

作为头部闭源向量数据库供应商,Pinecone 凭借其高速、可扩展性和易用性闻名业界。其极速向量搜索能力使其成为大规模 RAG 应用的热门选择。我们(Confident AI,全球首个开源 LLM 评估框架)的初期架构也曾使用 Pinecone 对生产环境中的大模型可观测性日志进行聚类分析。然而,经过数周的实测验证后,我们决定全面替换为 pgvector。尽管 Pinecone 的设计看似简单,但其与现有数据存储方案的集成存在隐性挑战。比如对元数据字段数量和容量的严格限制,难以应对高密度数据场景
本文将解析为何类似 Pinecone 的向量数据库可能并非 LLM 应用的最优解——并厘清其应避用的典型场景。
Pinecone 专为快速向量搜索优化
在 Pinecone 的官方网站中,其核心特性被重点强调为:
“通过 Pinecone 解锁强大的向量搜索功能——直觉式易用、速度优先设计、轻松无缝扩展。”
但你真的需要一个专用向量数据库来“解锁强大的向量搜索”吗?考虑到我们需要对存储在 PostgreSQL 数据库中的日志数据进行聚类和搜索,我们最初考虑使用 Pinecone——因为它承诺提供快速的语义搜索和可扩展性。但事实证明,使用 Pinecone 这类闭源搜索方案的主要瓶颈在于网络请求延迟(而非搜索操作本身)。此外,虽然 Pinecone 确实能通过调整 vCPU、内存和磁盘资源(称为“Pods”)实现扩展,但强制部署另一个专门用于语义搜索的数据库,会不必要地复杂化标准数据存储架构。最后,由于其严格的元数据限制,我们不得不采用两步流程:先在 Pinecone 执行向量搜索,再查询主数据库获取与检索到的向量嵌入相关联的完整数据。
可能有人不知道的是:向量数据库最初是为大型企业存储海量向量嵌入(用于训练机器学习模型)而开发的。但现在看来,每家向量数据库公司都在鼓吹“LLM 应用技术栈必须配备专用向量数据库供应商”的理念。
Pinecone 的可扩展性神话破灭
尽管 Pinecone 的 s2、p1 和 p2 计算单元(Pods)支持水平扩展(提升每秒查询数 QPS)和垂直扩展(通过 x1/x2/x4/x8 规格扩容单个 Pod 的向量容量),但其架构仍存在大规模工作负载的关键缺陷:
- 数据同步难题——Pinecone 仅通过API接口与其索引进行数据收发。这种设计虽然简化了操作,却缺乏与主数据源的同步机制。在数据密集型应用中,索引与源数据不同步的现象极为普遍,尤其是在经历高数据负载时段后,此类问题会显著加剧。
- 存储容量限制——Pinecone 将每个向量的元数据限制在 40KB 以内,迫使开发者必须额外查询主数据源才能获取完整元数据。此外,这一限制还要求引入额外的错误处理逻辑,以应对数据存储溢出的问题。
这些缺陷本质上是 Pinecone数据处理架构的扩展性硬伤。因此,在多数场景下,优先考虑现有数据库的向量扩展方案比采用独立向量数据库更为明智。
Pinecone 的其他功能缺陷
-
闭源性——对于大多数软件应用这并非问题,但在需要极致速度优化的场景中,网络延迟必然成为性能瓶颈(即使向量搜索本身极快)。
-
非完整数据库方案——缺少关键企业级功能:行级安全,数据库备份,批量操作,完整的 ACID 事务支持
- 索引算法单一性——仅支持专有的近似最近邻(ANN)索引,且调整查询精度与速度的唯一方式是更换 Pod 类型(无法自定义算法参数)。
早期 pgvector 仅支持性能表现平庸的 IVFFlat 索引,但自引入 HNSW 以来,其性能在向量数据库标准评估方法ANN基准测试中已超越Pinecone 全部三种计算单元类型(pods)。(值得注意的是,有基准测试显示:在同等算力下,pgvector 的 IVFFlat 索引性能甚至优于 s1 计算单元,且 QPS 高出 143%。)
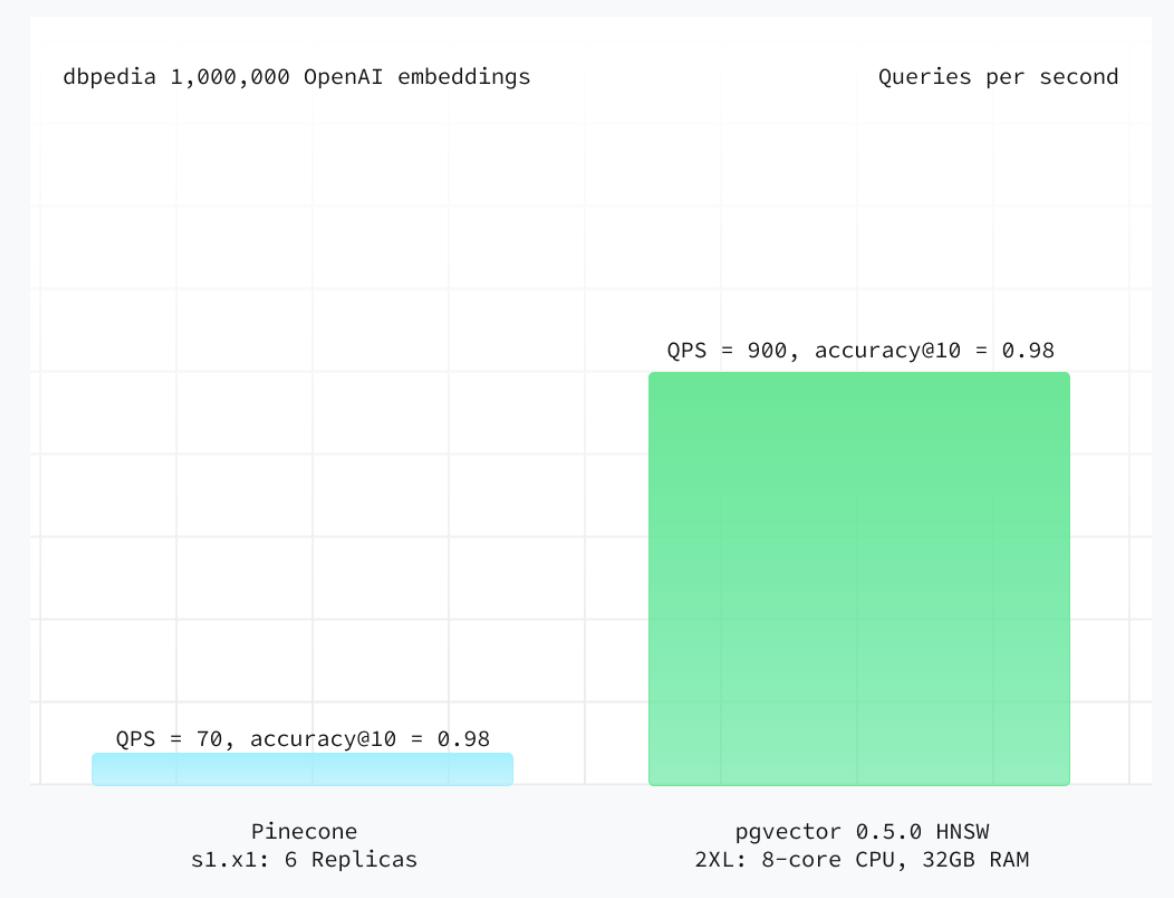
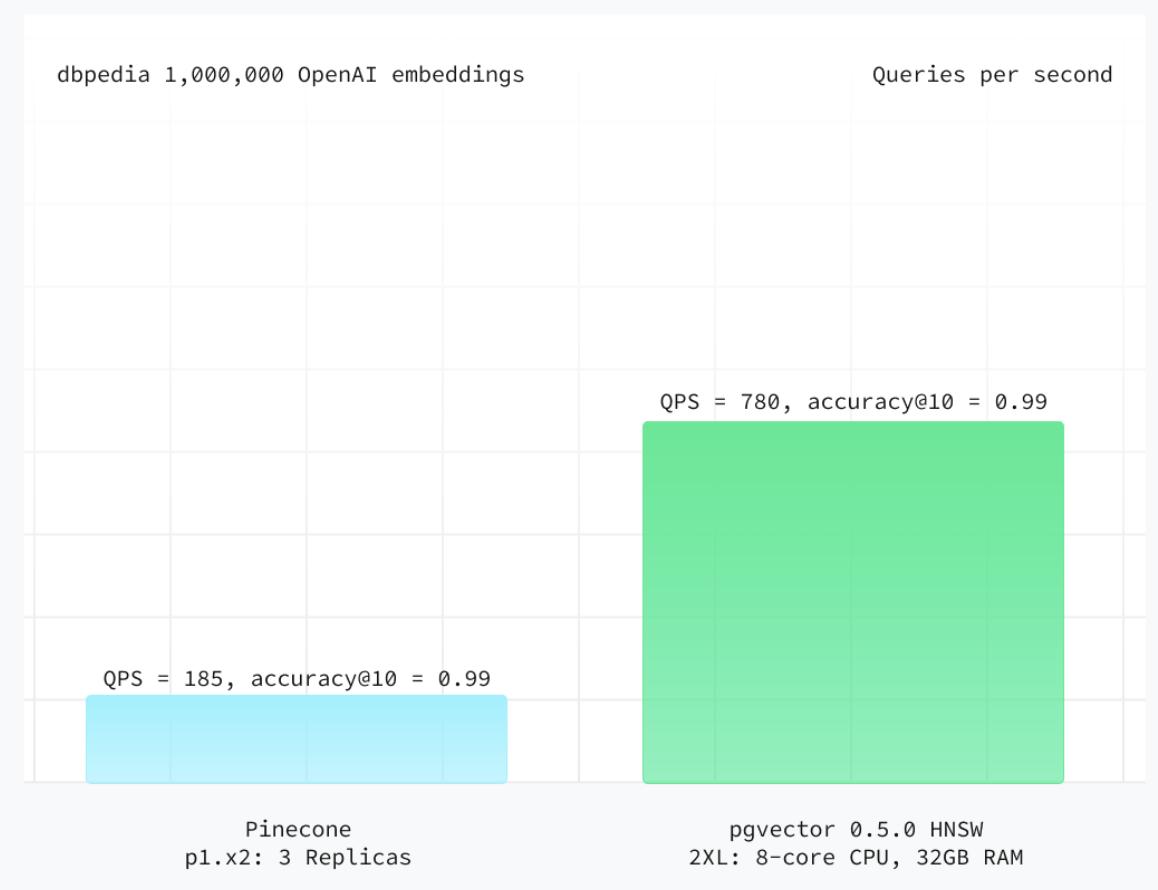
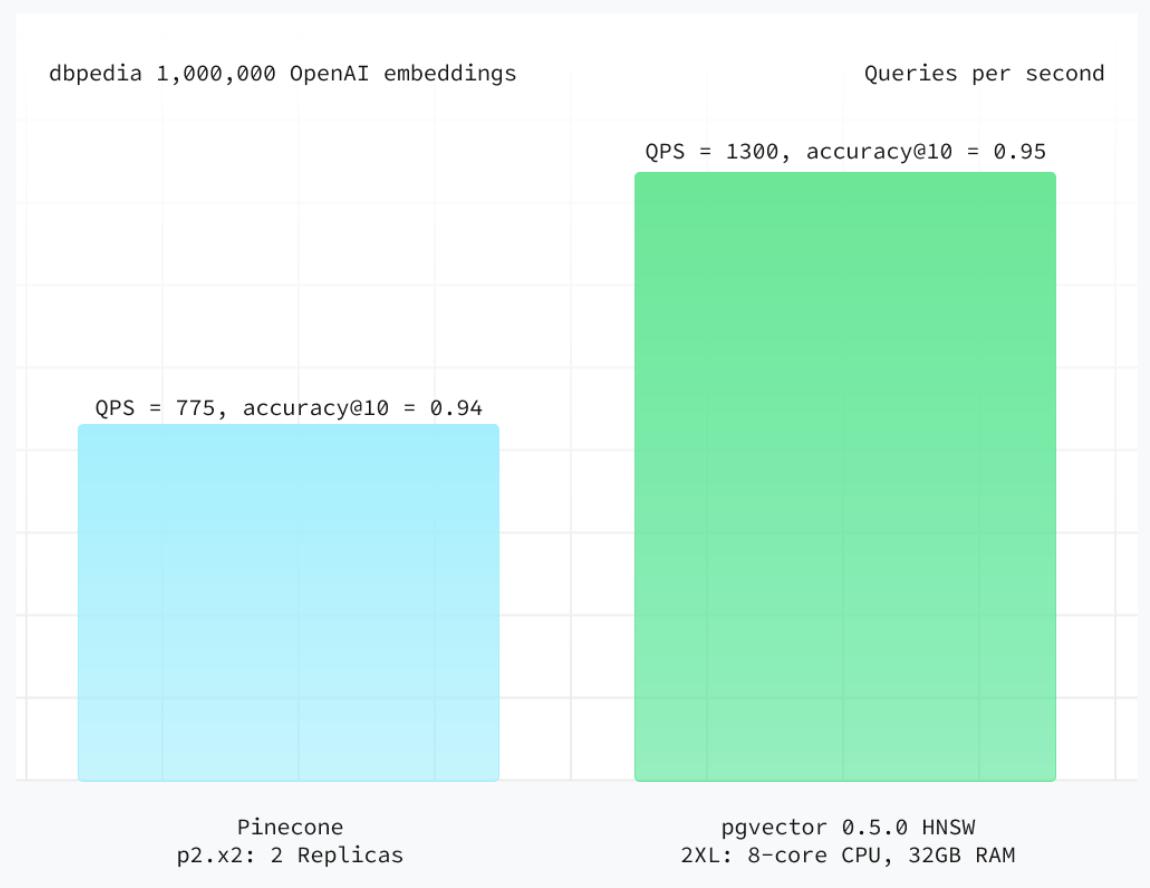
数据来源:Supabase。结果显示,在相同计算资源下(通过垂直扩展计算单元以匹配存储容量),pgvector 在准确性和每秒查询数(QPS)上均优于 Pinecone 的所有三种计算单元类型(Pods)。
PGVector 并非完美
-
使用你首选数据存储引擎的向量化扩展方案时,一个常见问题是难以统一分散的数据源——而这正是对数据执行向量搜索的必要条件。
-
Pinecone 可能具备成本优势。每月约 160 美元即可使用 p1.x2 计算单元(无需副本),仍能实现接近 60 QPS 的吞吐量,且准确率高达 0.99。若以相同预算购买托管 PostgreSQL 服务,可能会遇到索引无法完全载入内存的问题,导致被迫依赖不使用索引的较慢 KNN 搜索方法。不过,你也可以通过垂直扩展(类似升级计算单元规格)来容纳更多向量。
结论
Pinecone 在概念验证(POC)项目中表现优异,但若想维护一个可扩展且高性能的搜索基础设施,需投入大量精力。尽管它支持在多数据源上执行向量搜索,但这对于我们在 Confident 的实际用例而言并无必要。如果你的向量搜索场景仅涉及单一来源的现有数据,建议优先选择内置向量化方案的数据存储解决方案,而非独立向量数据库。
