
许祥的阅读
测试与评估大型语言模型(LLMs):关键指标与最佳实践(第一部分)


大型语言模型(LLMs)彻底改变了自然语言处理(NLP),推动了文本生成、摘要、翻译等应用的发展。然而,评估其有效性仍然是一个挑战,因为其性能受多个因素影响,包括连贯性、流畅性、准确性和公平性。本博客深入介绍了LLM评估指标,讨论了其重要性、最佳实践和实际应用。为什么评估指标很重要?LLM评估对于以下方面至关重要:确保模型准确性:验证响应是否符合用户期望。检测偏差:识别和减轻意外偏差。提高性能
3°/
1 天前/39 人阅读 / 0 人点赞
/ 0 条评论
我是如何在 5 天内为 Confident AI 筹集 220 万美元种子轮融资的

今天,我自豪地宣布ConfidentAI超额完成了220万美元的种子轮融资,参与方包括YCombinator、FlexCapital、OliverJung、VermilionCliffsVentures、Liquid2Ventures、JanuaryCapital以及RebelFund。对于投资者对我们开源LLM评测方法的信任,我的联合创始人Kritin和我心怀无限感激。但这篇文章无关金钱,也
3°/
1 天前/32 人阅读 / 0 人点赞
/ 0 条评论
全面LLM安全指南:解读 AI 法规与LLM安全最佳实践
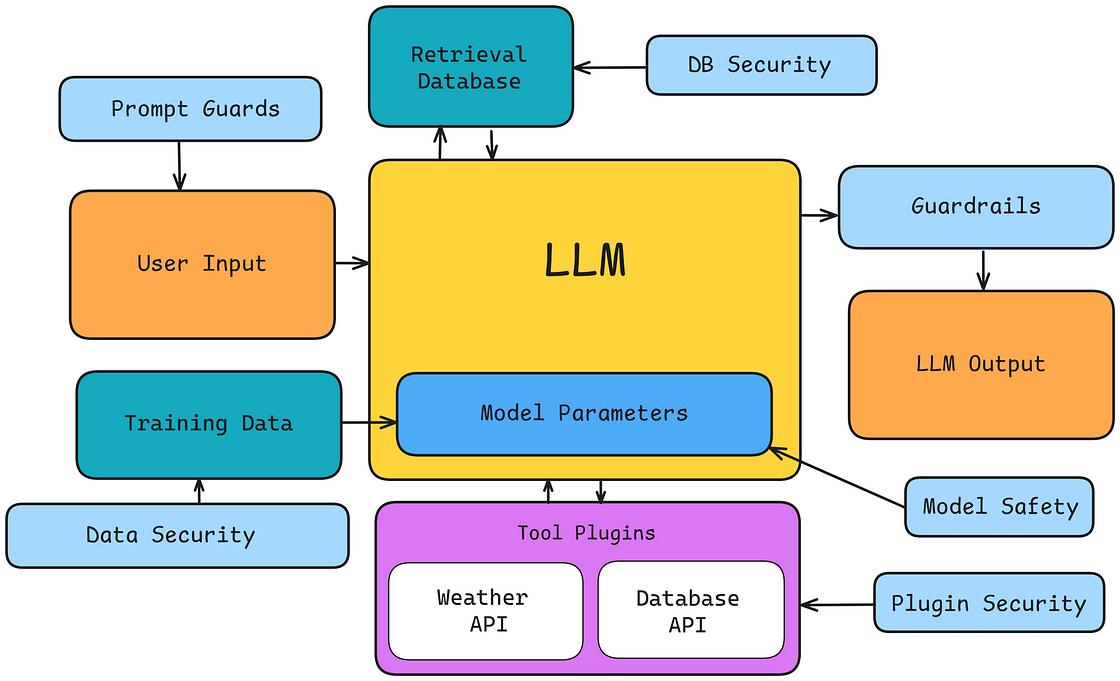
能力越大,责任越大。随着LLMs日益强大,它们被赋予更多自主权。这意味着人工监督减少、个人数据接触增多,以及在处理现实任务中扮演的角色不断扩大。从管理每周杂货订单到监督复杂的投资组合,LLMs对渴望利用它们的黑客和恶意行为者构成了诱人目标。忽视这些风险可能带来严重的伦理、法律及财务后果。作为该技术的先驱,我们有责任优先考虑并维护LLM安全。尽管这片领域大多未经探索,但并非完全是个黑箱。全球各国政府
2°/
1 天前/29 人阅读 / 0 人点赞
/ 0 条评论
OWASP 2025 年LLM应用十大安全风险:风险预测与缓解技术

想到2025年将是LLM智能体之年,而现状却令人不寒而栗…LLMs对越狱攻击的防御依然脆弱得可笑。诚然,DeepSeek几周前发布时在AI界掀起巨浪,我也承认它确实强大得惊人。但这位X平台用户仅用简单的提示词注入就轻易生成了冰毒配方。X用户利用DeepSeek生成冰毒配方(来源:X.com)现在想象一下,将这些相同的LLMs接入我们日常使用的医疗工具、法律系统和金融服务中。我是不是忘了提,
3°/
1 天前/36 人阅读 / 0 人点赞
/ 0 条评论
LLM 数据泄露、提示注入等多重防护机制

无论你是管理敏感用户数据、避免有害输出,还是确保符合监管标准,构建恰当的LLM防护机制对于安全、可扩展的大型语言模型(LLM)应用至关重要。防护机制具有前瞻性和规范性——旨在处理边缘情况、限制故障并维护实时系统的信任。建立坚实的防护机制基础,确保你的LLM不仅在理论上表现优异,更能安全高效地在用户手中发挥作用。虽然LLM评测侧重于提升准确性、相关性和整体功能性,但实施有效的LLM防护机制则是为
1°/
1 天前/19 人阅读 / 0 人点赞
/ 0 条评论
2025 年大众评选的顶级LLM评测工具

直入主题吧。市面上有大量LLM评测工具,它们看起来、用起来、听起来都大同小异。“自信交付你的LLM”、“告别LLMs的猜测游戏”,说得轻巧。为何如此?原来,LLM评测是每个构建LLM应用的人都会面临的难题,而且确实令人头疼。LLM从业者依赖“氛围检查”、“直觉”、“第六感”,甚至不得不“编造测试结果让经理满意”。因此,市面上已有大量高质量的LLM评测解决方案供过于求。作为DeepEval—这个
3°/
1 天前/37 人阅读 / 0 人点赞
/ 0 条评论
轻松入门LLM评测

大多数开发者构建LLM应用时并未设置自动评测流程——即便这可能引入未被察觉的破坏性变更,因为评测本身极具挑战性。本文中,你将学习如何正确评测LLM输出。目录LLM是什么?为何评测如此困难?用Python评测LLM输出的不同方法如何使用DeepEval评测LLMLLM是什么?为何评测如此困难?要理解LLM为何难以评测且常被称为“黑箱”,需先拆解其本质与运作原理。以GPT-4为例,这个大型语言模型
2°/
1 天前/25 人阅读 / 0 人点赞
/ 0 条评论
自动化测试工具集锦
Java测试自动化一个关于Java测试自动化框架、工具、库和软件的综合精心整理的列表,帮助软件工程师在Java上轻松启动测试自动化。由SDCLabs赞助。如果有问题/想法/疑问,可以加入这里的聊天讨论:https://gitter.im/atinfo/awesome-test-automation目录xUnit框架TDD/ATDD/BDD模型驱动测试(Model-BasedTesting)代码分析
3°/
1 天前/33 人阅读 / 0 人点赞
/ 0 条评论
用大语言模型生成合成数据

"用AI凭空生成数据"的能力听起来美好得令人难以置信——想想看,你无需手动收集、清洗和标注海量数据集就能获得优质数据。但正如预期,合成数据并非没有缺陷。尽管其具备便捷性、高效性和成本优势,但合成数据的质量完全取决于生成方法的选择:若采用简陋的生成技术,最终将得到无法有效反映现实数据的低质量数据集。在本文中,我将分享ConfidentAI如何生成逼真的文本合成数据。让我们直接进入主题。什么是合成
2°/
1 天前/28 人阅读 / 0 人点赞
/ 0 条评论
现在是2025年,停止使用快照测试!

我记得快照测试刚出现时的情景,那时是Enzyme的时代。它是最新的酷技术,许多人纷纷开始在他们的React应用程序中广泛使用它。从表面上看,快照测试似乎提供了很多好处,但在我看来,它们只是前端的一时风潮,其使用方式并没有被充分理解。在许多情况下,它们实际上降低了应用程序的测试质量……现在已经是2025年了,我仍然看到一些例子,快照测试仍然是应用程序组件测试覆盖率的一个重要部分。以下是我认为快照
3°/
1 天前/31 人阅读 / 0 人点赞
/ 0 条评论