

一个多月前,我与几位 DeepEval 用户进行交流,发现他们明显分为两类:一类对开箱即用的指标(metrics)感到满意,另一类则不然。
需要说明的是,DeepEval 是一个我过去一年一直在开发的开源 LLM 评测框架,其所有 LLM 评测指标都采用 以 LLM 作为评委(LLM-as-a-judge) 的方式。这个项目的月下载量已接近 50 万次,GitHub star 数接近 5000(编辑注:现在已经5.4K+)。如今,工程师们每天用它运行超过 80 万次评测,对 RAG 流程、智能体和聊天机器人等 LLM 应用进行单元测试。
对这些指标不满意的用户有一个简单的原因:这些指标不适用于他们的用例,且由于完全依赖 LLM 作为评委,确定性不足。这是一个严重的问题,因为 DeepEval 的核心目标就是消除工程师自行构建评测指标和流程的需求。如果我们的内置指标不可用,用户仍需自行构建,我们的存在就失去了意义。
随着与更多用户交流,我发现他们的代码库中充斥着数百行提示词和逻辑代码,只是为了调整指标以更贴近需求、增强确定性。显然,用户不仅在自定义指标——他们正在弥补我们提供的功能的不足。
这引出了一个关键问题:如何让 DeepEval 的内置指标足够灵活和确定,从而减少团队自行开发的需求?
剧透警告——解决方案大致如下:
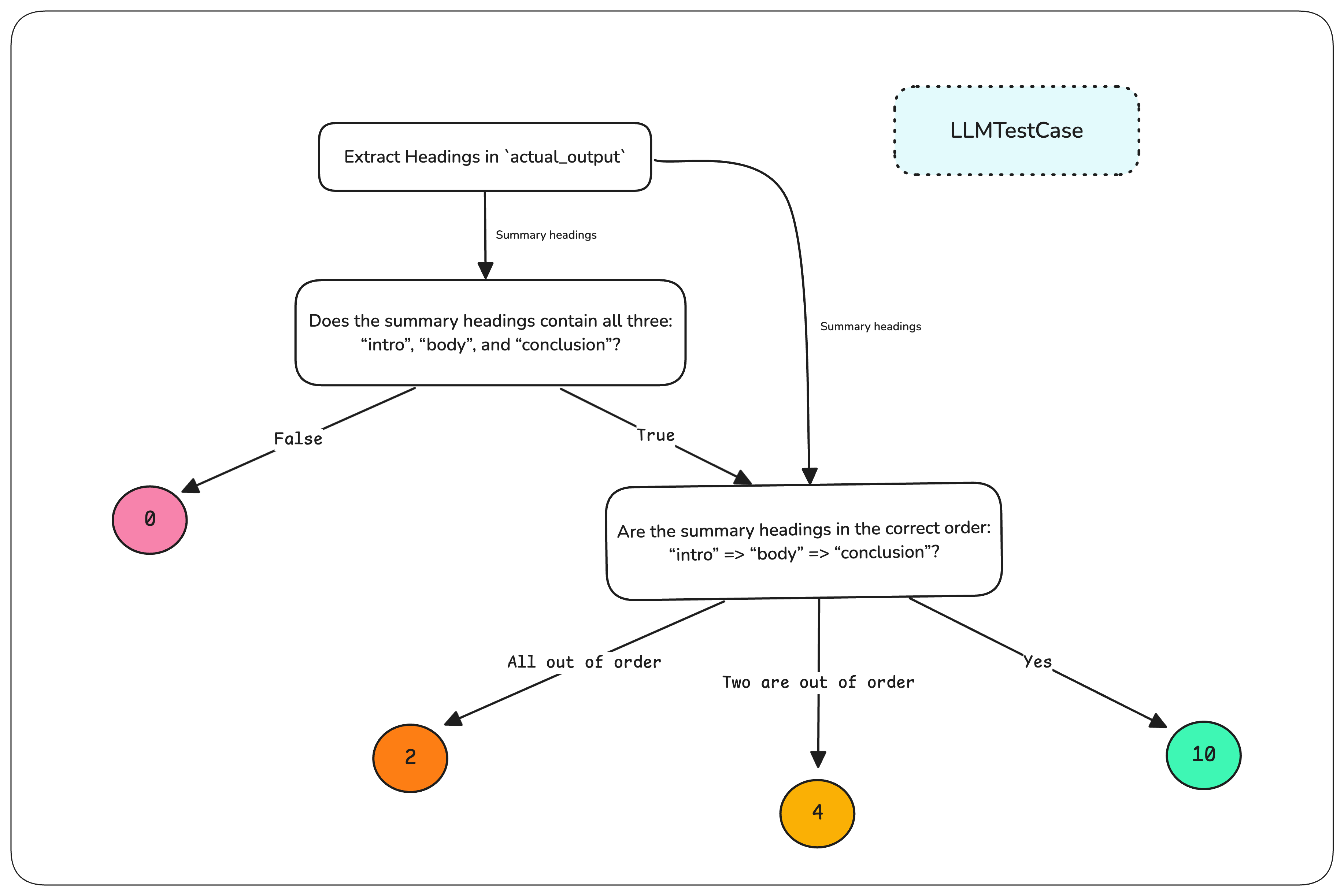 图1. 决策树驱动的 LLM 确定性评测
图1. 决策树驱动的 LLM 确定性评测
自定义指标的问题
为了更好地说明问题,DeepEval 的默认指标包括上下文召回率(contextual recall)、答案相关性(answer relevancy)、答案正确性(answer correctness)等,这些标准通用且相对稳定。我称其为稳定,是因为这些指标大多基于问答生成(QAG)技术。由于 QAG 将判断约束为封闭式问题的二元“是”或“否”,随机性空间极小。
注意:我们并未使用统计型评分作为 LLM 评测指标(编辑注:作者将评分分为两种,如下图所示,摘自作者另一篇文章)。
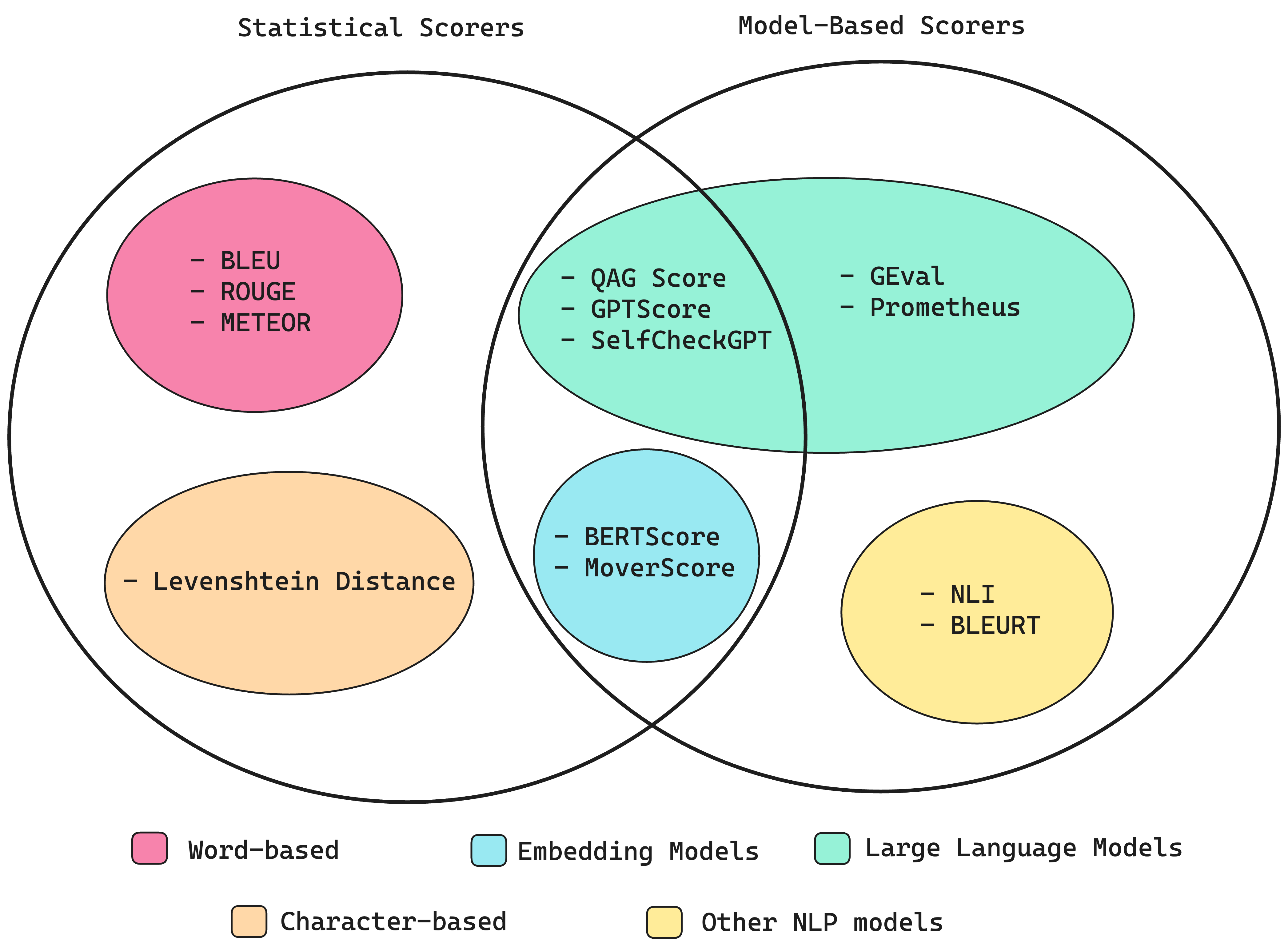
我认为,像答案相关性这样的指标本质上是宽泛的。虽然难以绝对定义“相关性”,但只要指标能提供合理解释,多数人愿意接受。这些指标有效的另一个原因是背后有清晰直接的公式,用户是否喜欢某个指标,通常取决于他们是否认同其计算算法。
例如,上文提到的上下文召回率指标用于评测 RAG 的检索器。这个指标的用武之地是:对于 LLM 应用的给定输入,判断检索器获取的文本块是否足以生成理想的预期结果。其算法简单直观:
- 用 LLM 评委从期望结果中提取所有关键陈述
- 用 LLM 评委判断在检索到的上下文中能够支持生成关键陈述
- 上下文召回率得分 = 上下文中可支持的关键陈述数量 / 预期结果中的关键陈述数量
这种算法易于理解且符合直觉,毕竟这正是召回率应有的计算方式。由于步骤 2 中的 LLM 评判员被约束为二元响应,评测结果对任何测试用例基本保持稳定。
但当我们开始研究涉及自定义标准的评测指标时,问题出现了。坦率地说,我也不认为我们的默认指标足以覆盖特定用例的评测需求。
当我提到“自定义标准”时,并非指简单的标准如: “判断 LLM 输出是否是一份不错的总结”
我指的是如下的标准,这相对直接一些: “检查输出是否为 Markdown 格式。若是,验证所有总结性的标题是否存在。若存在,确认其顺序正确。然后评测总结本身的质量。”
这种评测有本质区别。它不再只是判断质量,而是强制执行带条件逻辑的多步骤流程,每一步都引入新的复杂度。
内部我们将“这是否是一个好总结?”这类简单标准称为玩具标准。这些案例不需要真正的确定性评测,我们已经通过 GEval(一种通过思维链提示和填表范式评分自定义标准的 SOTA 指标)支持评测。当然,用户可以通过调整评测标准使指标更严格或宽松,但当用例明确(如生成总结)且没有数千个测试用例建立统计显著性时,你需要确定性评测。对多数用户而言,这是关键需求,仅依赖松散的主观评测是不够的,评测必须产生一致可靠的分数以反映真实效果。
这正是让代码库变得可怕的根源,数百行代码专门用于调整评测逻辑,只为让指标适配特定用例。
为所有人寻找可复用的解决方案
无论用户是否意识到,他们构建的本质上是由 LLM 驱动的决策树。评测流程的每一步都是一个节点,LLM 在此做出决策或提取关键属性,结果决定后续流程。如果响应通过一个检查,则进入下一步;若失败,评分逻辑相应调整。
这解释了为何他们的代码库如此冗长,大量 LLM 调用链、嵌套条件语句和基于规则的逻辑,全为强制执行结构化评测流程。显然,用户需要这种控制力,但手动编写和维护这些逻辑同样痛苦。
有趣的是,一些用户已在 DAG 中使用 GEval,不是用于完整评测,而是作为轻量级检查(在进入详细评测前判断是否通过)。有时目标不是分配分数,而是验证响应是否满足最低要求。这印证了我们的观察:用户需要灵活构建评测流程,一刀切的评分系统无法满足需求。
我们得出结论:需要让用户能在 DeepEval 中轻松构建 DAG,并确定需要四类节点:
- 任务节点:将测试用例处理为更适合评测的格式(LLM 输入、输出、预期结果等)
- 二元判断节点:根据父节点上下文做是否判断(如 QAG)
- 非二元判断节点:根据父节点上下文生成字符串列表判断
- 裁决节点:根据评测路径返回硬编码分数或 GEval 计算分数(所有叶节点均为裁决节点,裁决节点不能是根节点)
因此,我们发布了包含这四类节点的 DAG 指标,并将其(强行)命名为 Deep 无环图(DAG,Deep Acyclic Graph)指标。甚至有位 Reddit 用户评论道: “混淆对困惑者无益。这种命名(DAG)还可能让读者/用户觉得工具作者不懂什么是真正的 DAG。”
确定性、LLM 驱动的决策树
截至 2025 年 2 月 6 日,DeepEval 的 DAG 指标是我们构建过最强大的指标。它不仅是可定制的,而且完全可确定,围绕 LLM 驱动的决策树构建,为评测带来清晰度和控制力。
DeepEval 默认指标的优势在于将 LLM 测试用例(包含输入、实际输出、预期结果等参数)分解为原子单元,通过 QAG 将 LLM 评委的裁决约束为有限响应,这减少了幻觉风险,并通过上下文学习示例实现更精细的控制。我们将此原则直接应用于 DAG 指标,将评测结构化为四类核心节点:
- 任务节点:将 LLM 测试用例分解为原子单元
- 二元判断节点:判断是否,并根据原始测试用例或父节点输出决定下一节点
- 非二元判断节点:生成字符串列表,并根据原始测试用例或父节点输出决定下一节点
- 裁决节点:根据完整评测路径返回硬编码分数或 GEval 分数
目前最具影响力的用例是摘要生成,尤其是法律合同、医疗笔记、会议记录等结构化文档。这些摘要必须遵循特定格式(含必需章节且顺序正确),同时保证质量和完整性,每一步都成为 DAG 中的一个节点。
例如,假设你要评测会议记录摘要,要求包含按正确顺序排列的三个关键部分:引言、正文、结论。无需手动编写和管理每个评测提示词,你可以:
- 将任务节点设为 DAG 的根节点以提取标题
- 用二元判断节点判断标题是否正确
- 若正确,用非二元判断节点判断顺序是否正确(或偏离程度)
根据评测路径,DAG 返回不同分数。这一切原本需要复杂的自定义评测流程
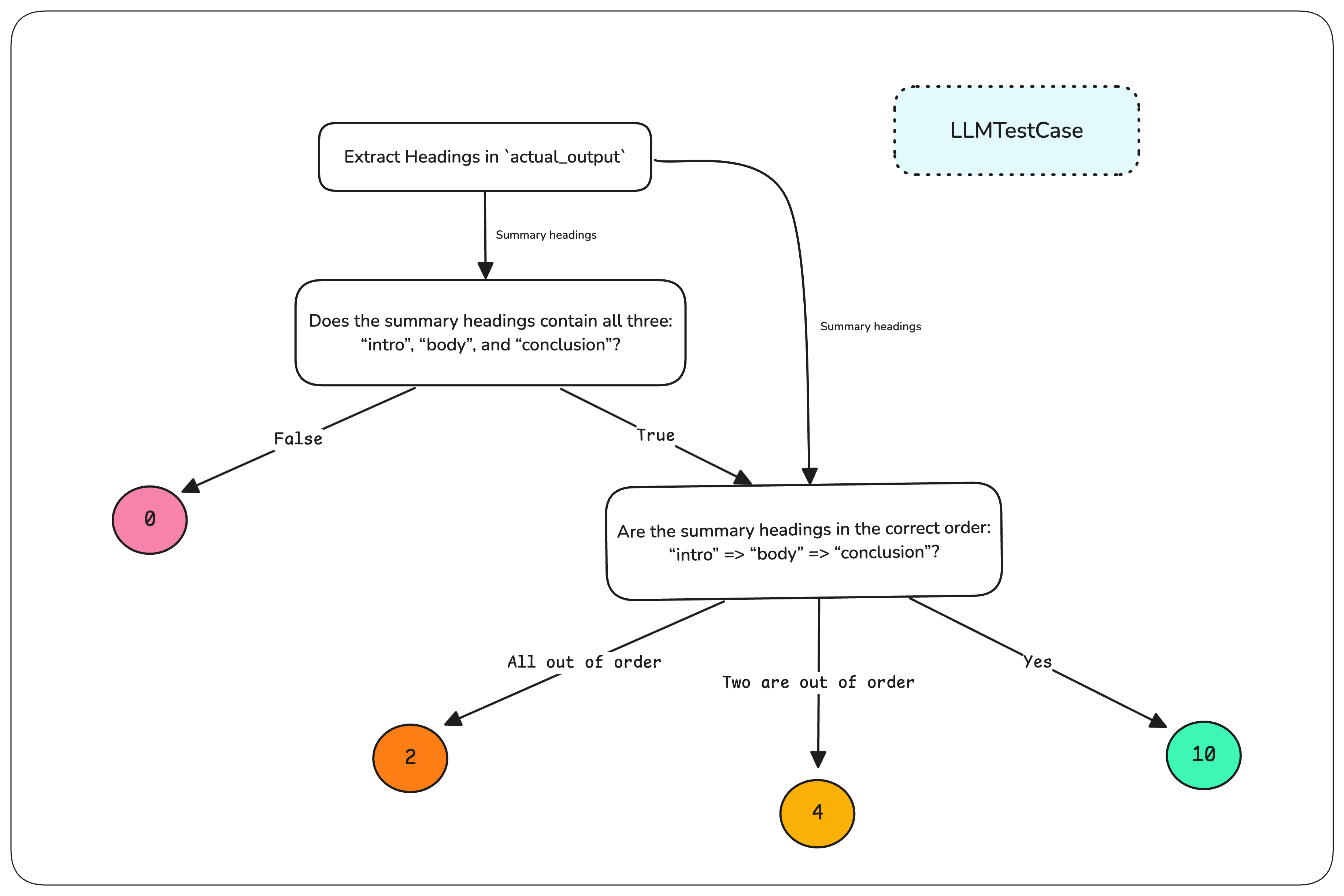
DAG决策树
现在通过 DeepEval 的 DAG 指标只需几行代码即可实现,无需手动编排流程,同时确保评测的结构化和确定性:
from deepeval.metrics.dag import (
DeepAcyclicGraph,
TaskNode,
BinaryJudgementNode,
NonBinaryJudgementNode,
VerdictNode,
)
correct_order_node = NonBinaryJudgementNode(
criteria="Are the summary headings in the correct order: 'intro' => 'body' => 'conclusion'?",
children=[
VerdictNode(verdict="Yes", score=10),
VerdictNode(verdict="Two are out of order", score=4),
VerdictNode(verdict="All out of order", score=2),
],
)
correct_headings_node = BinaryJudgementNode(
criteria="Does the summary headings contain all three: 'intro', 'body', and 'conclusion'?",
children=[
VerdictNode(verdict=False, score=0),
VerdictNode(verdict=False, child=correct_order_node)
],
)
extract_headings_node = TaskNode(
instructions="Extract all headings in `actual_output`",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
output_label="Summary headings",
children=[correct_headings_node, correct_order_node],
)
# create the DAG
dag = DeepAcyclicGraph(root_nodes=[extract_headings_node])
# create the metric
metric = DAGMetric(name="Summarization", dag=dag)
# run the metric!
metric.measure(test_case)
print(metric.score, metric.reason)
还有许多用例待探索,本节到此结束,剩余部分留待你的想象。
锦上添花
除了解决核心问题,DAG 指标还带来意外优势。
弱模型同样有效
许多用户更倾向使用自己的 LLM 进行评测,但若采用传统指标(如 GEval),性能较弱的模型难以提供可靠结果。如今无需再陷于:
- 定制模型微调的耗时
- 提示词海量示例的堆砌
由于 DAG 允许你将评测分解为细粒度步骤,即使小型或性能较差的模型也能轻松处理评测任务。
深度集成 DeepEval 生态
DAG 完全集成于 DeepEval,因此具备:
- 并行执行优化:同级任务节点并行运行
- 高效成本管理:无需手动跟踪 API 使用或优化调用
- 内置缓存:尽可能复用已计算的指标结果
- 错误处理:自动上报 DAG 中的错误以供调试,也可忽略错误以避免中断评测
前所未有的调试能力
通过 DeepEval 的 verbose_mode,DAG 指标能够:
- 全程跟踪决策链路 —— 轻松回溯每一步判断
- 透传中间裁决 —— 快速定位失败根源
- 分步输出优化建议 —— 精准锁定改进节点
DAG 指标不止于优化评测——它让整个流程更透明、更高效、更灵活,无论底层大模型如何迭代皆可无缝适配。
最后思考
我们曾担心人们会因缺乏控制力而不喜欢 DeepEval。现有评测指标要么缺乏控制力(如 GEval 对弱模型表现不佳),要么需要大量提示工程和手动编排才能获得可靠结果。而现在,DAG 指标通过将评测分解为结构化、确定的步骤,解决了这一问题,即使小模型也能表现良好,同时支持细粒度定制。
DAG 指标完全集成于 DeepEval,运行速度远超任何自定义方案,自动化处理并行执行、成本跟踪、缓存和详细调试,消除了构建和维护自研评测框架的复杂性。
