

直入主题吧。市面上有大量LLM评测工具,它们看起来、用起来、听起来都大同小异。“自信交付你的LLM”、“告别LLMs的猜测游戏”,说得轻巧。
为何如此?原来,LLM评测是每个构建LLM应用的人都会面临的难题,而且确实令人头疼。LLM从业者依赖“氛围检查”、“直觉”、“第六感”,甚至不得不“编造测试结果让经理满意”。
因此,市面上已有大量高质量的LLM评测解决方案供过于求。作为 DeepEval —这个月下载量近 50 万的开源LLM评测框架的作者,我有责任根据优缺点,向大家揭示人们心目中顶级的LLM评测工具选择。
但在我们揭晓前五名榜单之前,先来回顾一下基础知识。
为何你应该认真对待LLM评测?
你将会或已经遇到这样一个常见情景:你开发了一个能自动化 X%现有繁琐手动工作流的LLM应用程序,无论是自用还是为客户,结果却发现其表现不如预期。沮丧之余,你自问:现在该怎么办?你的LLM应用未能达到期望,原因无非两种——毕竟,你看到别人构建的类似应用似乎运行良好。你的LLM应用要么:
- 永远无法做到你认为它能做到的事
- 有变得更好的潜力
我今天来是为了教你最优化的LLM评测流程,以最大化你的LLM应用程序的潜力。
完美的LLM评测工具
LLM评测是对LLM应用进行基准测试的过程,以便进行比较、迭代和改进。因此,理想的LLM评测工具将最高效地支持这一流程,并助你最大化LLM系统的性能表现。
理想的LLM评测工具必须具备:
- 拥有准确可靠的LLM评测指标。没有这一点,不如回家小憩。不仅需要号称精准的指标,更要避免那些隐藏在 API 壁垒后的模糊标准——你需要的是经过验证、久经考验且广受好评的指标。
- 提供快速识别改进与退步的方法。毕竟,若无法明确方向,迭代优化又从何谈起?
- 具备在统一中心位置管理和维护评测数据集的能力,这些数据集用于测试你的LLM应用程序。这对于依赖领域专家标注评测数据集的LLM从业者尤为重要,否则反馈循环将不畅,评测数据质量也会受损。
- 能够帮助你识别生产环境中生成的LLM响应质量。这一点至关重要,因为你需要:a) 监控不同模型和提示在真实场景中的表现,b) 将不满意的LLM输出加入数据集,以逐步优化测试数据。
- 能够整合人类反馈以改进系统。这些反馈可以来自终端用户,也可以是团队内部的意见。
记住,优秀的LLM评测 == 指标质量 x 数据集质量,因此要将其置于首位。话虽如此,让我们来谈谈在这方面表现最佳的 5 大工具。
1. Confident AI
Confident AI 位居榜首的原因很简单:它拥有当前最优秀的LLM评测指标支持,并提供了最流畅的工作流程,用于长期优化和提升评测数据集的质量。该平台提供了必要的基础设施,既能识别你的LLM应用需要改进之处,也能在部署前捕捉到性能退化问题,使其成为市场上领先的LLM评测解决方案。
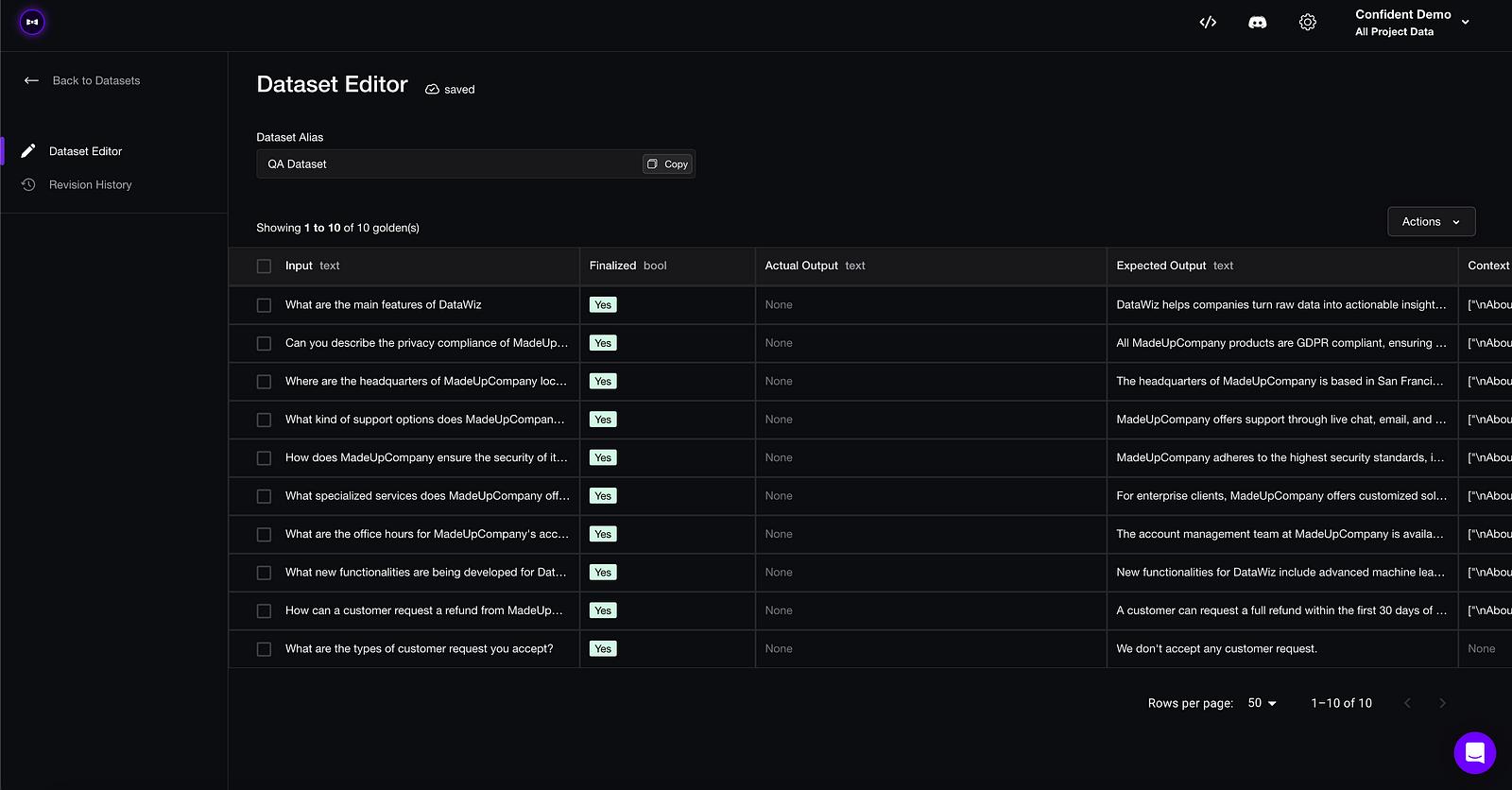
Domain experts can edit datasets on the platform
与其他工具不同,其评测指标由 DeepEval 驱动,这是一款开源工具,已执行超过 2000 万次评测,月下载量超过 40 万次,覆盖范围从 RAG、智能体到对话系统无所不包。其运作方式如下:
与其他工具不同,其评测指标由 DeepEval 驱动,这是一款开源工具,已执行超过 2000 万次评测,月下载量超过 40 万次,覆盖范围从 RAG、智能体到对话系统无所不包。其运作方式如下:
- 上传一个评测数据集,包含约 10 至 100 组输入与预期输出配对,非技术领域的专家可在平台上进行标注和编辑。
- 选择你的评测指标(涵盖所有用例)。
- 从云端拉取数据集,并为你的数据集生成LLM输出。
- 进行评测。
每次更新提示、模型或其他内容时,只需重新运行评测即可对更新后的LLM系统进行基准测试。操作如下:
pip install deepeval
from deepeval import evaluate
from deepeval.metrics import AnswerRelevancy
from deepeval.dataset import EvaluationDataset
dataset = EvaluationDataset()
# supply your alias
dataset.pull(alias="My Dataset")
# testing reports will be on Confident AI automatically
evaluate(dataset, metrics=[AnswerRelevancy()])
如果一开始没有评测数据集,只需:
- 选择你的指标并开启LLM监控功能
- 开始在生产环境中监控/追踪LLM的响应
- 根据指标分数筛选不满意的LLM响应,并据此创建数据集。
最棒的部分?它拥有极佳的开发者体验(相信我,早期我收到了大量关于改进开发者流程的尖锐反馈),并且可以立即免费使用。亲自试试吧,只需花费你 20 分钟时间:
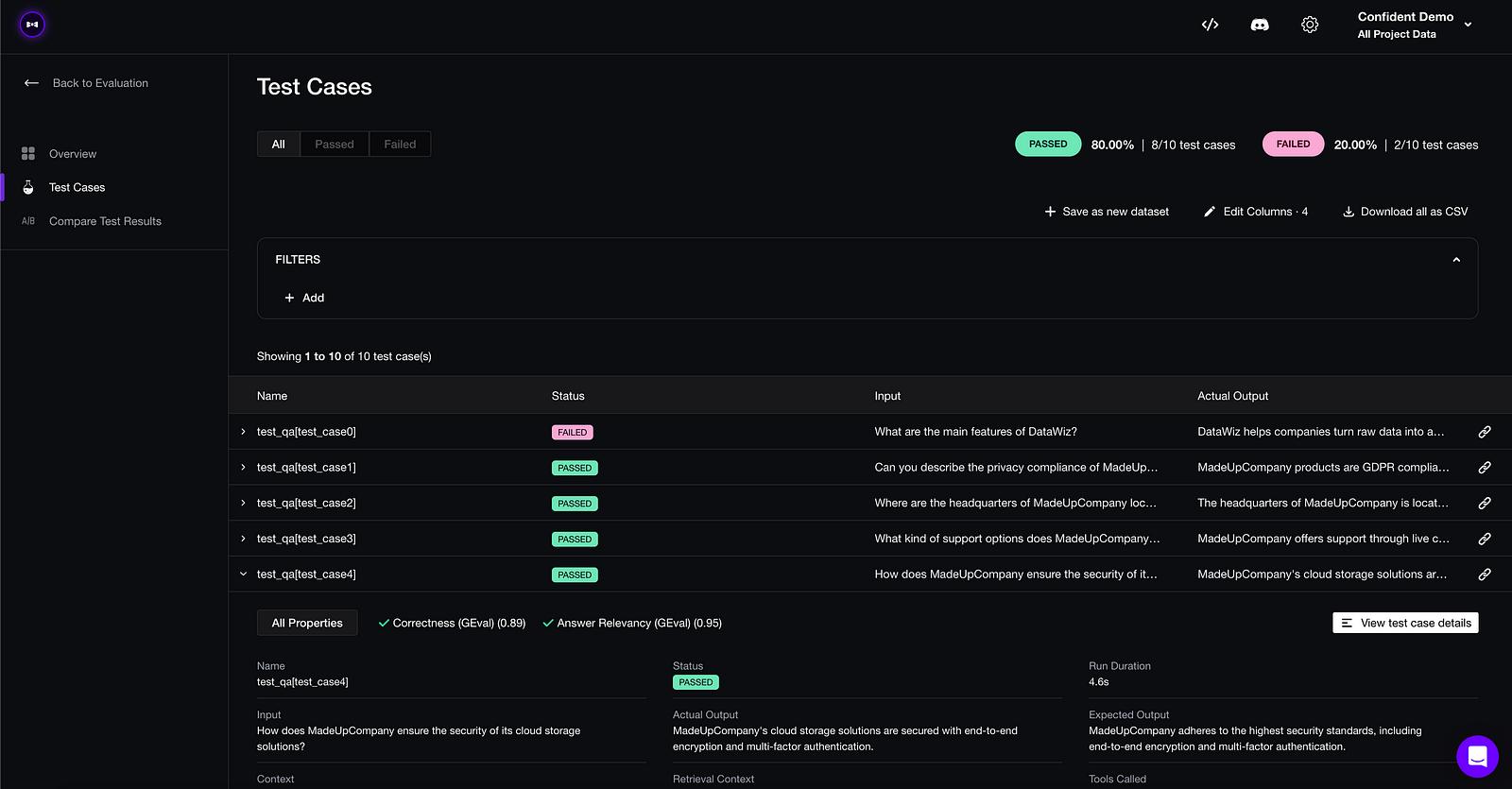
你的测试报告
2. Arize AI
Arize AI 提供强大、实时的监控与故障排除功能,针对LLMs,使其成为识别性能下降、数据漂移和模型偏差的重要工具。与 Confident AI 类似,它具备出色的追踪能力便于调试,但在评测数据集的支持程度上未达理想水平,因此在列表中位列第二。请记住,优秀的LLM评测 == 指标质量 × 数据集质量。
然而,其突出特点之一是能够提供跨细分领域的模型性能精细分析。它能精准定位模型表现不佳的具体领域,例如语言处理任务中的特定方言或独特情境。对于需要微调模型以确保在所有输入和用户交互中保持一贯高性能的场景,这种细分分析不可或缺。
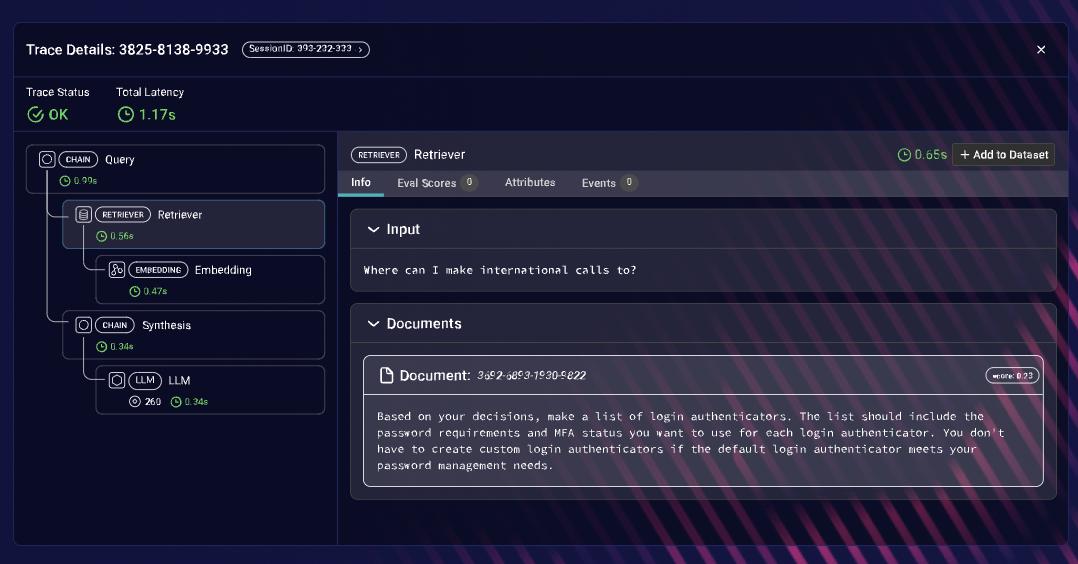
Arize AI追踪
它也可以免费试用。
3. MLFlow
MLflow 的实验跟踪功能,如记录参数、指标、代码版本和工件,为管理LLM评测提供了结构化方法。这有助于系统性地组织和比较不同测试,从而更容易识别有效配置。其 Projects 功能确保依赖项和工作流可重现,这在跨不同环境或团队运行评测时非常有用。
该平台的模型生命周期管理工具,包括版本控制和阶段转换,与LLM开发和评测的迭代性质高度契合。这些能力使 MLflow 成为跟踪和管理评测过程的有用选择,确保实验和模型得到充分记录且易于访问。
然而,它缺乏经过验证和可信的指标层级,因此在列表中位列第三。
4. Datadog
Datadog 的监控与可观测性功能对LLM评测尤为有益,特别是在生产环境中。其实时追踪指标、日志和链路的能力,使得能够详细监控LLM行为,如响应时间、资源使用率和 API 延迟。这对于评测模型在不同条件下的表现极具价值,尤其是在提供实时预测时。
Datadog 的集成能力使得将LLM性能数据与其他应用及基础设施指标结合变得简单,从而提供系统性能的全貌视图。这有助于识别可能影响模型评测或部署的潜在瓶颈或异常情况。
Datadog 专注于基础设施和系统级监控,而非针对特定模型的评测。它缺乏对LLM评测指标的本地支持,尽管其调试能力出色,仍仅位列第四。毕竟,Datadog 提供的所有功能在 Confident AI、Arize AI 和 ML Flow 中同样具备,且表现更优。
5. Ragas
RAGAS 是一款专为评测检索增强生成(RAG)系统设计的工具包,特别适用于LLMs与外部知识库集成的场景。它聚焦于 RAG 特有的评测指标,如检索相关性和响应质量,确保能有效评测此类系统的效能。此外,作为轻量级工具包,RAGAS 易于集成到现有工作流中,无需复杂配置。
虽然 RAGAS 在特定用例中表现高效,但它缺乏一个更广泛的平台或生态系统来管理整个评测生命周期。它不提供诸如实验跟踪、工件存储或模型生命周期管理等功能,而这些功能在生产环境中全面评测LLMs时往往是必需的。由于它仅是一个软件包,像 Confident AI 和 Arize AI 这样的平台已在其自有平台中集成了 Ragas 指标,这使得 Ragas 虽有用,但也能通过更为完善的一体化解决方案来使用。
结论总结
无论你是独立开发者、首席工程师,还是公司中的 AI 领导者,这个等式都成立:优秀的LLM评测 = 指标质量 × 数据集质量。因此,你应该选择最适合你使用场景的工具,以最大化你正在进行的LLM评测的质量。毕竟,你最不希望的就是被错误的评测结果引入歧途。
我有点偏心,但我打造 Confident AI 是有原因的——因为市场上现有的工具无法与理想的LLM评测流程相匹配。Confident AI 的功能远不止于此,但如果要我选一个特点来说,那就是它能最大化你LLM应用的 ROI。
