在性能测试过程中,是否具备诊断分析以及调优能力是衡量一个性能测试人员水平高低的标准之一,而掌握了诊断分析是能否找到性能瓶颈的决定性环节。
本文将介绍完整的性能测试报告总结需要哪些指标及该如何去分析?
1 性能测试常用指标概念
1.1 并发用户
· 概念
并发用户是指同一时刻对系统进行访问的多用户,必须注意是同时且多用户。这些用户的最大特征是和服务器产生了交互,这种交互既可以是单向的传输数据,也可以是双向的传送数据。
· 并发用户数性能监控的指标
并发用户数是衡量一个系统性能是否达标的一个重要指标。并发用户数越大,则系统承受的压力也就越大。并发用户数是通过业务量大小来进行评估的。
并发用户数公式:TPS*响应时间。并发用户数作为系统能力的参考,但是不能作为指标,因为从公式上可以看出影响并发用户数的有响应时间。
1.2 响应时间
· 概念
响应时间是指从客户端发一个请求开始计时,到客户端接收到从服务器端返回的响应结果结束所经历的时间。
广义的响应时间(包含服务端处理时间、路径传输时间和终端处理时间的总和):用户发起交易请求指令(如在界面上点击交易请求按扭开始),到交易成功(如在界面上看到交易成功的提示信息或直接进入下一步操作)截止所花费的时间。
· 并发用户数性能监控的指标:
Ø 90%响应时间
把事务每次运行的响应时间从小到大排序,其中90%的请求的响应时间都在这个范围之内
Ø 平均响应时间
事务运行时间总和除以运行次数,得出来的事务平均响应时间
Ø 最大响应时间
事务运行中,最大一次运行所需的时间作为该事务的最大响应时间
Ø 最小响应时间
事务运行中,最小一次运行所需的时间作为该事务的最小响应时间
1.3 TPS
PS每秒钟系统能够处理的交易或事务的数量,它是衡量系统处理能力的重要指标。TPS是重要的性能参数指标。
不同行业不同业务可接受的TPS也是不一样的。一般互联网电子商务为10000TPS-100000TPS;互联网小型网站50TPS-100TPS;互联网中型网站100TPS-1000TPS。
1.4 吞吐量
吞吐量(Throughput)指在一次性能测试过程中网络上传输的数据量的总和。
对于交互式应用来说,吞吐量指标反映的是服务器承受的压力,在容量规划的测试中,吞吐量是一个重点关注的指标,因为它能够说明系统级别的负载能力。
1.5 思考时间
思考时间是指模拟正式用户在实际操作时的停顿间隔时间。
从业务的角度来讲,思考时间指的是用户在进行操作时,每个请求之间的间隔时间。
在测试脚本中,思考时间体现为脚本中两个请求语句之间的间隔时间。
1.6 CPU
查看性能测试的过程中CPU资源的占用率,反映系统处理能力以及应用是否稳定。
1.7 I/O
磁盘的使用情况,度量磁盘读写性能。
1.8 内存
查看内存使用情况。
1.9 调用链
调用链跟踪、记录业务的调用过程,可视化地还原业务请求在分布式系统中的执行轨迹和状态,用于性能及故障快速定界。下图所示是在华为云APM拓扑图发现异常后查询调用链追踪异常的过程:

2 性能标准参考
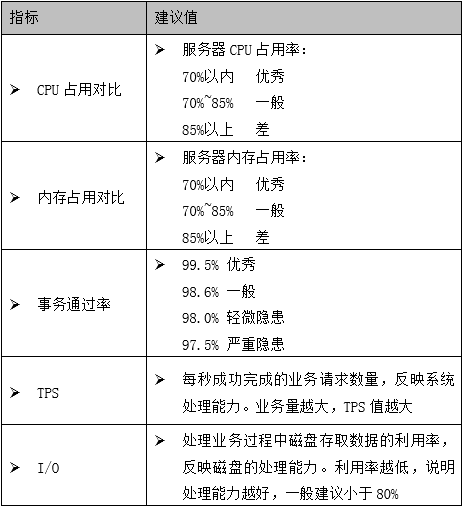
3 测试报告分析
华为云性能测试服务为用户提供专业性能测试报告,包括事务并发、TPS、吞吐量、响应时延、资源使用、调用链跟踪等多维度统计。测试报告有在线和离线两种,用户可以在无人值守的情况下完成测试后查看离线报告,内容与实时报告一致。
下面将华为云性能测试服务作为本次的测试工具,当测试任务结束后提供的报告进行分析。
1. 统计维度:报告的TPS,时延、并发等统计维度均为事务,如事务中有请求多个报文,只有在多个请求报文均正常返回会认为成功,时延也是多个请求报文的求和值
2. 响应超时:出现该情况下是在设置的响应超时时间内(默认5S),对应的TCP连接中没有响应数据返回,会将本次事务请求统计为响应超时。
存在部分响应超时:
a) 服务器繁忙,如某个服务节点CPU利用率高
b) 网络IO超过VM/EIP带宽
c) 等待后端微服务、数据库的超时时间设置过长
运行一段时间后全部响应超时或者检查点校验不通过:
a) 大压力导致系统中某个微服务奔溃
b) 后端数据库无响应
3. 比对失败:从服务器返回的响应报文不符合预期(针对HTTP/HTTPS默认的预期响应码为200),比如服务器返回404,502等。出现原因一般为高并发情况下被测服务无法正常处理导致的,如果分布式系统中数据库出现瓶颈、后端应用返回错误等
4. 解析失败:响应报文已全部接收完成,但是部分报文丢失导致整个事务响应不完整,这种情况一般需要考虑网络丢包
5. 带宽统计:报告统计的是性能测试服务执行端的业务数据包带宽,上行表示从性能测试服务发出的流量,下线表示接受到的流量。如果是外网压测场景,您需要关注执行机的EIP带宽是否可以满足上行带宽的要求。而下行带宽需要关注单台执行机是否超过1GB
6. TPS与并发用户及时延的关系:TPS是指云性能测试服务在统计周期内每秒从被测服务器获取到的响应事务实时统计,TPS=并发用户/平均响应时延。
TPS未随着并发数增长而上升:
a) 系统性能到达瓶颈,持续并发加压过程中响应时延增加(可观察响应区间统计)
b) 可通过进一步加压是否会出现非正常响应验证
7. 如何判断被测应用优劣:根据应用本身定义的服务质量定义,最佳状态是没有任何响应失败、比对失败的情况,如果有,需要在服务质量定义范围之内,通常情况下不超过1%,同时响应时延越低越好(2S内体验较好,5S内可以接受,超过5S则需要考虑优化),TP90,TP99指标可以客观反映出90%,99%用户的体验时延
TP90响应时延较短,TP99时延高:
a) 系统性能接近瓶颈
b) 可通过进一步加压是否会出现非正常响应验证
4 通用优化建议
1) 扩容,链路中的某一应用可能出现cpu使用率较高或者连接池资源不够用(rpc、jdbc、redis连接池等)但本身对于拿到连接的请求处理又很快,这一类需要横向扩展资源。
2) 应用逻辑优化,比如存在慢sql、 逻辑的不合理如调用db或者redis次数过多、没有做读写分离造成写库压力过大。
3) 超时时间的合理设置,对于应用之间的rpc调用或者应用与其他基础组件之间的调用,均需要设置合理的超时时间,否则过长的等待将造成整个链路的故障。
4) 缓存的应用,请求尽可能从前端返回,而不是每一个都要让后端应用处理后再返回,减轻后端应用及数据库压力,提高系统吞吐能力。
5) 限流,对于超出承载能力的QPS或并发,可以进行拦截并直接返回提示页面。
6) 降级,对于非核心链路上的应用,允许故障关闭而不影响核心链路
7) 扩容和优化也是有限度的,在评估容量内,保障核心交易链路正常是重中之重,对于非核心功能模块考虑降级场景
华为云性能测试服务CPTS:https://www.huaweicloud.com/product/cpts.html
福利:
· 华为云性能测试服务免费使用至2018年12月31日,免费使用的VUM数量不限;最大并发用户数10万
· 50个并发用户数永久免费

