

代码覆盖率是一个重要指标,用于描述特定测试套件对应用程序源代码的测试程度。在自动化测试的背景下,你可以使用不同的编程语言来测量代码覆盖率,比如Python。
Python提供了各种测试框架,如pytest,这些框架具有为自动化测试生成pytest代码覆盖率报告的能力。
让我们学习如何使用pytest框架生成代码覆盖率报告。
什么是代码覆盖率?
代码覆盖率是一个简单的统计指标,用于衡量测试套件验证的总代码行数。它采用一定的度量标准来计算应用程序源代码在测试中成功运行的代码总行数,通常以百分比的形式表示。
代码覆盖率 \=(已测试的代码总行数 / 需测试的代码总行数)× 100%
例如,在源代码中测试一个包含100行代码的类时,需要将这100行代码全部纳入测试范围。如果测试后遗漏了该类的40行代码,那么可以说测试套件覆盖了60%的代码。
在这种情况下,实际测试的代码行数为60行,而暴露于测试的代码行数为100行。这40行被遗漏的代码中可能隐藏着你不希望在生产环境中出现的漏洞。因此,你需要改进测试和源代码,以提高覆盖率。
为什么选择pytest生成代码覆盖率报告?
pytest拥有用于评估代码覆盖率的插件和支持模块。以下是使用pytest生成代码覆盖率报告的一些原因:
- 它提供了一种使用几行代码即可计算覆盖率的简单方法。
- 它提供了代码覆盖率分数的全面统计信息。
- 它具备可以帮助您美化pytest代码覆盖率报告的插件。
- 它具备用于执行代码覆盖率的命令行工具。
- 它支持分布式和本地化测试。
pytest 代码覆盖率报告工具
以下是一些最常用的 pytest 代码覆盖率工具。
coverage.py
coverage.py 库是最常用的 pytest 代码覆盖率报告工具之一。它是一个简单的 Python 工具,能够以表格格式生成全面的 pytest 代码覆盖率报告。你可以将其作为命令行工具使用,或者将其作为 API 插入到你的测试脚本中来生成覆盖率分析。
如果你不希望每次运行覆盖率分析时都重复输入一堆终端命令,建议使用 API 选项。
虽然它的命令行工具可能需要一些修补来防止报告出错,但 API 选项提供了清晰、预先设计好的 HTML 报告,你可以通过网页浏览器查看。
以下是使用 coverage.py 和 pytest 执行代码覆盖率的命令:
coverage run -m pytest
上述命令会运行所有名称以“test.”开头的 pytest 测试套件。
在使用其 API 生成报告时,你所需要做的就是在测试代码中指定一个目标文件夹。在后续的测试中,它会覆盖该文件夹中的 HTML 报告。
pytest-cov
pytest-cov 是 pytest 的一个代码覆盖率插件和命令行工具。它还为 coverage.py 提供了扩展支持。
与 coverage.py 类似,你可以使用 pytest-cov 在 pytest 中生成 HTML 或 XML 报告,并通过浏览器查看精美的代码覆盖率分析。虽然使用 pytest-cov 只需要通过终端运行一个简单的命令,但当你添加更多覆盖率选项时,终端命令会变得更长、更复杂。
例如,生成仅包含命令行的报告只需运行以下命令即可:
pytest —cov
pytest --cov 命令的结果如下所示:

但是生成 HTML 报告需要额外的命令:
pytest —cov —cov-report\=html:coverage_re
其中 coverage_re 是覆盖率报告目录。以下是通过浏览器查看时的报告:
以下是与 --cov 一起使用的常用命令行选项列表:
| -cov 选项 | 描述 |
|---|---|
| -cov=PATH | 测量文件系统中某个路径的代码覆盖率。(可多次使用) |
| –cov-report=type | 指定要生成的报告类型。明确要生成的报告类型。类型可以是 HTML、XML、annotate(注释)、term(终端)、term-missing(终端缺失)、或 lcov。 |
| –cov-config=path | 覆盖率的配置文件。默认值:.coveragerc |
| –no-cov-on-fail | 如果测试失败,则不报告覆盖率。默认值:False |
| –no-cov | 完全禁用覆盖率报告(对调试器有用)。默认值:False |
| –cov-reset | 重置到目前为止在选项中累积的覆盖率来源。对脚本和配置文件特别有用。 |
| –cov-fail-under=MIN | 如果总覆盖率低于 MIN,则测试失败。 |
| –cov-append | 不删除覆盖率数据,而是追加到当前数据中。默认值:False |
| –cov-branch | 启用分支覆盖率。 |
| –cov-context | 选择设置动态上下文的方法。 |
演示:如何生成 pytest 代码覆盖率报告?
生成 pytest 代码覆盖率的演示包括以下几个方面的测试:
- 一个普通的tweak类示例,用于展示为什么可能无法达到 100% 的代码覆盖率,以及如何利用其结果来扩展测试范围。
- 使用某个电子商务测试平台在云上执行的注册步骤的代码覆盖率演示。
我们将使用 Python 的 coverage 模块(coverage.py)来演示本教程中所有测试在 pytest 代码覆盖率报告中的代码覆盖率。因此,你需要安装 coverage.py 模块,因为它是第三方模块。你还需要安装 Selenium WebDriver(用于访问 Web 元素)和 python-dotenv(用于隐藏你的密钥)。
如果你对 Selenium WebDriver 不太了解,可以查看我们的指南来了解 Selenium WebDriver 是什么。
在你的项目根目录中创建一个 requirements.txt 文件,并插入以下包:
Filename – requirements.txt
coverage
selenium
python-dotenv
pytest
接下来,使用 pip 安装这些包:
pip install -r requirements.txt
如前所述,coverage.py 允许你在一个 HTML 文件中生成和写入覆盖率报告,并在浏览器中查看它。稍后你将看到如何操作。
tweak测试类
我们将首先以一个tweak类的示例测试为例,来演示为什么你可能无法达到 100% 的代码覆盖率。并且你还将看到如何扩展你的代码覆盖率。
tweak类包含两个方法。一个是用于连接一个新名称和一个旧名称,而另一个是用于更改现有名称。
Filename: plain_tests/plain_tests.py
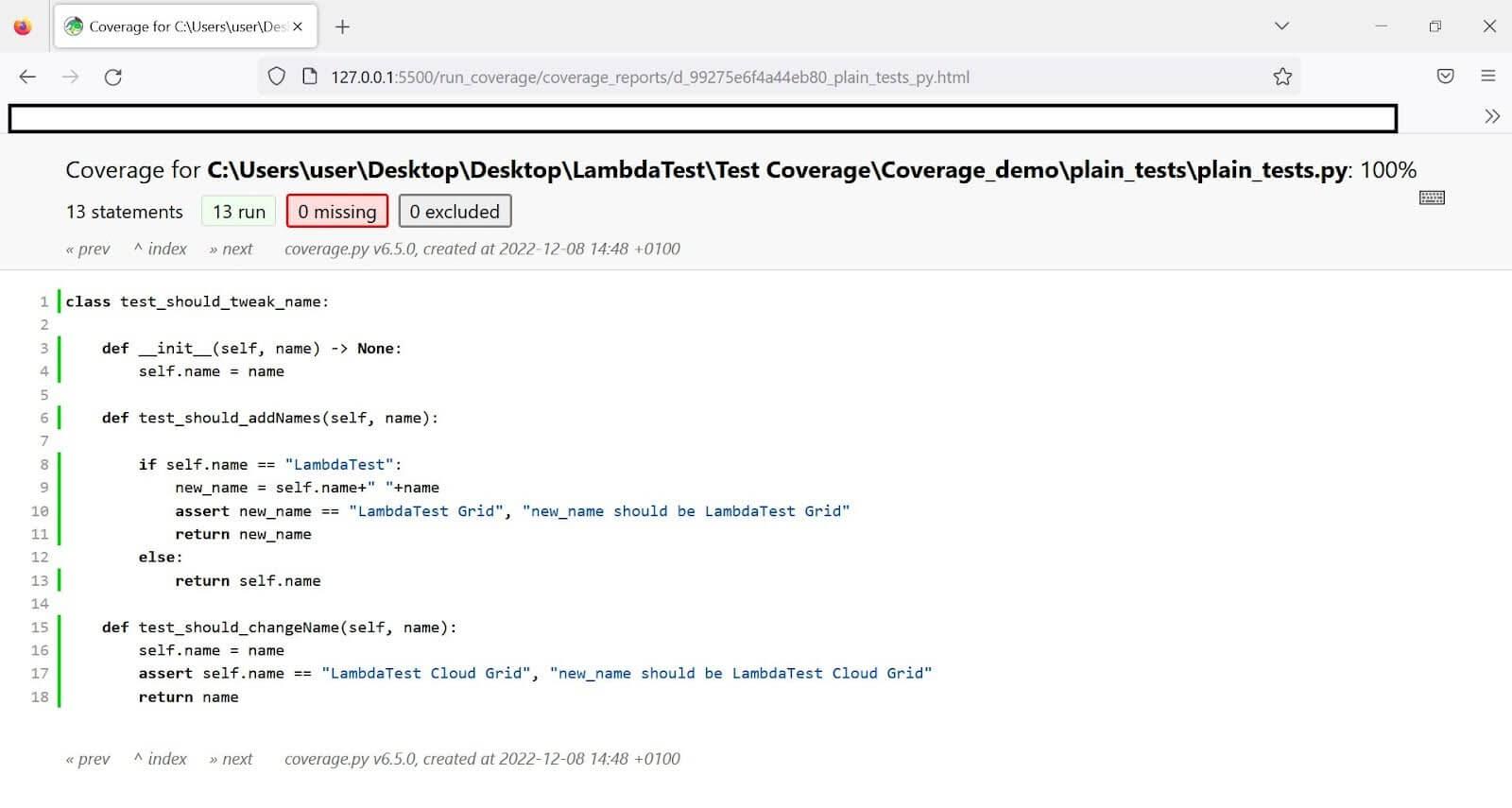
class test_should_tweak_name:
def __init__(self, name) -> None:
self.name = name
def test_should_addNames(self, name):
if self.name == "LambdaTest":
new_name = self.name+" "+name
assert new_name == "LambdaTest Grid", "new_name should be LambdaTest Grid"
return new_name
else:
return self.name
def test_should_changeName(self, name):
self.name = name
assert self.name == "LambdaTest Cloud Grid", "new_name should be LambdaTest Cloud Grid"
return name
为了执行测试并获得低于 100% 的代码覆盖率,我们首先将省略对第一个方法中 else 语句的测试用例,并且完全忽略第二个方法(test_should_changeName)。
Filename: run_coverage/name_tweak_coverage.py
# Import the Pytest coverage plugin:
import coverage
# Start code coverage before importing other modules:
cov = coverage.Coverage()
cov.start()
# Main code to be covered----------:
import sys
sys.path.append(sys.path[0] + "/..")
from plain_tests.plain_tests import test_should_tweak_name
tweak_names = test_should_tweak_name("LambdaTest")
print(tweak_names.test_should_addNames("Grid"))
cov.stop()
cov.save()
cov.html_report(directory='coverage_reports')
通过运行以下命令来执行测试:
run_coverage/name_tweak_coverage.py
进入coverage_reports文件夹,并通过您的浏览器运行index.html。由于省略了两个命名的实例,测试覆盖率为69%(如下所示)。

让我们提高代码覆盖率。
尽管我们故意忽略了该类中的第二个方法,但很容易忘记在测试中为else语句添加一个用例。这是因为我们只关注验证true条件。包含一个假设为否定情况(即条件返回false)的测试用例可以提高代码覆盖率。
那么,如果我们为第二个方法添加一个测试用例,并且再添加一个假设第一个方法中提供的名称不是LambdaTest的测试用例,会怎样呢?
由于我们考虑了被测类的所有可能场景,因此代码覆盖率达到了100%。
因此,一个更全面的测试看起来像这样:
Filename: run_coverage/name_tweak_coverage.py
# Import the Pytest coverage plugin:
import coverage
# Start code coverage before importing other modules:
cov = coverage.Coverage()
cov.start()
# Main code to be covered----------:
import sys
sys.path.append(sys.path[0] + "/..")
from plain_tests.plain_tests import test_should_tweak_name
tweak_names = test_should_tweak_name("LambdaTest")
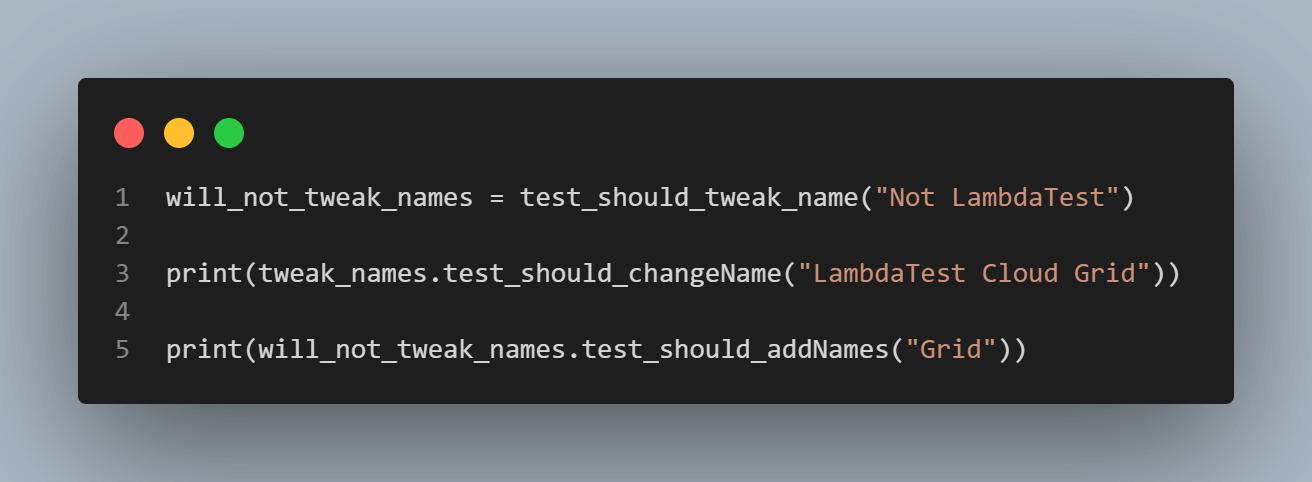
will_not_tweak_names = test_should_tweak_name("Not LambdaTest")
print(tweak_names.test_should_addNames("Grid"))
print(tweak_names.test_should_changeName("LambdaTest Cloud Grid"))
print(will_not_tweak_names.test_should_addNames("Grid"))
# Stop code coverage and save the output in a reports directory---------:
cov.stop()
cov.save()
cov.html_report(directory='coverage_reports')
添加will_not_tweak_names变量可以覆盖测试中的else条件。此外,通过类实例调用test_should_changeName方法可以捕获该类中的第二个方法。
以这种方式扩展覆盖率可以产生100%的代码覆盖率,如下所示:
云端上的代码覆盖率
我们将利用之前的代码结构,在云端上实现代码覆盖率。在此,我们将为电子商务测试平台上的注册操作编写测试用例。然后,我们将在基于云的测试平台上执行pytest测试。
测试将基于注册操作运行,同时不提供一些参数。这可能涉及未填写某些表单字段或提交无效的电子邮件地址等情况。
测试场景 1:
使用无效的电子邮件地址和缺少的字段提交注册表单。
测试场景 2:
使用所有字段都正确填写的表单提交(成功注册)。
我们还将了解如何通过添加缺失的参数来扩展代码覆盖率。以下是我们的Selenium自动化脚本:
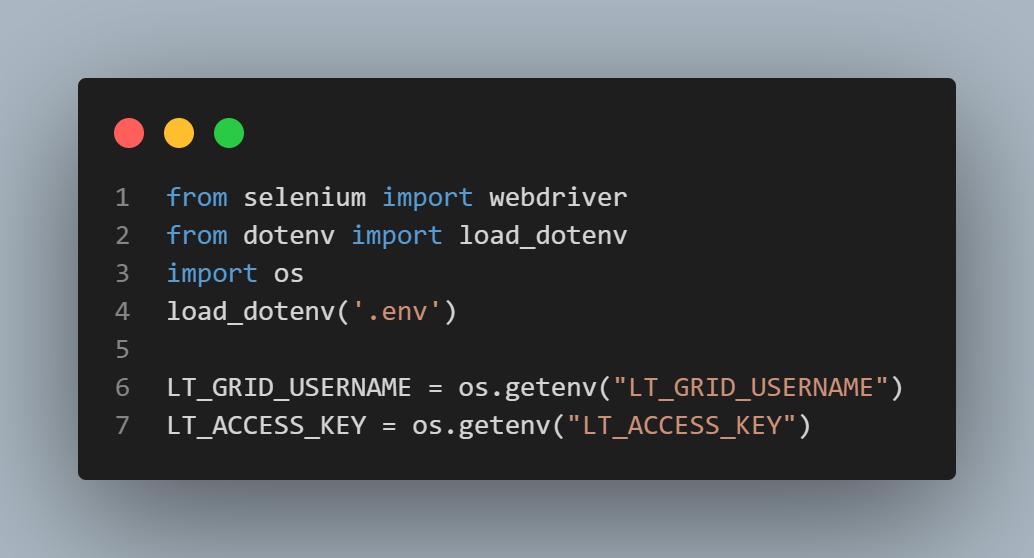
Filename: setup/setup.py
from selenium import webdriver
from dotenv import load_dotenv
import os
load_dotenv('.env')
LT_GRID_USERNAME = os.getenv("LT_GRID_USERNAME")
LT_ACCESS_KEY = os.getenv("LT_ACCESS_KEY")
desired_caps = {
'LT:Options' : {
"user" : os.getenv("LT_GRID_USERNAME"),
"accessKey" : os.getenv("LT_ACCESS_KEY"),
"build" : "Test Coverage Idowu",
"name" : "Firefox coverage demo2",
"platformName" : os.getenv("TEST_OS")
},
"browserName" : "FireFox",
"browserVersion" : "125.0",
}
gridURL = "https://{}:{}@hub.lambdatest.com/wd/hub".format(LT_GRID_USERNAME, LT_ACCESS_KEY)
class testSettings:
def __init__(self) -> None:
self.driver = webdriver.Remote(command_executor=gridURL, desired_capabilities= desired_caps)
def testSetup(self):
self.driver.implicitly_wait(10)
self.driver.maximize_window()
def tearDown(self):
if (self.driver != None):
print("Cleaning the test environment")
self.driver.quit()
代码详解:
首先,导入Selenium WebDriver以配置测试驱动程序。从“设置”>“帐户设置”>“密码与安全”中获取您的网格用户名和访问密钥(分别作为LT_GRID_USERNAME和LT_GRID_ACCESS_KEY传递)。
desired_caps 是一个包含测试套件所需功能的字典。它详细说明了您的用户名、访问密钥、浏览器名称、版本、构建名称以及运行驱动程序的平台类型。

接下来是 gridURL。我们使用之前声明的访问密钥和用户名来访问它。然后,我们将此URL和所需的功能传递给__init__函数内部的driver属性。
编写一个testSetup()方法以启动测试套件。它使用implicitly_wait()函数暂停等待DOM加载元素。然后,它使用maximize_window()方法来展开所选的浏览器窗口。
然而,tearDown()方法用于停止测试实例并使用quit()方法关闭浏览器。
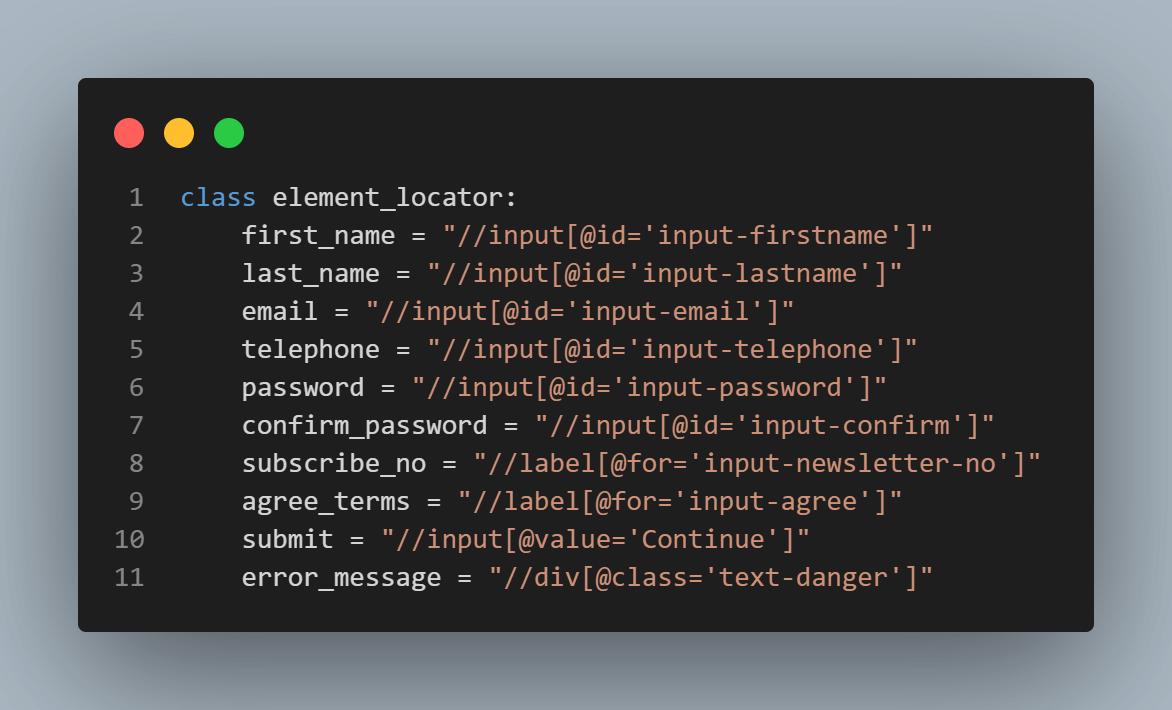
Filename: locators/locators.py
from selenium.webdriver.common.by import By
from selenium.common.exceptions import NoSuchElementException
class element_locator:
first_name = "//input[@id='input-firstname']"
last_name = "//input[@id='input-lastname']"
email = "//input[@id='input-email']"
telephone = "//input[@id='input-telephone']"
password = "//input[@id='input-password']"
confirm_password = "//input[@id='input-confirm']"
subscribe_no = "//label[@for='input-newsletter-no']"
agree_terms = "//label[@for='input-agree']"
submit = "//input[@value='Continue']"
error_message = "//div[@class='text-danger']"
locator = element_locator()
class registerUser:
def __init__(self, driver) -> None:
self.driver=driver
def error_message(self):
try:
return self.driver.find_element(By.XPATH, locator.error_message).is_displayed()
except NoSuchElementException:
print("All code in registration test covered")
def test_getWeb(self, URL):
self.driver.get(URL)
def test_getTitle(self):
return self.driver.title
def test_fillFirstName(self, data):
self.driver.find_element(By.XPATH, locator.first_name).send_keys(data)
def test_fillLastName(self, data):
self.driver.find_element(By.XPATH, locator.last_name).send_keys(data)
def test_fillEmail(self, data):
self.driver.find_element(By.XPATH, locator.email).send_keys(data)
def test_fillPhone(self, data):
self.driver.find_element(By.XPATH, locator.telephone).send_keys(data)
def test_fillPassword(self, data):
self.driver.find_element(By.XPATH, locator.password).send_keys(data)
def test_fillConfirmPassword(self, data):
self.driver.find_element(By.XPATH, locator.confirm_password).send_keys(data)
def test_subscribeNo(self):
self.driver.find_element(By.XPATH, locator.subscribe_no).click()
def test_agreeToTerms(self):
self.driver.find_element(By.XPATH, locator.agree_terms).click()
def test_submit(self):
self.driver.find_element(By.XPATH, locator.submit).click()
首先,将Selenium的By对象导入到文件中,以声明用于DOM的定位器模式。我们将使用NoSuchElementException来检查DOM中是否存在错误消息(在输入无效的情况下)。
接下来,声明一个类来保存WebElement。然后,创建另一个类来处理注册表单的网页操作。
element_selector类包含WebElement的位置。每个位置都使用XPath定位器。
registerUser类接受driver属性以启动网页操作。在实例化registerUser类时,您将从setup类中获取driver属性。
registerUser类中的error_message方法有两个作用。首先,当测试尝试使用不可接受的输入提交注册表单时,它会在DOM中检查无效字段的错误消息。此检查每次都在try块内运行,因此测试无论如何都会覆盖它。
其次,如果在DOM中找到输入错误消息元素,它将运行try块中的代码。这可以防止except块运行,并将其标记为非覆盖代码。
否则,Selenium将引发NoSuchElementException。这将强制测试在except块中记录打印内容并将其标记为覆盖代码。这感觉像是一种反向策略。但它有助于代码覆盖率捕获更多场景。
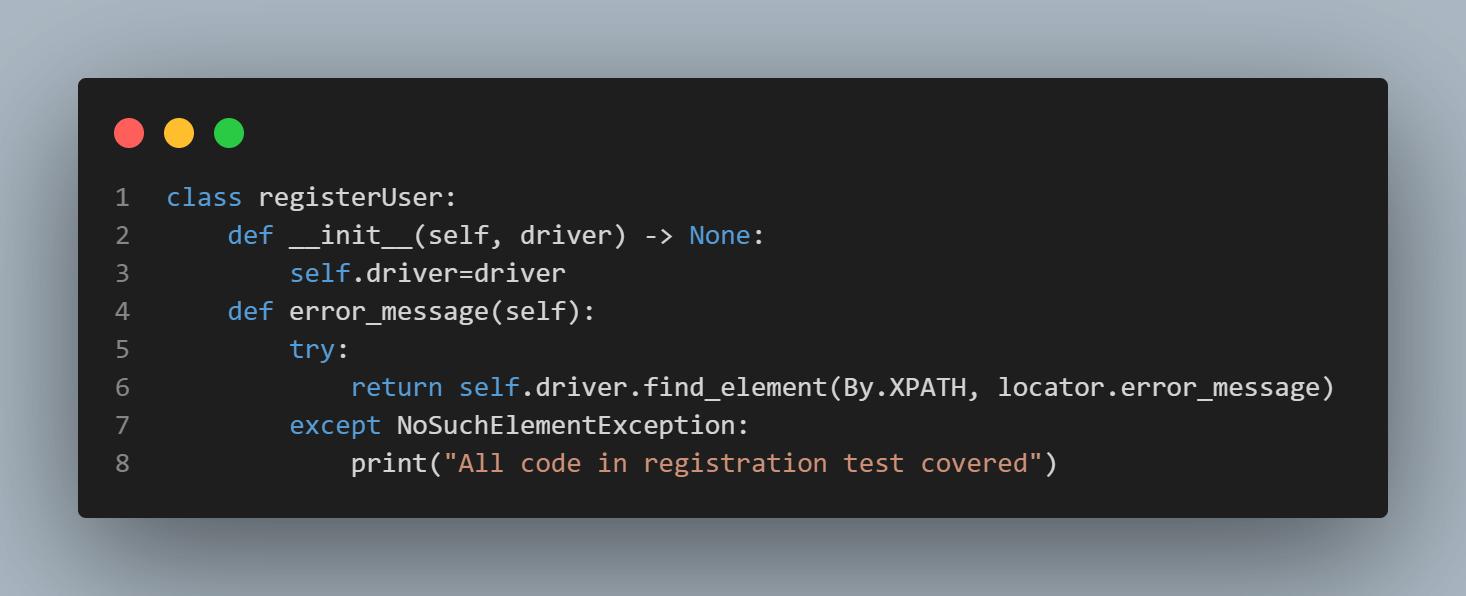
因此,除了捕获遗漏的字段(即未包含在测试执行中的网页操作方法)之外,它还确保测试考虑了无效的电子邮件地址或空字符串输入。
因此,如果错误消息显示在DOM中,该方法将返回错误消息元素。否则,Selenium将引发NoSuchElementException,迫使测试记录打印的消息。
该类中的其余方法是为element_locator类中的定位器声明的网页操作。除了需要点击操作的字段外,其他类方法接受一个数据参数,即输入到输入字段中的字符串。
但是,首先,为代码覆盖场景创建一个测试运行器文件。您将执行此文件以运行测试并计算代码覆盖率。
Filename: run_coverage/run_coverage.py
# Import the Pytest coverage plugin:
import coverage
# Start code coverage before importing other modules:
cov = coverage.Coverage()
cov.start()
# Main code to be covered----------:
import sys
sys.path.append(sys.path[0] + "/..")
from testscenario.scenarioRun import test_registration
registration = test_registration()
registration.it_should_register_user()
# Stop code coverage and save the output in a reports directory---------:
cov.stop()
cov.save()
cov.html_report(directory='coverage_reports')
上述代码首先导入了coverage模块。接下来,声明一个coverage类的实例,并在代码顶部调用start()方法。一旦代码覆盖率检测开始,从scenarioRun.py中导入test_registration类,并将其实例化为registration。
test_registration类中的it_should_register_user方法是一个测试方法,用于执行测试用例(您将在下一节中看到此类)。使用cov.stop()来关闭代码覆盖率检测过程。然后,使用cov.save()来捕获覆盖率报告。
cov.html_report()方法将覆盖率结果写入到指定目录(coverage_reports)内的HTML文件中。
运行该文件将执行测试并生成覆盖率报告。
现在,让我们调整scenarioRun.py中的web操作方法来查看每个场景的代码覆盖率差异。
测试场景1: 提交包含无效电子邮件地址和一些缺失字段的注册表单。
Filename: testscenario/scenarioRun.py
import sys
sys.path.append(sys.path[0] + "/..")
from locators.locator import registerUser
from setup.setup import testSettings
import unittest
from dotenv import load_dotenv
import os
load_dotenv('.env')
setup = testSettings()
test_register = registerUser(setup.driver)
E_Commerce_palygroud_URL = "https:"+os.getenv("E_Commerce_palygroud_URL")
class test_registration(unittest.TestCase):
def it_should_register_user(self):
setup.testSetup()
test_register.test_getWeb(E_Commerce_palygroud_URL)
title = test_register.test_getTitle()
self.assertIn("Register", title, "Register is not in title")
test_register.test_fillEmail("testrs@gmail")
test_register.test_fillPhone("090776632")
test_register.test_fillPassword("12345678")
test_register.test_fillConfirmPassword("12345678")
test_register.test_submit()
test_register.error_message()
setup.tearDown()
注意导入的内置和第三方模块。我们首先导入之前编写的registerUser和testSettings类。testSettings类包含用于设置和关闭测试的testSetup()和tearDown()方法。我们将这个类实例化为setup。
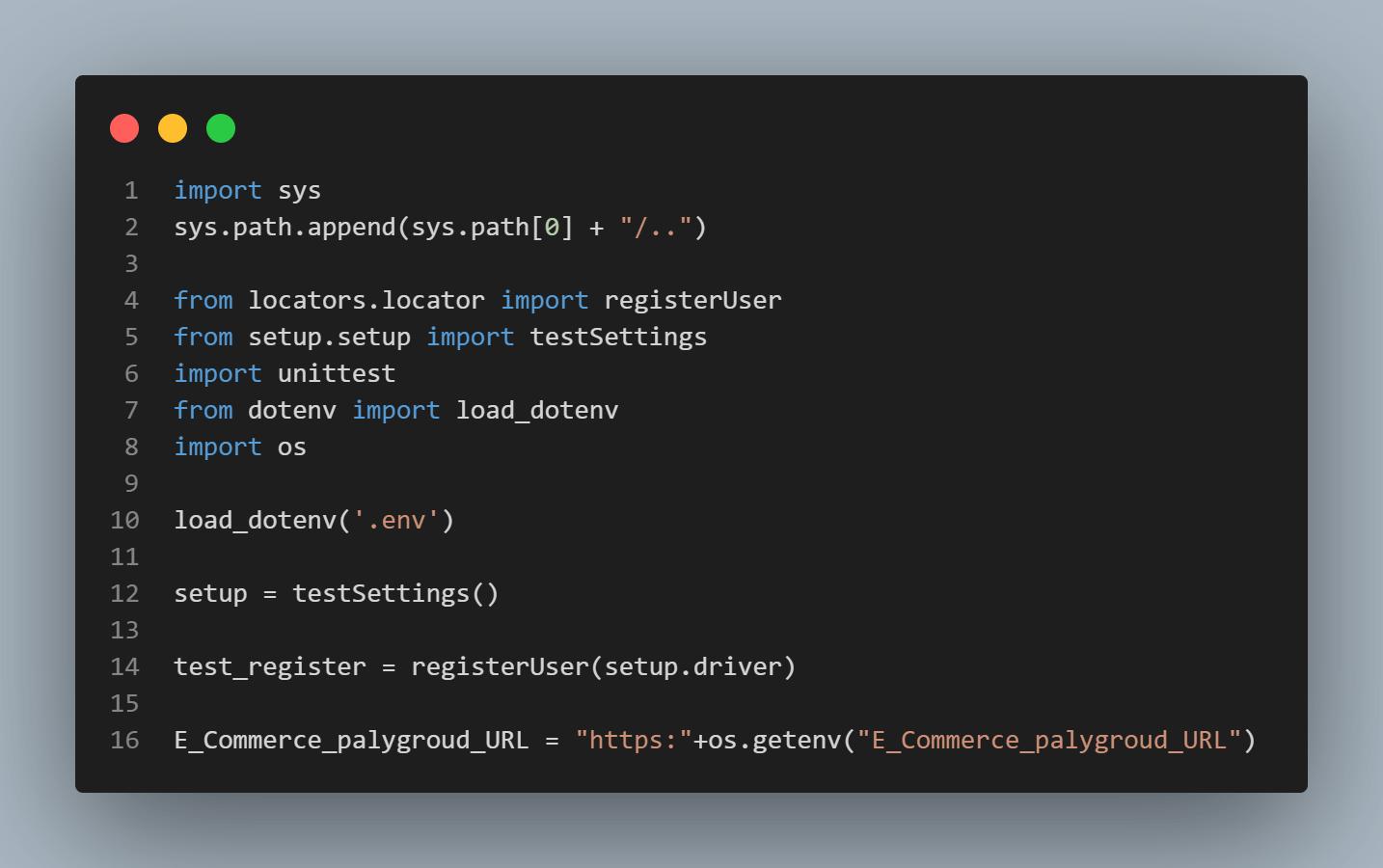
如下所示,registerUser类使用setup.driver属性实例化为test_register。dotenv包允许您从环境变量中获取测试网站的URL。
testSetup()方法启动测试用例(it_should_registerUser方法)并准备测试环境。接下来,我们使用test_getWeb()方法启动网站。该方法接受之前声明的网站URL。从unittest测试继承的属性assertIn检查声明的字符串是否在标题中。使用setup.tearDown()方法来关闭浏览器并清理测试环境。
如前所述,测试用例的其余部分省略了registerUser类中的一些方法,以观察它们对代码覆盖率的影响。
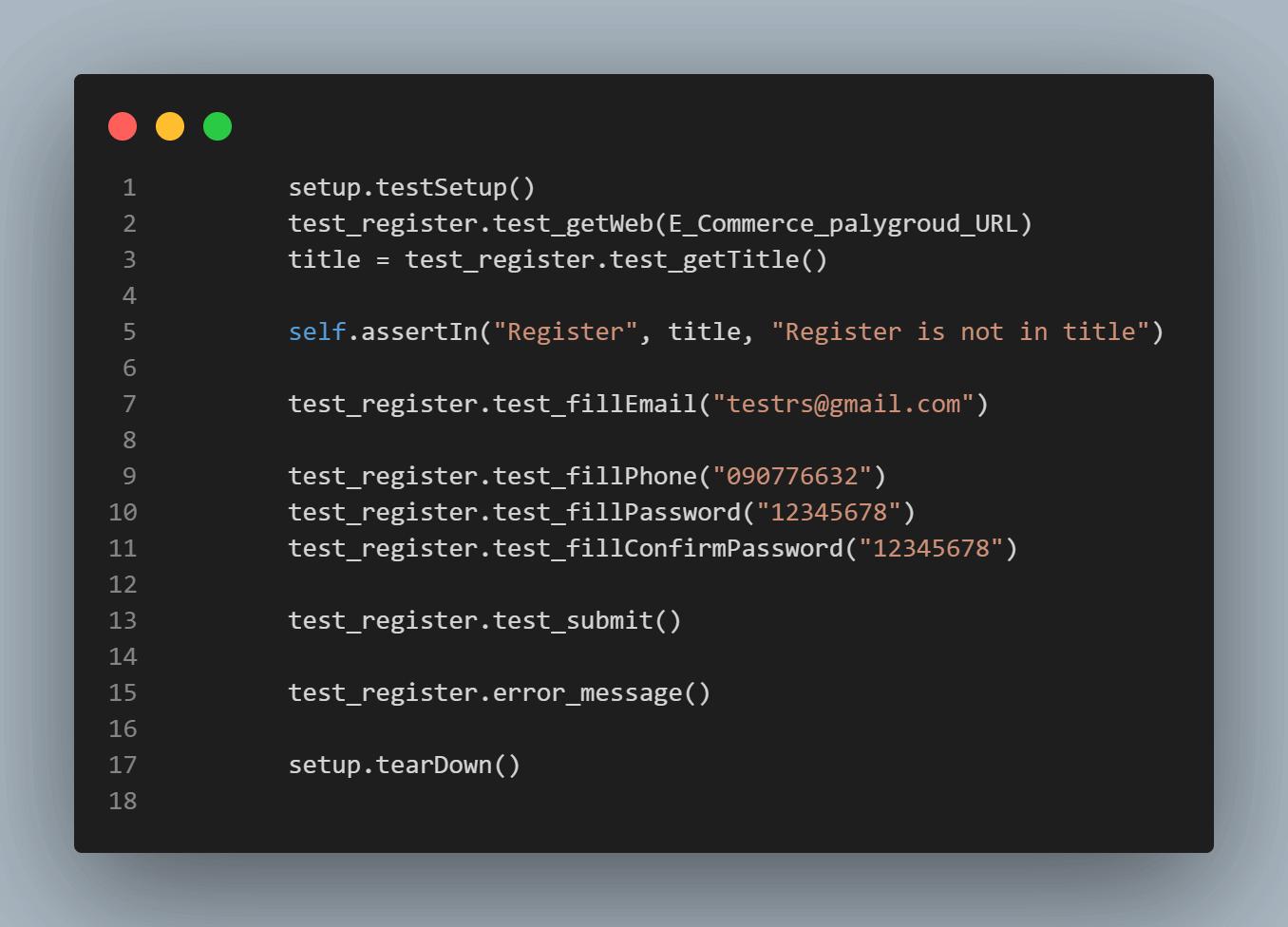
测试执行:
要执行测试和代码覆盖率分析,请进入test_run_coverage文件夹,并使用pytest运行run_coverage.py文件:
pytest
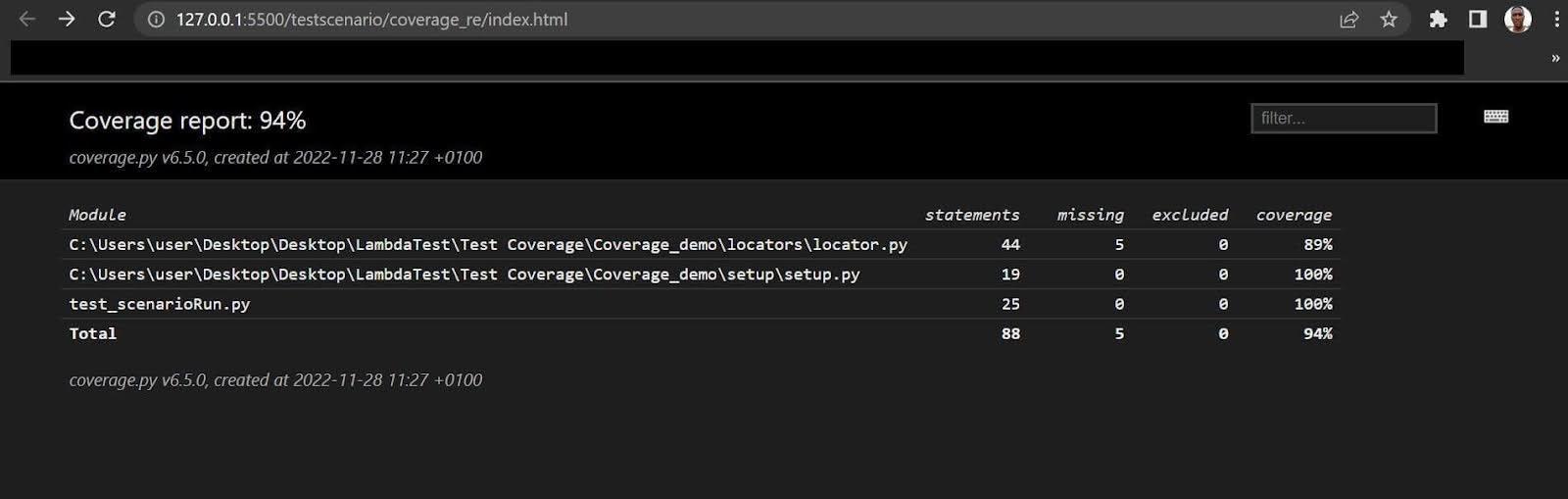
代码成功运行后,打开coverage_reports文件夹,并通过浏览器打开index.html文件。代码覆盖率显示为94%,如下所示。
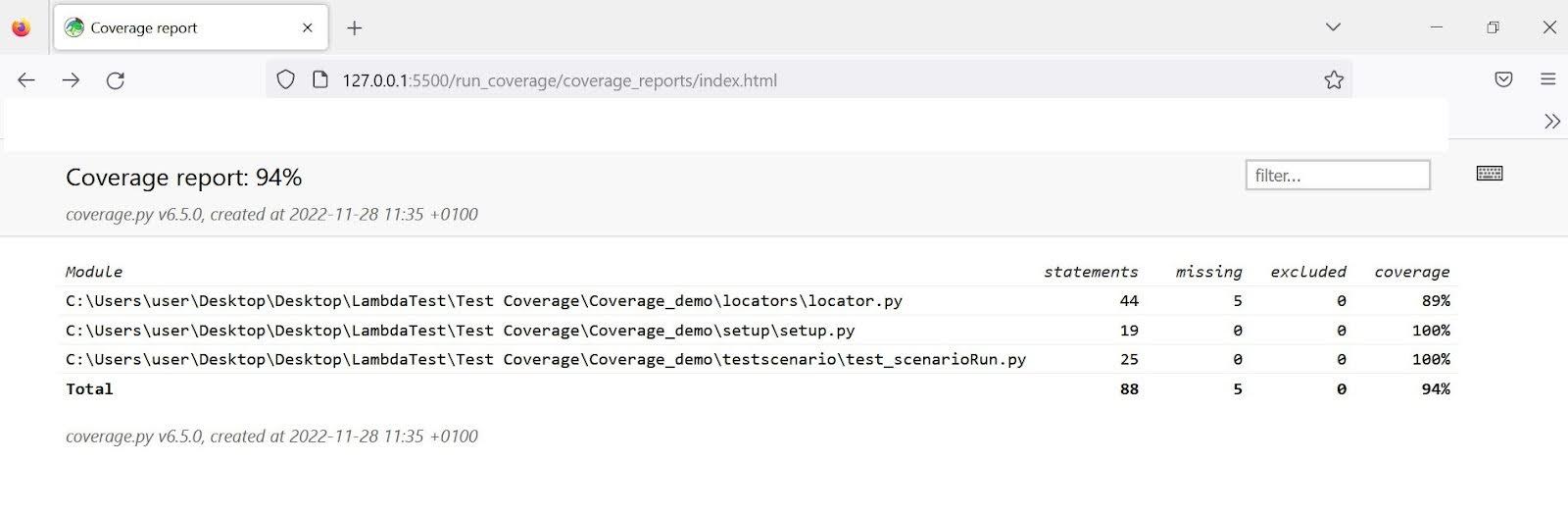
尽管其他测试文件的读取率为100%,但locator.py的代码覆盖率仅为89%,导致整体得分降低至94%。在运行测试时,我们省略了一些网页操作,并输入了一个无效的电子邮件地址。
打开locator.py可以更多地了解缺失的步骤(以红色高亮显示),如下所示。
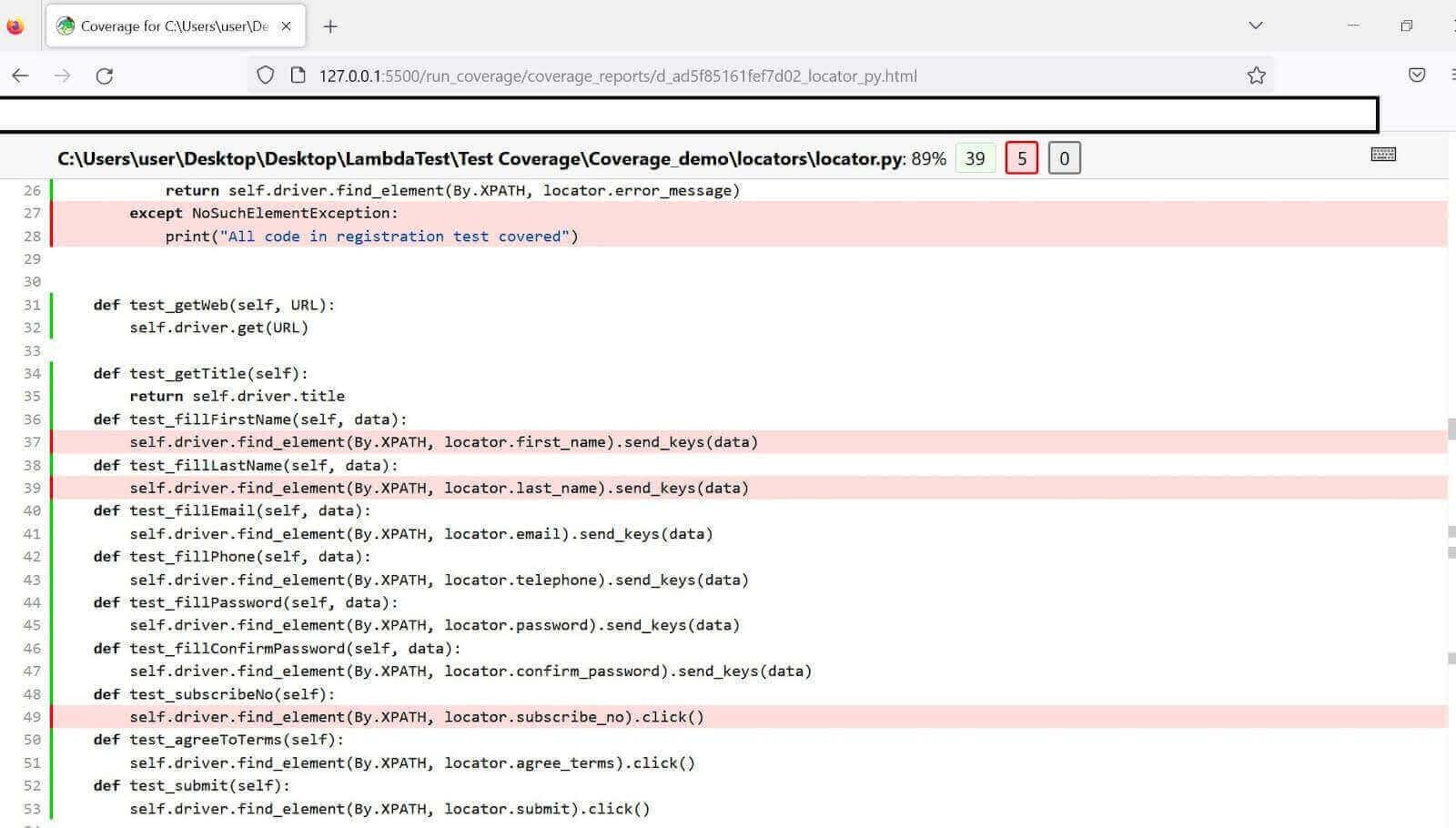
尽管您可能期望覆盖率能够标记出test_fillEmail()方法,但实际上它并没有这样做,因为测试中提供了一个电子邮件地址(尽管该地址无效)。except块是无效参数的指示器,并且它仅在输入错误消息元素不在DOM中时才会运行。
由此可见,由于无效输入导致输入错误消息出现在DOM中,因此这次测试标记了except块。
测试套件在云网格上运行,测试视频中出现了一些红色标记,如下所示。
测试场景2: 提交所有字段均正确填写的表单(成功注册)。
import sys
sys.path.append(sys.path[0] + "/..")
from locators.locator import registerUser
from setup.setup import testSettings
import unittest
from dotenv import load_dotenv
import os
load_dotenv('.env')
setup = testSettings()
test_register = registerUser(setup.driver)
E_Commerce_palygroud_URL = "https:"+os.getenv("E_Commerce_palygroud_URL")
class test_registration(unittest.TestCase):
def it_should_register_user(self):
setup.testSetup()
test_register.test_getWeb(E_Commerce_palygroud_URL)
title = test_register.test_getTitle()
self.assertIn("Register", title, "Register is not in title")
test_register.test_fillFirstName("Idowu")
test_register.test_fillLastName("Omisola")
test_register.test_fillEmail("testrs@gmail.com")
test_register.test_fillPhone("090776632")
test_register.test_fillPassword("12345678")
test_register.test_fillConfirmPassword("12345678")
test_register.test_subscribeNo()
test_register.test_agreeToTerms()
test_register.test_submit()
test_register.error_message()
setup.tearDown()
测试场景2的代码结构和命名约定与测试场景1相似。然而,我们已经扩展了测试的覆盖范围,以涵盖测试场景2中的所有测试步骤。像前一个场景一样导入所需的模块。然后,分别将testSettings和registerUser类实例化为setup和test_register。
为了获得全面的测试套件,请确保您执行了registerUser类中的所有测试步骤,如下所示。我们期望这能生成100%的代码覆盖率。
测试执行:
进入run_coverage文件夹,并运行pytest命令来执行test_run_coverage.py文件:
pytest
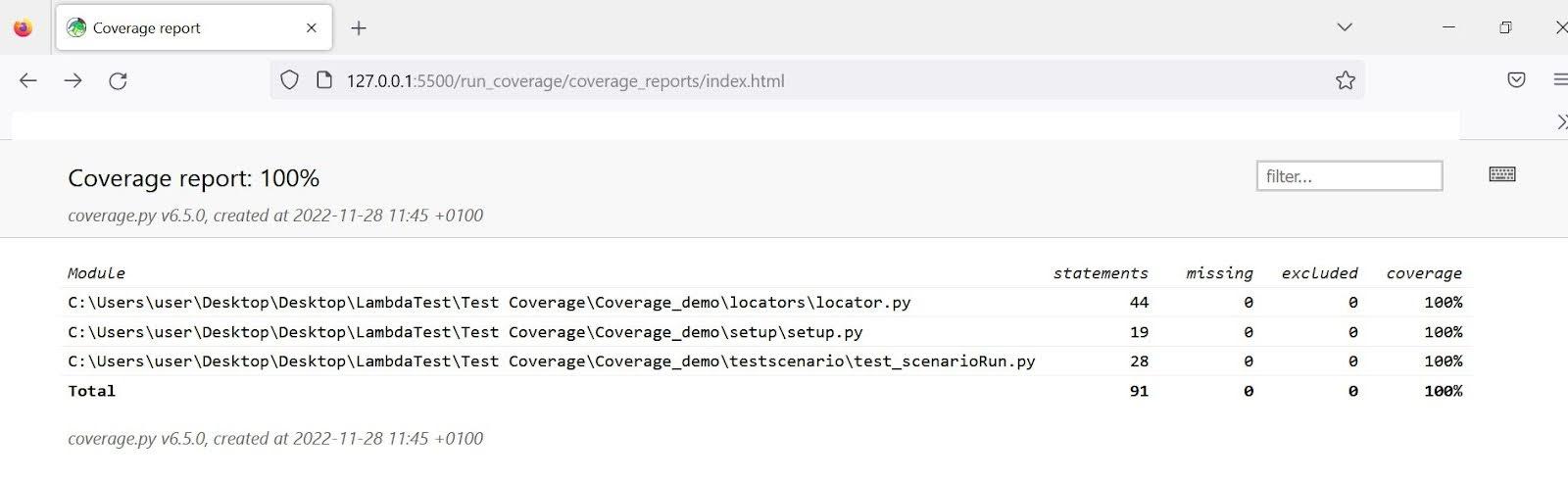
通过浏览器打开覆盖率报告中的index.html文件,以查看您的pytest代码覆盖率报告。现在,它显示为100%,如下所示。这意味着测试没有遗漏任何网页操作。
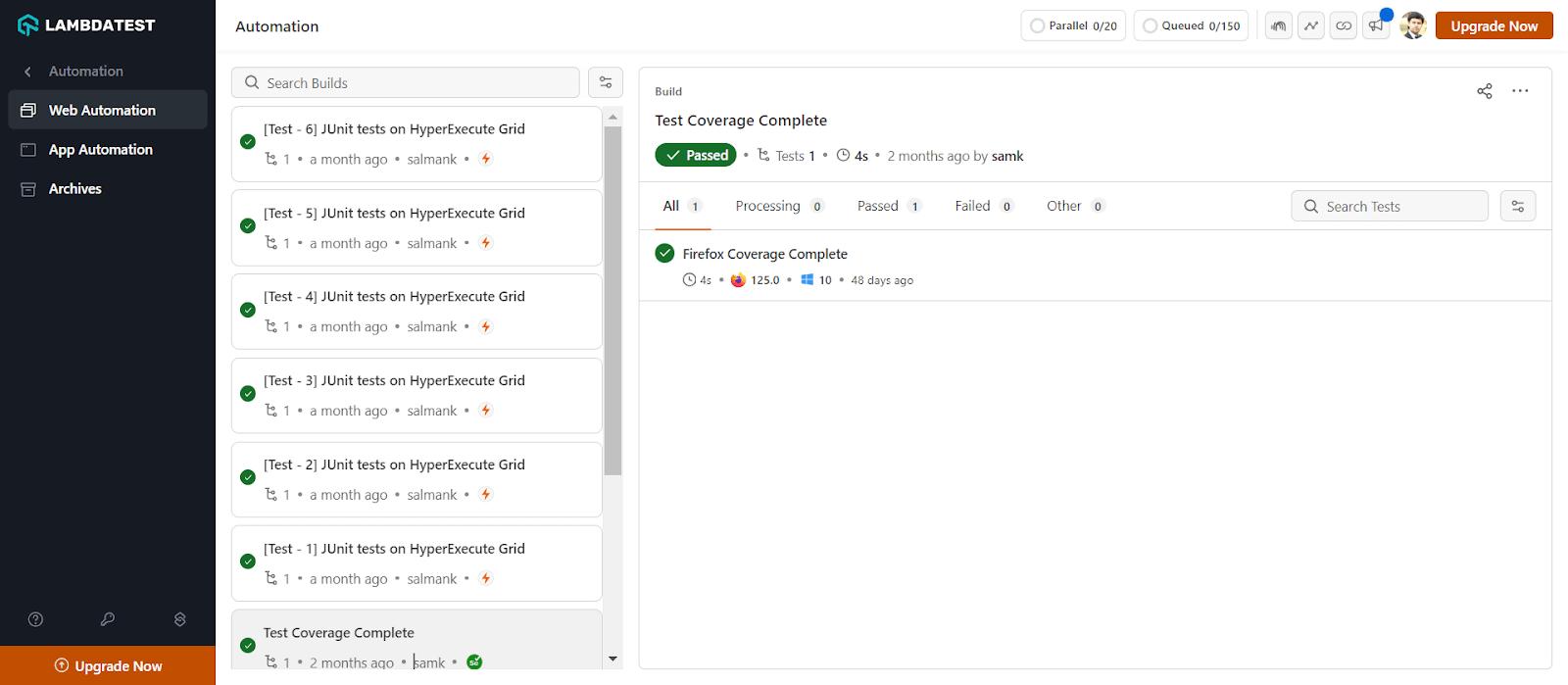
以下是测试套件在云上的执行情况:
结论
手动审核你的测试套件可能是一项艰巨的任务,特别是如果你的应用程序代码库很大。在进行Selenium Python测试时,使用专用的代码覆盖率工具可以提高测试的生产率,因为它可以帮助你标记未测试的代码部分,从而轻松发现潜在的错误。虽然你仍然需要人工输入来确定测试需求和覆盖率,但进行代码覆盖率分析可以为你提供明确的方向。
