
许祥的阅读
重试Android测试并在运行之间清除数据库

引言当各路高手还在为“该禁用不稳定的测试代码还是重试它们”争论不休时,我想直接给你们展示如何实现后者。此方法专供勇士——后果自负哦!实现重试策略我们先创建两个类:Retry-用于重试任意特定测试代码RetryRule-负责整个测试套件的重试逻辑importorg.junit.rules.TestRuleimportorg.junit.runner.Descriptionimportorg.ju
3°/
1 天前/34 人阅读 / 0 人点赞
/ 0 条评论
如何真正实现测试左移

交付速度不应受测试团队处理能力的限制!我们渴望比竞争对手更快交付,渴望加速产品上市;但质量同样至关重要。若要鱼和熊掌兼得,团队应致力于:并行开展开发活动(而非串行作业)。减少缺陷带来的过程损耗。在流程每个环节实施恰当的质量保障措施。目前一些专职测试团队作为"缺陷捕捉者"模式的致命缺陷——当测试成为交付瓶颈时,公司的交付能力将完全受制于测试团队的吞吐量。最糟糕的实践莫过于设立显式的"测试阶段",
3°/
1 天前/35 人阅读 / 0 人点赞
/ 0 条评论
你的自动化测试真的实现自动化了吗

让我给你们讲个小故事。我曾拜访过一位客户,他们对自动化测试的热情高涨。“哦,我们有很多10倍速的测试过程!”他们自豪地说。出于好奇,我追问:“你们怎么运行它们呢?”他们毫不犹豫地指向办公室角落里一台落满灰尘的旧电脑。我愣了一秒,怀疑自己是不是听错了。角落里的电脑?没错,原来那就是他们“运行”测试的地方。如果说这都不算自动化名不副实,那我真不知该说什么了。那么,如何判断你的自动化测试是真正为你服
3°/
1 天前/38 人阅读 / 0 人点赞
/ 0 条评论
为何视觉测试对移动应用质量至关重要

您是否曾经发布过存在界面问题的应用程序?在当今快节奏的发展背景下,这种情况变得愈发频繁——即便对那些有专门的人工QA和自动化UI测试人员的团队也是如此。我们常低估UI(用户界面)问题的重要性。但这些问题远不只是按钮错位那么简单。许多UI缺陷会导致应用无法正常使用,例如:文本色差导致可读性不足不完善的UI损害品牌可信度负面评价导致下载量下滑但是等一下......我已经做过了UI测试啊。即使您有U
3°/
1 天前/32 人阅读 / 0 人点赞
/ 0 条评论
质量计划的基本要素4

《在每一步中嵌入质量——从测试到持续改进》——博客系列第四部分我们已涵盖的内容及后续内容到目前为止,我们已经探讨了可靠质量计划的基础要素、设计方案与文档管理、风险和依赖关系,以及最小可行产品(MVP)和故事映射。现在,我们将进入项目质量的下几个关键支柱:明确测试责任——确定由谁在何时测试什么内容,以确保对所有测试类型都有明确的责任归属。测试左移——在开发早期就集成测试,以便在问题易于解决且成本
3°/
1 天前/31 人阅读 / 0 人点赞
/ 0 条评论
质量计划的基本要素3

《避免过度构建——最小可行产品(MVP)和故事映射如何让你保持专注》——博客系列第三部分我们已涵盖的内容及后续内容在第二部分中,我们通过确保利益相关者的参与、明确且可执行的需求、可行的设计方案、结构化的文档记录、主动的依赖关系管理,以及运用ROAM方法尽早识别风险,奠定了坚实的质量基础。在第三部分,我们将在此基础上探索先进的质量实践方法,这些方法将推动项目的持续改进并助力项目取得长期成功。最小
1°/
1 天前/19 人阅读 / 0 人点赞
/ 0 条评论
质量计划的基本要素2

《设计、文档与规避灾难》——博客系列第二部分我们已涵盖的内容及后续内容到目前为止,我们已经探讨了一个可靠质量计划的基础内容——识别利益相关者、收集和管理需求,以及确保非功能性需求符合SMART原则且切实可行。现在,你应该已经掌握了从项目一开始就掌控IT项目的方法,并且能够避免诸如范围蔓延和职责不明确等常见陷阱。现在,我们将进入项目质量的下几个关键支柱:设计——确保技术设计和用户体验(UX)设计
2°/
1 天前/23 人阅读 / 0 人点赞
/ 0 条评论
质量计划的基本要素1

《并非附注,而是核心重点:质量计划如何推动你的IT项目》——博客系列第一部分为什么要使用质量计划?曾以任何角色参与过IT项目的人都深知其中的挑战。项目启动时,你有着宏伟的计划、热情高涨的利益相关者,以及无数的好点子。但随着截止日期的临近,你会发现需求出现偏差,风险突然变成现实,或者测试过程陷入困境,导致问题发现得太晚。结果如何呢?交付延迟,团队沮丧,利益相关者则在疑惑他们的投资都花到哪里去了。
3°/
1 天前/32 人阅读 / 0 人点赞
/ 0 条评论
测试与评估大型语言模型(LLMs):关键指标与最佳实践(第二部分)
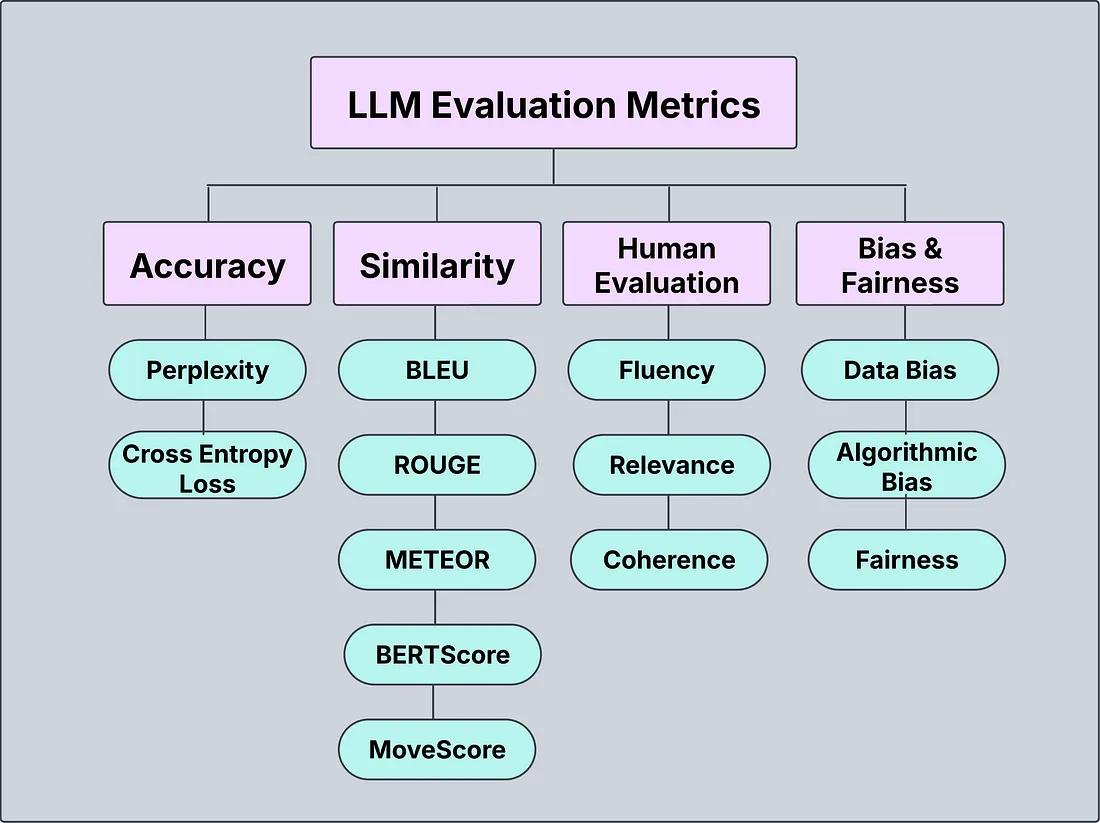
测试与评估大型语言模型(LLMs):关键指标与最佳实践(第二部分)作者/译者:SumitSoman/溜的一比文章来源:Mediam文章地址:https://medium.com/@sumit.somanchd/testing-evaluating-large-language-models-llms-key-metrics-and-best-practices-part-2-0ac7092c977
4°/
1 天前/44 人阅读 / 0 人点赞
/ 0 条评论
测试与评估大型语言模型(LLMs):关键指标与最佳实践(第三部分)
欢迎来到我们关于“测试与评估大型语言模型(LLMs):关键指标与最佳实践”博客系列的第三部分。在前两部分中,我们探讨了一系列评估指标,包括相似性、流畅性、连贯性、相关性、人类评估以及偏差与公平性。我们还介绍了一些最广泛使用的LLM评估工具和框架,提供了如何评估这些模型和聊天机器人性能的全面理解。第1部分和第2部分。在这一最终部分中,我们将深入探讨LLM评估的最佳实践、该领域面临的问题以及测试和改进
2°/
1 天前/25 人阅读 / 0 人点赞
/ 0 条评论