图5 AlphaGo实现原理示意图
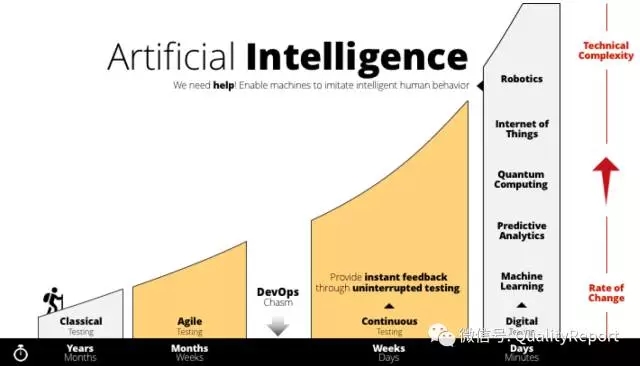
从软件的功能测试或业务测试看,一直是有挑战的。大家知道有一条著名的测试原则:测试不能穷尽的,测试总是有风险的。这就告诉我们,要做的测试(tests,不仅仅包括测试用例,还包括测试数据、路径、环境和应用场景、上下文等)数量是巨大的,这就是测试经常遇到的序列爆炸、组合爆炸、路径爆炸等一系列问题。以前认为这是无法完成的测试任务,今天借助AI可以得到比较满意的解决,即能不能像AlphaGo那样建立两个网络?
-
质量风险网络:根据当前已做的测试,基于多层神经网络的深度学习来评估软件的质量风险,给出具体的风险值;
-
测试策略网络:从可选的未执行的tests中,选择哪一个test作为下一步测试能够最大程度地降低质量风险(发现Bug的可能性最大)。
微软为此建立了其自适应的神经网络算法(Microsoft Neural Network algorithm,MNN算法),该算法针对可预测属性的每个可能状态,以测试输入数据属性的每个可能状态,以及基于训练数据能够计算每个组合的概率。可以将这些概率用于缺陷分类或回归测试任务,并能根据某些输入属性来预测输出结果。2016年1月,微软在GitHub上发布了其深度学习工具包——Computational Network Toolkit(CNTK)。CNTK 通过一个有向图将神经网络描述为一系列计算步骤,从而使得实现和组合DNN、CNN和RNNs/LSTMs 变得非常容易。
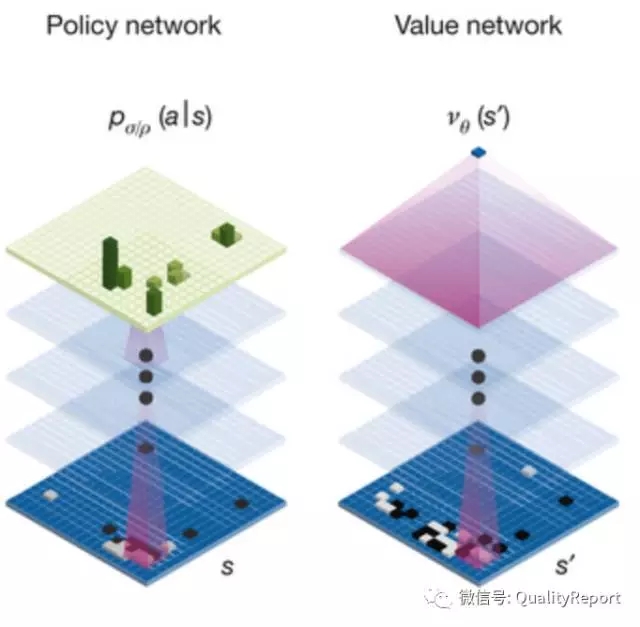
图6 当系统越来越复杂时已达到的测试覆盖率与实际覆盖率之间差距越大
(也说明今天面对更复杂的系统,如IoT,更需要AI帮助)
基于类似的思想,瑞典的一家公司(King.com)采用Monte Carlo树搜索算法、自动启发式构建算法、增强拓扑的神经元演化算法 (Neuro Evolution of Augmenting Topologies,NEAT )来训练 AI测试工具 (bots) ,模拟人类交互能力,完成对Candy Crush Soda游戏的功能测试、稳定性测试和性能测试,并评估游戏难度级别,预测游戏的成功率。要知道这款游戏是当今手机上最大的游戏之一,有1000多个难度级别,在增加新功能或新级别时,如何验证新增的难度水平与之前级别是平衡的,对测试人员来说,非常有挑战。而且这款游戏的用户越来越多,对游戏质量的期望也越来越高,希望游戏非常稳定、流畅。
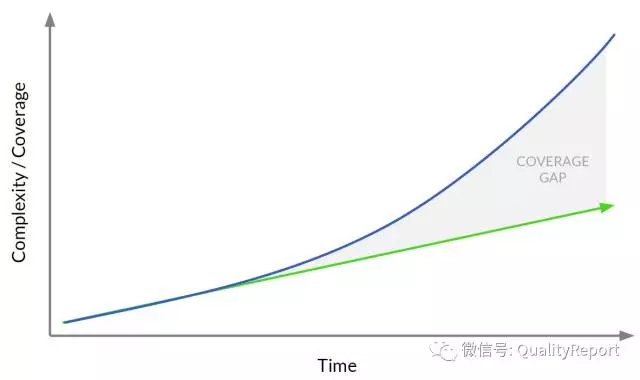
图7 Monte Carlo树搜索算法应用于模拟游戏操作
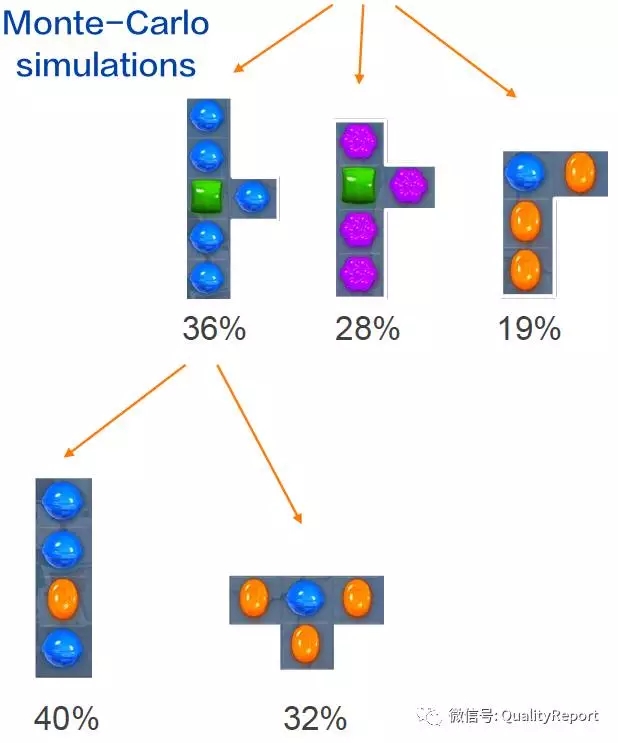
图7 Monte Carlo树搜索算法应用于模拟游戏操作
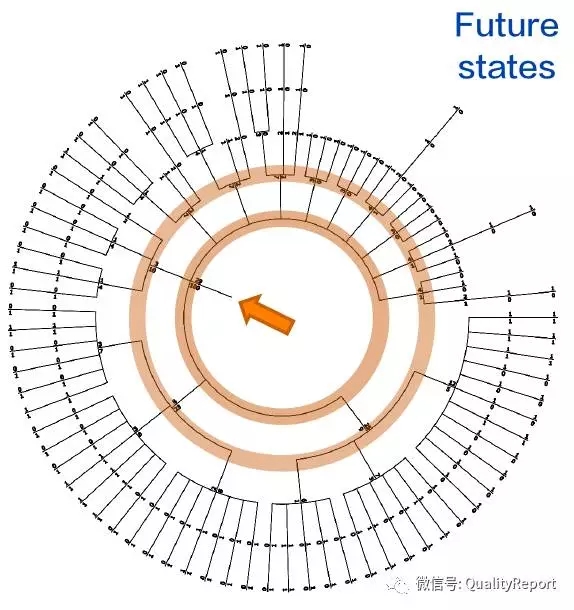
图8 自动启发式构建系统操作状态路径图(续)
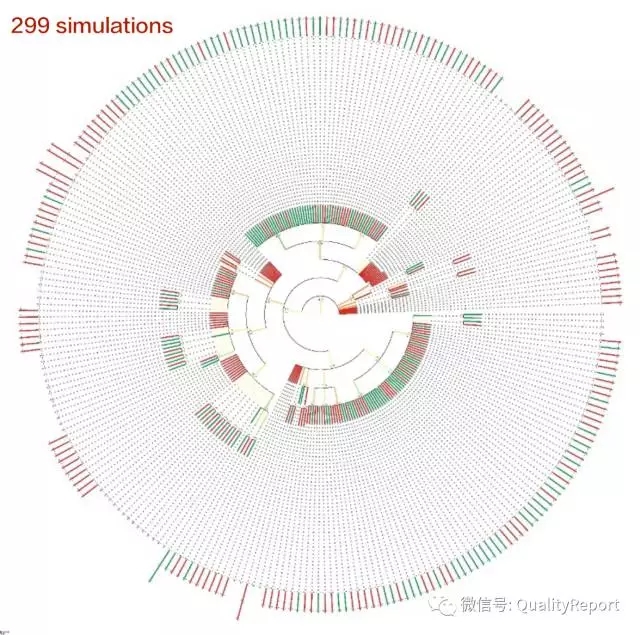
图9 自动启发式构建系统操作状态路径图(续)
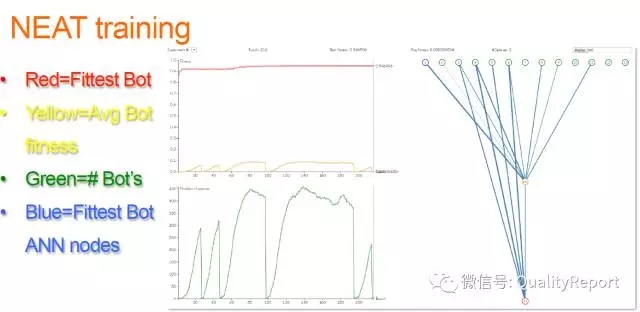
图10 采用NEAT来训练游戏的AI测试工具
几乎在同一个时间,美国一家公司(Appdiff)推出测试机器人,能够全面分析App应用中的每个界面、元素和操作流,进行性能测试和用户体验测试(怀疑吗?😄)。Appdiff的智能机器人,可以克服经典的测试方法所存在的速度慢、开销大的问题,具备类似人类的洞察力,就像魔术一样快速完成测试,而且具有学习能力,App应用程序测试越多,工具会自动地变得越来越聪明。采用的AI,就可以替换过去脚本的开发,让自动化测试进行得更轻松,而且AI能处理的测试输入,手工是无法相比的。

图11 输入空间(10的65次方)极大,只有AI才能解决
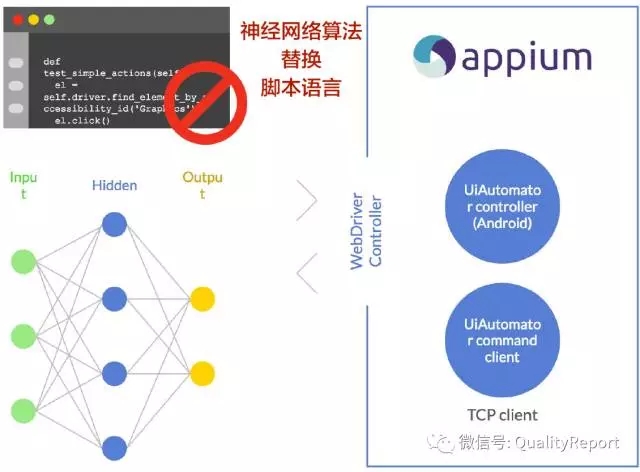
图12 用神经网络算法代替自动化测试脚本
再进一步,就可以让AI驱动测试,基于AI的搜索优化或其它测试策略的优化,逐步往下执行测试。有的公司已经实实在在地迈出了这一步,如下图所示:
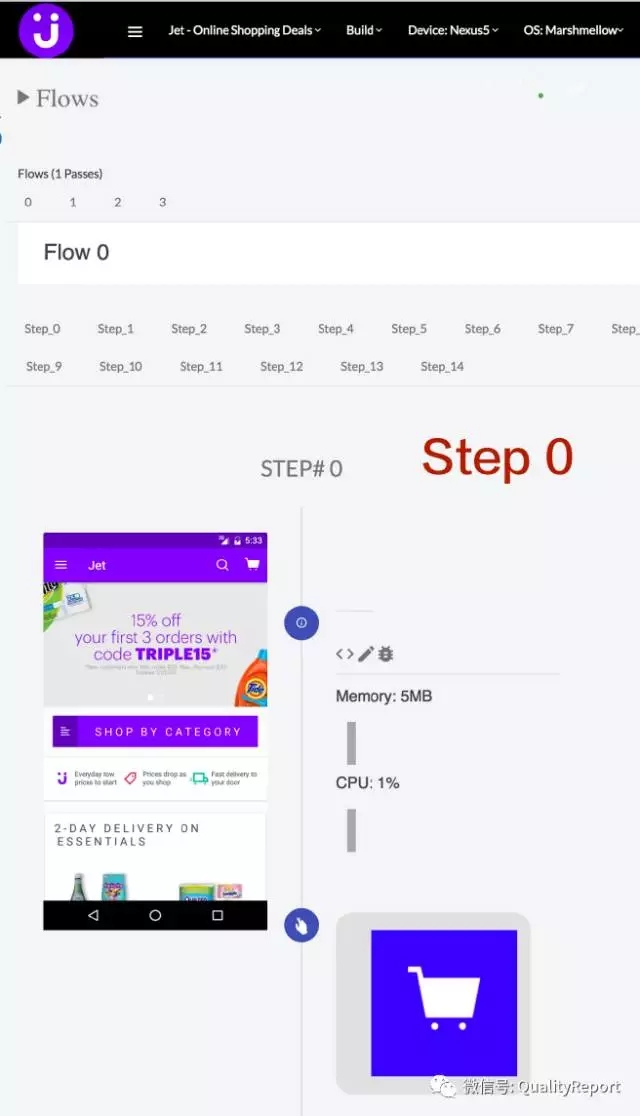
图13 App应用初始化界面和测试操作的截图
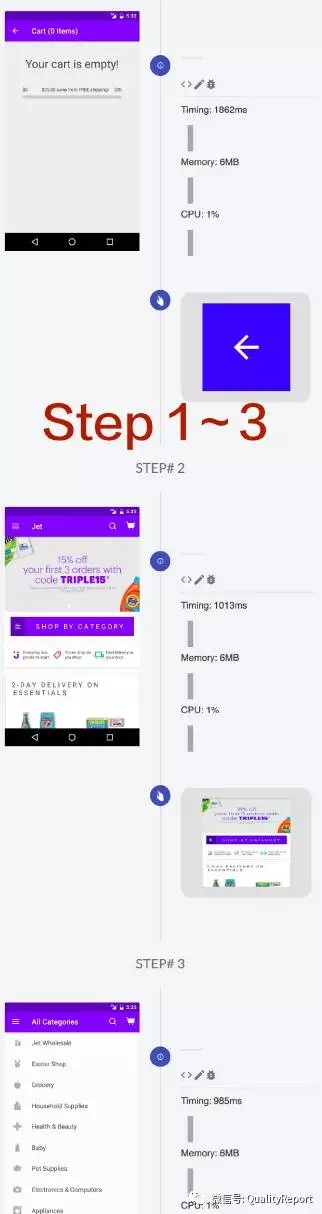
图14 App应用测试操作第1~3步的截图

图15 App应用测试操作90+步的截图
再比如回归测试,我们之前会将基于风险的测试策略和基于操作剖面的测试策略结合起来优化测试范围。之后,也有一些公司采用工具分析代码的依赖关系,同时建立代码和测试用例的映射关系。一旦代码被修改了,就可以分析受影响的类、方法甚至代码行,再根据映射关系来选择测试用例,做到精准测试,让测试做得又快又好。但这种方法所建立的代码之间依赖关系、代码与测试用例映射关系,往往是静态的,不能随时更新,而且忽视了上下文、业务、数据、环境等因素,所建立的关系是不够可靠的,其实风险还是蛮大的。如果把这些因素都考虑进去,现有的方法又不能解决问题。这时,通过机器学习对代码库(包括更新/diff信息)、测试用例库、Bug库、客户反馈信息、系统执行测试的log等进行数据挖掘,来优化回归测试范围,这样的结果更可靠、执行效率更高。
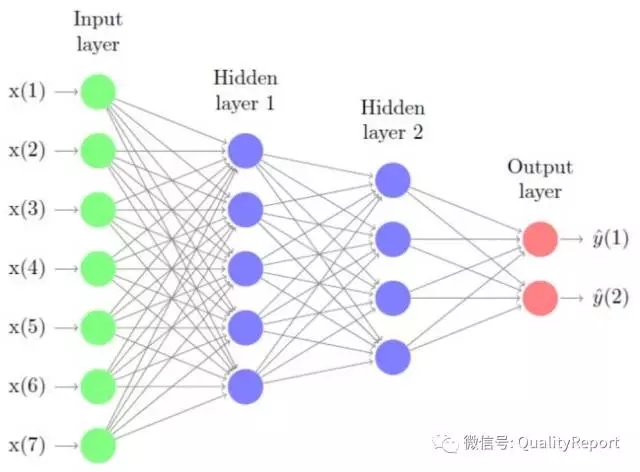
图16 回归测试机器学习示意图(原理类似图11、图12)
不仅仅是功能测试,安全性测试也可以采用类似的解决思路。号称当前最高级的模糊(Fuzzing)测试工具之一 ——afl-fuzz,采用了AI解决思路,通过遗传算法(genetic algorithms)和对源码“编译时插桩”方式自动产生测试用例来探索二进制程序内部新的执行路径,从而获得高效的模糊测试策略。因为afl-fuzz是智能的,不需要先行复杂的配置,能够不断优化执行路径,具有较低的性能消耗、而且能处理现实中复杂的程序。
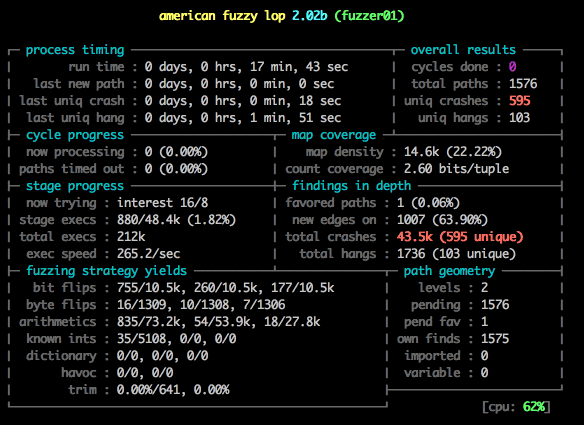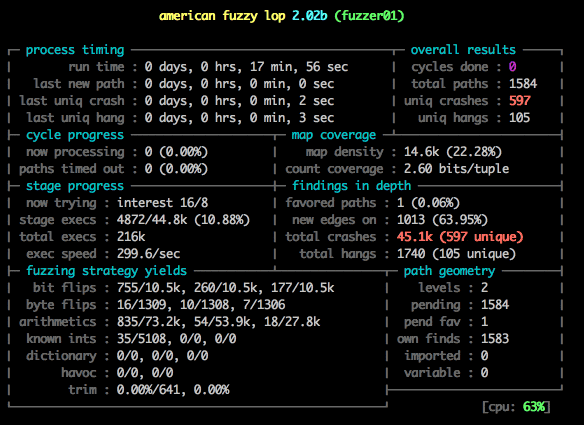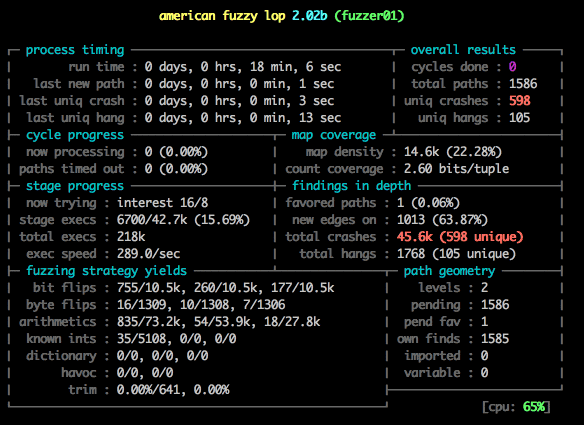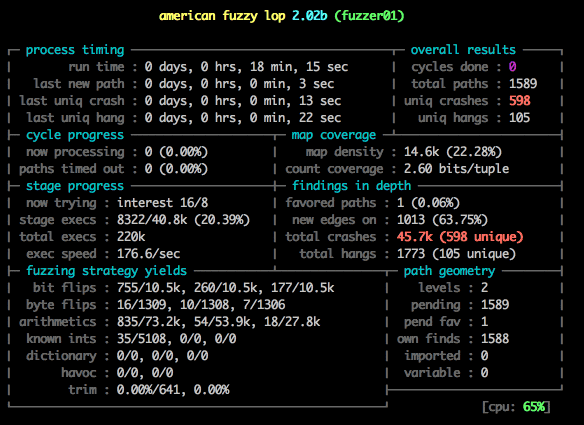
图17 afl-fuzz 测试输出的简短展示过程
【背景知识:我们知道,模糊测试技术非常适合评估软件的安全性,能够发现大多数远程代码执行和特权提升等比较严重的漏洞。然而Fuzzing技术的测试覆盖率比较低,还会遗漏比较多的代码漏洞。为了解决这一问题,人们提出了不少新的方法获取代码更多信息去引导和增强测试技术的方法。如语义库蒸馏(corpus distillation)、流分析(concolic execution)、符号执行(symbolic execution)和静态分析等。但是语义库蒸馏严重依赖于大量的、高质量的合法输入数据的语料库,这样,它并不适合后续引导模糊测试,其它方法受可靠性问题和程序执行环境的复杂性所束缚,如路径爆炸问题,从而导致这些方法的应用价值不高。】
除了afl-fuzz,另一款智能安全性测试工具 Peach Fuzzer,会建立状态模型和数据模型,具有状态自动感知和应用感知能力,“了解”给定测试场景中的有效数据应该是什么样的,不断优化测试模型,从而生成智能的测试用例(数据),帮助我们发现更多的隐藏的错误,从而最大限度地提高测试覆盖率和精度。基于同样思路,作者曾经采用机器学习,开发相应的测试工具,为稳定性测试、可靠性测试动态生成有效测试集;也可以根据测试预算时间,生成所需的、相对最优的测试用例集。

图18 Peach Fuzzer 智能实现的示意图
上述解决思路,主要是基于机器学习和搜索算法等生成最优的测试用例。在测试中还会遇到另一类问题——启发式或模糊的测试预言(test oracle),没有单一、明确的判断准则,这是一般自动化测试工具无法验证的,需要人进行综合判断。在敏捷开发模式实施后,这类问题更突出。这一问题的解决也适合AI方法。基于机器学习理论,采用有效的PAC( probably approximately correct)算法来实现(关于这类算法,可参考Kearns & Vazirani 的书 An Introduction to Computational Learning Theory, MIT Press),例如微软推出的语义理解服务LUIS.ai 框架,借助它能够灵活地进行API调用,创建自己场景的语义理解服务,识别实体和消息的意图。一旦应用程序上线,接收到十几条真实的数据,LUIS就能给主动学习、训练自己。LUIS能检查发送给它的所有消息,将模棱两可的文本识别出来,并提醒我们注意那些需要标注的语句。这样,可以基于LUIS的智能框架开发功能测试、业务验收测试工具。
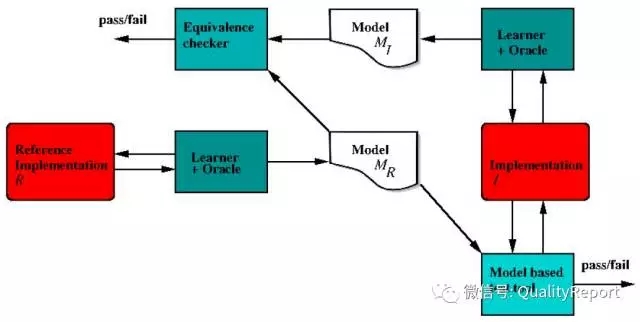
图19 LUIS.ai 具体应用的简单示意图
除了测试过程、Test Oracle之外,测试输入也是AI能给发挥的地方,上面介绍的Peach Fuzzer就是一个典型的例子。在功能兼容性测试、稳定性测试等实际工作中,业务逻辑、应用场景比较多,人工考虑不全,依赖AI来帮忙发现这些测试输入及其组合,其中模型学习可以看作这类AI应用场景。银行卡、网络协议等领域已经应用模型学习来发现更多的缺陷,例如De Ruiter 和 Poll的实验表明,在九个受测试的 TLS (测试学习系统)实现中,有三个能够发现新的缺陷。而Fiterau 等人在一个涉及 Linux、Windows 以及使用 TCP 服务器与客户端的 FreeBSD 实现的案例研究中将模型学习与模型检查进行了结合。模型学习用于推断不同组件的模型,然后应用模型检查来充分探索当这些组件交互时可能的情况。案例研究揭示了 TCP 实现中不符合其 RFC 规范的几个例子。概括起来,使用自动机学习建立实现一致性的基本方法,学习者与实现交互以构建模型,然后随后将其用于基于模型的测试或等价性检查。
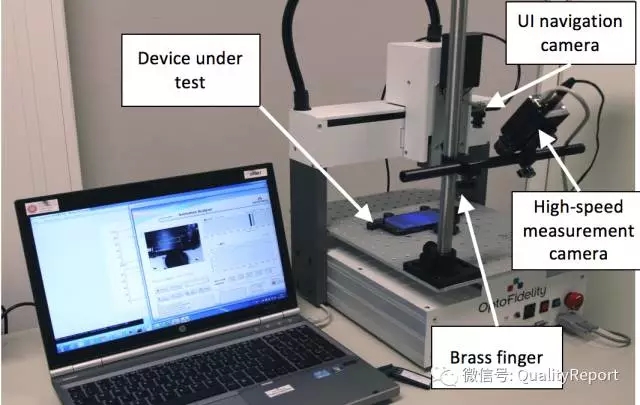
图20 模型学习和模型检验结合起来进行测试的示意图
AI应用于测试的案例还很多,例如,2015年Facebook公司就采用PassBot、FailBot等管理测试(见 Never Send a Human to do a Machine’s Job: How Facebook uses bots to manage tests in GTAC)。同年,Google Chrome OS团队使用芬兰OptoFidelity公司制造的机器人(Chrome TouchBot)来测量Android和Chrome OS设备的端到端延迟。

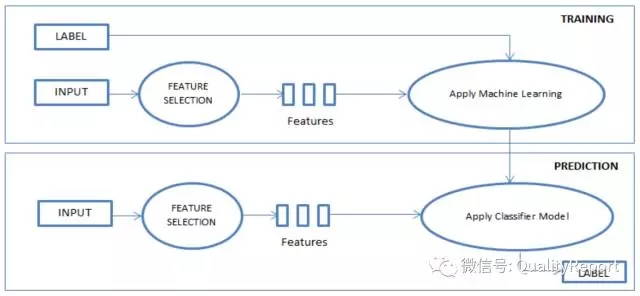
图24 缺陷自动分类、自动定位示意图
大家看到这里,基本了解AI在软件测试中发挥什么样的作用。如果还不了解,说明AI是一个比较复杂的主题,需要找时间面对面,向您慢慢道来。现在每年有多场AI大会,国务院最近也印发新一代人工智能发展规划,这一切都说明现在已经进入一个AI时代,测试人员需要做好准备,迎接AI所带来的新挑战。
(如果看到这里,说明您很有耐心,谢谢您的时间。AI的确也是一个复杂的主题,而且是一个很大的题目,文章匆匆完成,免不了有些错误,请读者多多包涵与指正)
参考:
-
https://dev.botframework.com
-
https://learnlib.de
-
http://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/
-
https://en.wikipedia.org/wiki/Outline_of_machine_learning
-
https://github.com/Microsoft/CNTK
-
https://docs.microsoft.com/en-us/sql/analysis-services/data-mining/microsoft-neural-network-algorithm
-
http://lcamtuf.coredump.cx/afl/
