的。返回布尔值的函数名称通常以is、are、does等开头。避免创建语法不正确的函数名称。
// 好
isValid()
isEnabled()
hasAttribute()
// 不好
isContainsNumber()
函数应该只做一件事
这源于编程的SOLID原则,我们会在其他时候详细讨论它。这是该原则中的第一个,即单一责任原则(SRP) ,它指出类和函数应该只有一个责任。对于类来说,如果你遵循页面对象模型(Page Object Model) ,这个问题相对简单,因为它不会破坏SRP。
那么函数呢?如何知道自己做得太多了?如果你遵循上述原则,为函数命名赋予有意义的名称,并且发现需要在函数名中使用“和(and) ”时,就说明你已经做得太多了。例如,如果有一个名为isEnabledAndVisible的函数,这显然违反了SRP原则。
测试也应该遵循类似的逻辑。许多断言框架不允许在测试中包含多个断言。实际上,你可以放置多个断言,但当第一个断言失败时,其余的测试将不会执行。测试应该只测试一个功能。
当然,这条规则也有例外。例如,输入一个值到字段中并发送回车键以移除焦点,这种函数可能被称为inputTextAndEnter。这种例外情况需要一定的经验来判断何时使用。
DRY 或 WET 代码
这两个原则实际上代表着是否允许代码重复的永恒争论。DRY(Don't Repeat Yourself)意味着“不要重复自己”,而WET(Write Everything Twice)则表示“把一切写两次”。DRY的含义显而易见,而WET通常意味着重复两次是可以接受的,但如果需要第三次,则需要将代码提取到一个单独的函数中。显然,这也需要经验的积累。有些代码可以故意重复。例如,如果有两个函数的部分代码相同,但我们知道其中一个函数的逻辑会更改,我们不会将其提取为一个单独的函数。
重构复杂函数
大型函数应分解为易读和易维护的结构。一个很好的例子是日期选择器函数,我们用来在特定控件中选择日、月和年。这个函数可能需要处理多个下拉列表来选择年份和月份,最终选择日期。我们可以将所有这些写在一个函数中,但这可能会使代码难以阅读。
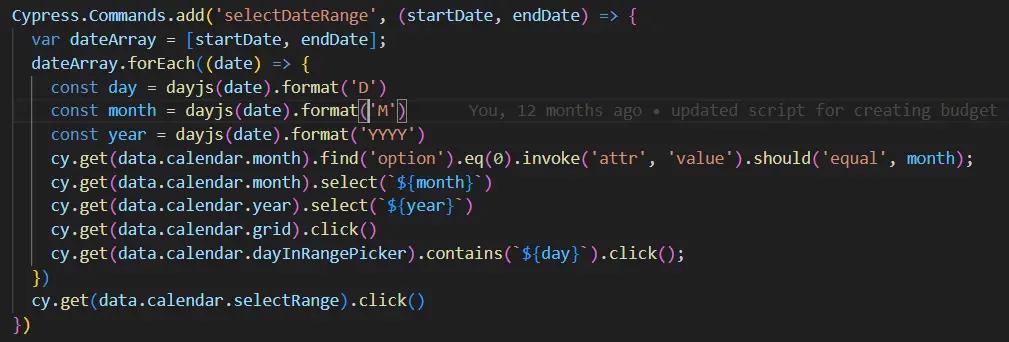
或者,我们可以将每个操作分离到一个特定的函数中。这样会增加代码量,但其结构更好、更易于理解。
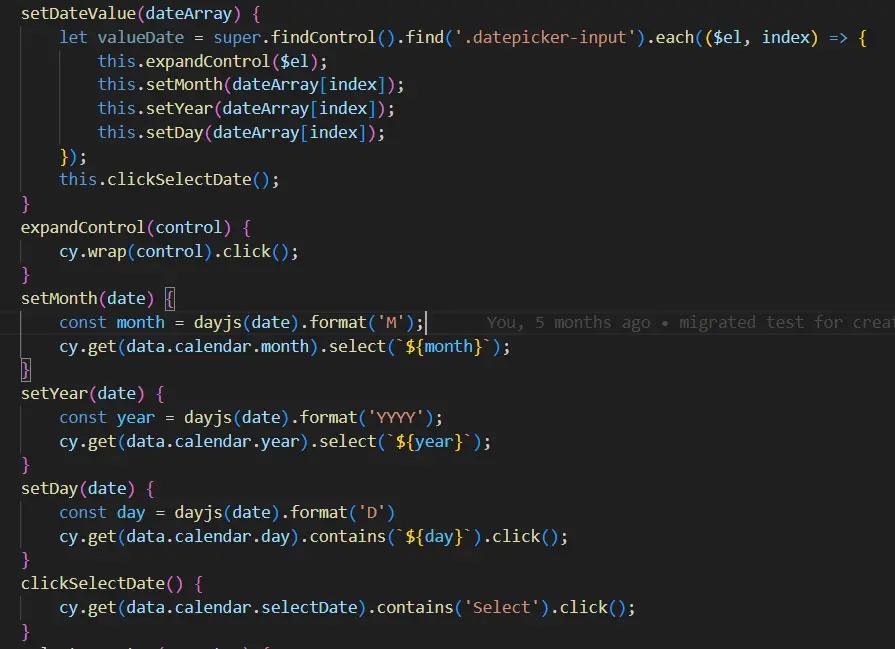
代码更多,但当它被这样分割时,组织更好,更易于理解。
测试应该是独立的
测试不应彼此依赖。测试的成功或失败不应取决于其他测试的动作或缺少动作。在测试套件执行时,其执行顺序不应重要。测试不应依赖于它们在何种浏览器中执行。
断言消息必须具有描述性
并不是所有断言库都支持添加自定义失败消息,但对于那些支持的库,记住为每个断言提供特定的失败消息。为多个断言使用相同的消息不会帮助你找到代码中的失败断言。另一方面,如果有唯一的断言消息,你可以简单地从日志中获取消息并搜索,就能很快找到失败的断言。
等待机制的合理实现
随着Cypress和Playwright的出现,人们不再过多关注等待。两者都有自动等待的功能,虽然偶尔仍需要调用等待函数。显式超时在任何地方都不是一个好主意。Cypress提供了等待请求完成的选项,这是一个不错的功能。

Playwright有类似的功能,比如WaitForURL(Playwright团队应该阅读这篇文章,关于函数命名的部分)。

此外,Playwright和Cypress都提供了可配置的超时来查找元素。你可以指定工具在抛出NoSuchElementException之前等待元素的时间。你可以在Playwright和Cypress各自的文档中了解更多相关信息。另外,你还可以像Playwright文档中解释的那样,等待元素的特定状态。
相比之下,Selenium有其众所周知的等待机制。隐式等待会影响整个测试套件,并可能在不经意间更改所有测试的超时时间。使用Thread.Sleep被认为是不良实践,尽管在某些情况下别无选择时可能不得不使用。关于Selenium等待的更多内容,你可以在这篇优秀的文章中找到。
将数据与测试分离
理想情况下,你希望测试能够使用唯一的数据。不要使用硬编码数据,因为某些数据库限制,也不要将敏感数据存储在测试中。你需要在一个地方管理数据,以便当数据发生变化时,可以快速更新并影响所有测试。你可以使用随机函数、外部文件存储数据,或者在某些情况下使用环境变量。通常需要结合多种方法。
结论
编写干净的代码就像是在投资未来的时间。现在编写干净的代码,可以减少未来阅读和理解代码所花费的时间。编写代码并不难,编译器和解释器会理解你写的代码。问题在于你的同事可能无法理解它。测试自动化中的干净代码与其他代码规则并无不同,只是在不同的上下文中应用这些规则,目的是相同的。上述文章并不详尽,还有许多其他的规则被遗漏了,有些规则将在其他时间讨论。
