
软件测试是现代软件开发的基石,但它仍然是资源密集型且重复性高的任务之一。为了应对这一挑战,我们的团队开发了一种基于人工智能驱动的单元测试代码生成器,旨在简化测试工作流、提高代码质量并节省开发者的宝贵时间。以下是对该工具的详细介绍,以及它的革新性所在。
介绍
AI单元测试生成器是一款创新工具,旨在自动生成软件项目的单元测试用例,从而简化这一过程。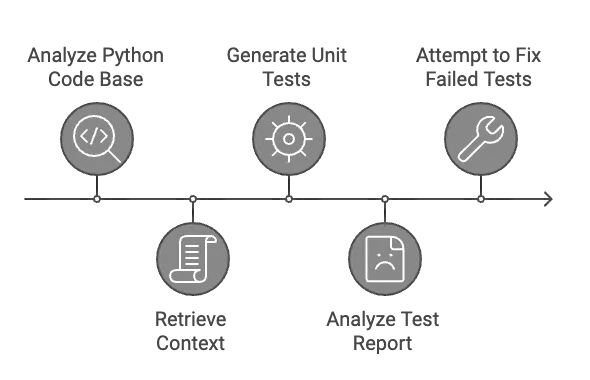
架构概述
我们的系统采用了基于智能体的架构设计。在这种架构中,每个智能体在其特定的领域内运行,同时与系统的其他组件协作,专注于特定的任务并承担相应的责任。这种结构确保了每个过程环节的专业化和高效性,从获取上下文信息到自我修复的全过程。
下图展示了系统的核心组件。
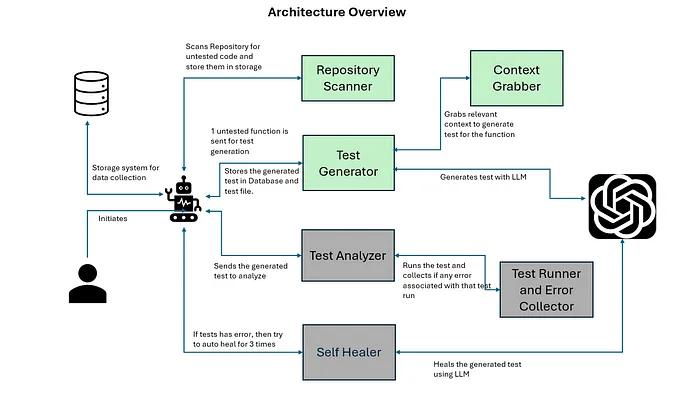
架构的关键组件
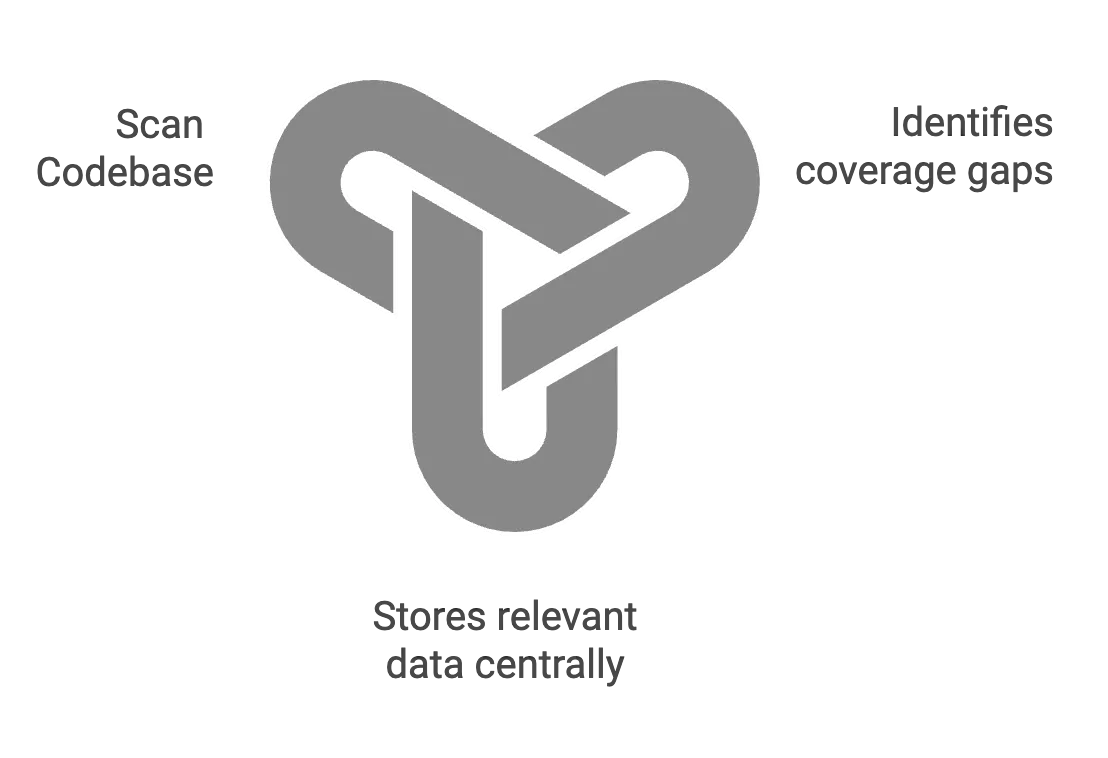
仓库扫描器(Repository Scanner) 该模块会扫描代码库,查找未测试的函数,并将相关数据存储在中央仓库中。通过识别测试覆盖范围的空白区域,确保我们将注意力集中在最需要单元测试的地方。
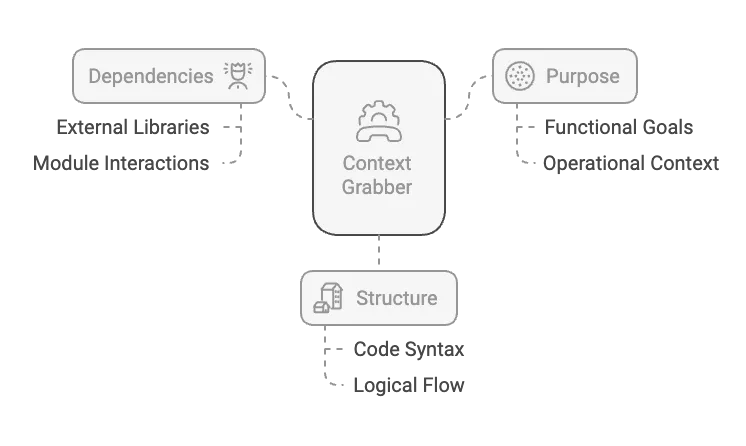
上下文抓取器(Context Grabber) 上下文对于有效的测试用例生成至关重要。此组件会检索有关未测试的函数的关键信息,如其依赖项、功能和结构。
测试生成智能体(Test Generator Agent) 由大型语言模型(LLM)驱动,测试用例生成器最初从上下文抓取器获取待测试代码的上下文,并为特定函数创建全面的单元测试,涵盖所有可能的场景。这些测试会同时存储在数据库记录和物理测试文件中,以便供未来使用。

测试运行器与错误收集器(Test Runner and Error Collector) 一旦生成了测试,系统会执行它们以验证其正确性。所有遇到的错误会被收集并报告,供进一步分析。
测试分析智能体(Test Analyzer Agent) 该模块评估测试运行的结果,确保准确性,并提供有关错误或失败的详细报告。

自愈智能体(Self-Healer Agent) 我们架构中最具创新性的部分是自愈智能体。它利用AI自动处理失败的测试,通过评估和分析错误报告来启动自我修复周期,学习并适应每一次尝试。它会重构单元测试,并智能地应用修复方案。
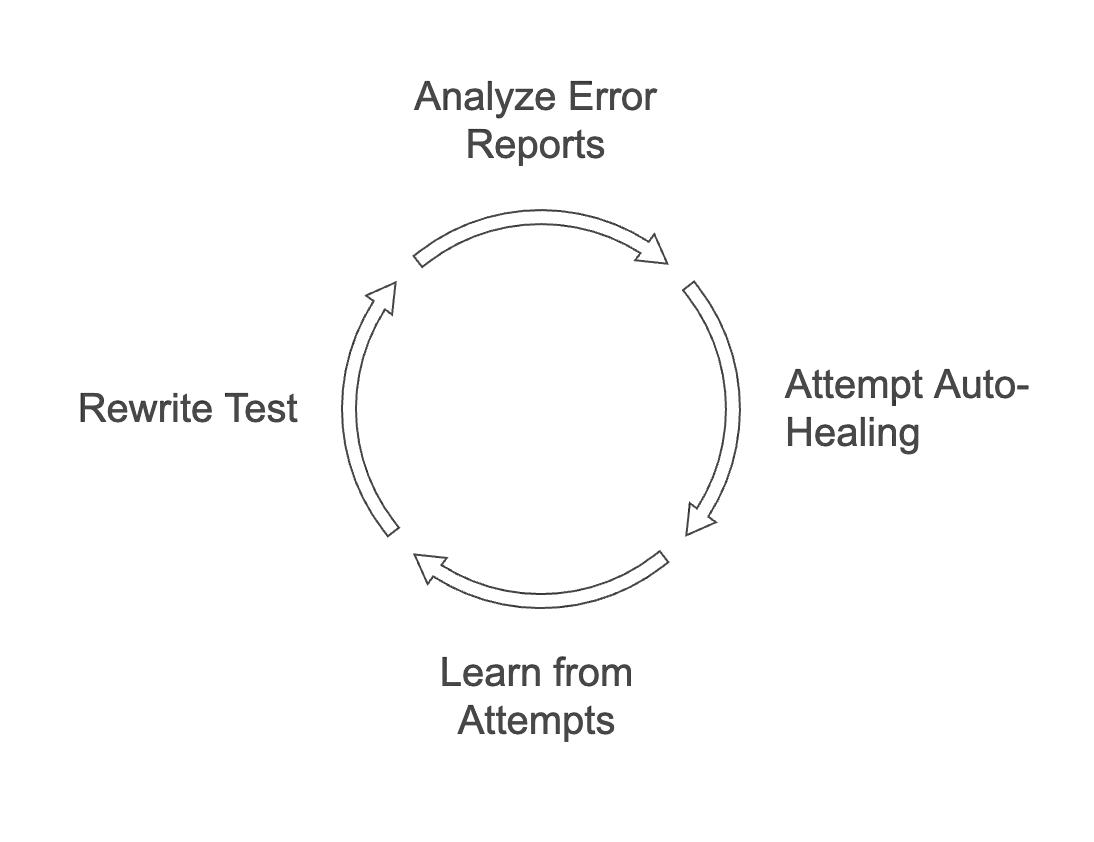
通过迭代优化和提示工程实现准确性
在设计生成单元测试的系统时,我们意识到,要确保生成的测试准确且相关,需要给LLM(大语言模型)提供清晰的指令。系统的早期版本生成的测试往往比较通用或不完整,这突出了需要更精确指导的必要性。
我们精心设计了详细的提示,指导LLM生成高准确性和高相关性的单元测试。我们的做法包括多个迭代改进、提示策略和微调步骤,以达到所期望的准确性和覆盖范围。这个过程可以分解为以下几个步骤:
理解挑战
1、清晰的任务定义
我们设计了高度详细和结构化的提示,以便向LLM传达我们的期望。提示的开头给出了明确的目标:
“你的任务是生成一个清晰简洁的函数描述和相应的单元测试。”
这为LLM设定了框架:LLM的任务不仅是生成代码,还需要确保生成内容的清晰度。
2、顺序指令
我们实验并应用了多种提示工程技巧,以有效指导LLM。以下示例提示指示LLM按特定顺序执行步骤,这是一个关键的提示,帮助LLM正确地进行推理过程。提示如下:
“按顺序执行指令。”
这确保了LLM不会跳过步骤或混合不同阶段的工作。
3、详细的“单元测试生成阶段”
我们在提示中融入了结构良好的单元测试示例,作为LLM的参考。专门有一部分解释了如何生成单元测试并为测试创建模拟外部依赖的内容:
- 使用pytest和mocker。
- 对于异步函数,使用AsyncMock。
- 精确生成同步和异步函数的pytest.fixture(并且指示不要在fixture内部使用await)。
- 确保某些字段和模式细节的正确性。
- 小心处理异步方法,尤其是SQLAlchemy,避免出现TypeError或错误的mock。
- 编写带有内联文档(注释)的单元测试,以解释测试的目的和逻辑。
这些限制确保了最终输出的准确性,并与Python异步代码库中的常见测试模式对齐。
4、“重要指令”部分
这一部分规定了格式和风格要求:
- 按照给定的输出格式,包括commoncode、test1和test2等JSON键。
- 转义代码片段中的特殊字符。
- 包括所有必要的导入。
- 使用示例作为参考模板。
提到转义特殊字符并将代码放入JSON结构中是一个关键细节。这确保了LLM输出的代码正确转义,从而能够安全地集成到其他系统或文档中,避免格式问题。
示例和模板
提示中提供了两个示例。分别展示:
- 如何构造包含导入、fixture和公共配置的commoncode块。
- 如何为给定函数构造test1和test2。
通过提供这些示例,提示有效地引导LLM按照期望的输出格式和风格生成内容。LLM可以将这些示例作为模板或模式来指导自己的输出。
5、最终期望格式
LLM的最终响应应该是一个包含三个键:commoncode、test1和test2的JSON对象,每个键对应一个作为单个转义字符串的代码片段。这是一个附加的约束,确保输出可以机器解析并易于处理。
通过这个迭代优化和提示工程过程,我们显著提高了生成单元测试的准确性。现在,系统生成的测试不仅全面且可靠,而且符合实际开发标准。
整体工作原理
初始化:
系统从用户发起请求开始,扫描代码库中的未测试代码。
测试生成:
系统识别出未测试的函数后,由测试生成器处理,LLM为每个函数生成高质量的测试用例。
执行与分析:
测试运行器执行生成的测试,而错误收集器标记出问题。测试分析器详细评估这些错误并生成错误报告。
修复:
最终,自我修复功能启动,接收错误报告并使用LLM自动尝试解决问题。如果修复在三次尝试后失败,系统会向用户提供详细报告,供开发人员检查错误并防止AI陷入无限循环。
演示:见证AI的实际操作
要真正欣赏我们的AI单元测试代码生成器的能力,请观看以下演示视频,展示其核心功能:
1. 自动化单元测试生成
在此视频中,您将看到系统如何扫描代码库,提取相关上下文,并在几秒钟内生成全面的单元测试。
2. 模拟与自我修复功能演示
第二个演示展示了系统如何处理涉及模拟的复杂场景,并演示了自动修复功能如何修正测试错误。
重要意义
测试自动化工具并不新鲜,但将它们与AI结合,进行上下文感知的测试生成和自我修复功能,是一个革命性的突破。我们的系统显著减少了手动干预,加速了开发周期,并确保了代码质量的健壮性。
开发人员现在可以专注于构建功能,而不必编写模板化的测试代码。此外,自我修复功能确保测试会随着代码的演进而自适应调整,完美适用于敏捷和DevOps工作流程。
未来规划
随着我们不断改进AI单元测试生成器,我们的愿景是扩展其能力,以处理更多复杂和多样的场景。未来,我们计划支持外部实体,如API和数据管道的集成,能够跨互联系统进行无缝测试。此外,我们还计划使代码库更加稳健,使其能够处理使用面向对象编程(OOP)构建的Python代码库,并为类和方法生成测试。我们还期待引入集成测试,与单元测试一起,确保单个组件及其交互都经过严格验证。这些进展将使我们的工具成为现代软件测试的全面解决方案。
结论
AI单元测试生成器代表了软件开发实践的重大飞跃。通过自动化测试创建、执行和自我修复,它使开发人员能够更快地专注于创新,并交付强健的高质量软件。这项工作体现了测试的未来——智能、高效且适应性强。
在Ki Reply GmbH,我们为站在这项创新的前沿而感到自豪。这个项目的实现离不开我们团队成员Pratik Saha和Shafait Azam的辛勤工作和奉献。我们将继续推动AI驱动开发的边界,为全球开发者社区塑造下一代工具。
