

本篇文章介绍x86_64架构下如何阅读汇编语言,另有一篇关于ARM64架构的文章也已经更新,请查看原文阅读。
你可能会想这都21世纪第21个年头了,难道还有人需要学习汇编?抱歉,答案是需要的。首先,通过阅读汇编代码可以让准确地让我们了解程序到底在做什么。为什么你的C++程序是1MB(例如)而不是100KB?能否优化最常调用的函数以获取一些性能的提升?
特别是对于C++来说,那些没有被显式书写出来的指令操作,很容易让人忘记,或者我们压根都不会注意到这些隐含的操作,例如隐含于源码或程序设计语言语义中的指令操作。
其次,更实际的原因是:根据大家在Twitter上的最高投票,我们下一个要讨论的主题是参数传递,为了讲清楚参数传递这个问题,我们需要对汇编语言有一个基本的了解。这篇文章我们学习如何阅读而不是书写汇编代码。尽管这篇文章的某些代码或内容可以链接到Compiler Explorer,实际上在网站上发布文章并不要求一定懂得汇编语言。
指令
汇编语言最基本的组成单元是指令。每一个机器指令都是一个小操作,例如加和两个数、从内存载入一些数据、跳转到另一个位置继续执行(像C/C++中的goto语句)、调用函数以及从函数返回等。(x86架构下也有许多复杂的指令,其中有一些是该架构存在40多年来的历史遗留,另外有一些是新增的)
例1:向量的模
让我们通过第一个例子来熟悉一些简单的指令。这段代码计算一个二维向量模的平方。

下面这段代码是clang 11编译器基于x86_64架构生成的汇编代码(使用Compiler Exporer1这个在线工具生成)。

第一条指令 imulq %rdi, %rdi 执行有符号数的乘法操作。后缀q表示操作执行在64位长度的寄存器上(后缀l,w,b分别表示执行32位,16位,8位)。这条指令将两个寄存器(rdi;寄存器的名字都是以%开头)里面的数值相乘,结果保存在第二个寄存器中。这条指令对应C++代码中计算v.x的平方。
第二条指令同第一条做了相同的事情,只不过用到的寄存器是%rsi,计算的是v.y的平方。
下面我们有一条看起来挺奇怪的指令:leaq (%rsi, %rdi), %rax. lea代表着“load effective address”,由第一个操作数计算得出地址后,再将地址赋值到第二个操作数所代表的位置。(%rsi,%rdi)代表着指向%rsi+%rdi的内存地址,所以这条指令的意思就是将%rsi和%rdi中的数值相加并将结果赋值到%rax,lea是一个快速指令,而在许多RISC-y架构下的指令集中,例如ARM64,为了完成这个操作会用到许多add指令2。
最后,retq指令会从normSquared函数返回。
寄存器
下面简单介绍一下寄存器是什么。寄存器是汇编语言的“变量”,和你最喜欢的语言不同(如果你最喜欢的语言不是汇编),汇编语言中的“变量”是有限的,并且它们都有标准的名字,我们要讨论的寄存器最长会有64位。后面我们会看到有些寄存器是有一些特殊用途的。我可能记不住所有它们的名字,但是根据维基百科,在x86_64架构中全部3的16个寄存器是rax, rcx, rdx, rbx, rsp, rbp, rsi, rdi, r8, r9, r10, r11, r12, r13, r14, 以及 r15.
例2:栈
下面我们要丰富上面的例子,我们将会在normSquared中输出Vec2这个向量。

下面是生成的汇编代码:
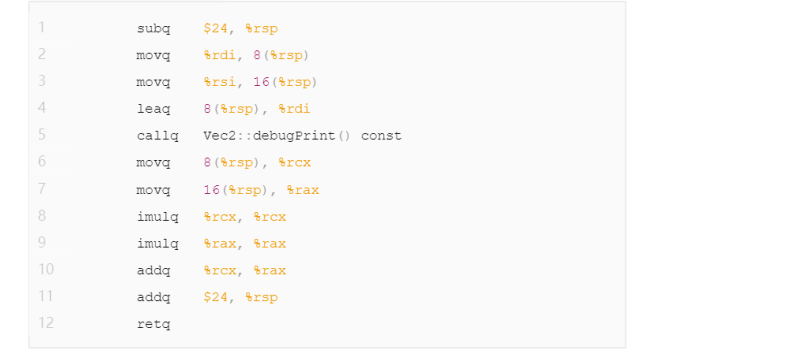
除了有一个函数Vec2::debugPrint() const的调用外,代码还用到一些新的指令和寄存器。%rsp是一个有特殊用途的寄存器,称之为栈指针,用来准备函数调用栈。栈指针%rsp保存着栈顶元素的地址,在x86架构中%rsp向下增长(向低地址方向增长),指令subq $24, %rsp在栈上为3个64位长度的整数创建空间(在函数开始的时候设置栈以及寄存器的指令称为函数序言(function prologue)),接下来的两个mov指令把传递给normSqueared的参数v.x, v.y保存到栈上(更多关于参数传递的内容请查看下一篇文章),这样就实现了在%rsp+8的位置完成对向量v的复制。接下来,我们用指令leaq 8(%rsp), %rdi 实现把复制的v的地址放到%rdi中,之后,调用Vec::debugPrint() const函数(译者注:%rdi为第1个参数,%rsi为第2个参数)。
例3:帧指针和控制流
下面让我们看一个稍微不同的例子。假设我们要大写输出字符串,并且我们要避免在堆里为过小的字符串分配空间5,我们可能书写出来像下面这样的代码:

生成的汇编代码如下6:

函数序言变长了许多,并且新增了许多控制指令。下面我们一条一条地看一下函数序言:
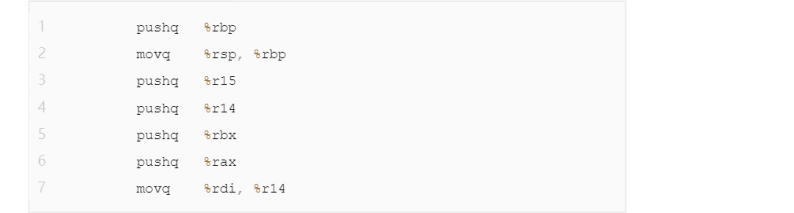
pushq %rbp; movq %rsp, %rbp这两条指令序列非常常见,这两条指令实现了把帧指针(译者注:帧指针指%rbp)的值放到栈顶然后将栈指针放到%rbp寄存器中(意味着栈指针就是新的帧指针)。在我们使用某些寄存器之前,需要保存它们的值到栈上,接下来的4个pushq指令便是保存这些寄存器的值7。
接下来,我们看到; 条件判断语句if。指令cmpq $1024, %rax 将根据%rax- $1024的计算结果设置标志寄存器,如果结果大于0,那么执行ja .LBB0_2指令,程序跳转到.LBB0_2位置继续执行。通常来说,高级的流程控制命令例如if/else语句以及循环语句都是通过条件跳转指令实现的。
我们先来看一下当%rax <= 1024的情况,程序继续向下执行而不会跳转到标号.LBB0_2的位置。下面是在栈上创建char temp[aSize +1]的指令序列:

因为后面使用%rsp的值,所以我们先把%rsp保存到%r15和%rbx8,然后加15到%rdi中(rdi中保存着数组的长度),再通过执行andq $-16, %rdi进行16位对齐,之后%rbx减去16位对齐后的%rdi,最后将%rbx赋值给%rsp。简而言之,这段代码在栈上为字符串分配了一个n*16字节大小的空间,其中n是 (strlen(aSize)+1)/16.0 向上取整。
下面这段代码只是简单调用了copyUppercase和puts函数:

最后我们有一段函数尾声:
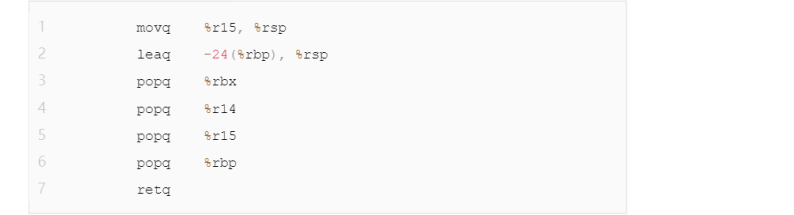
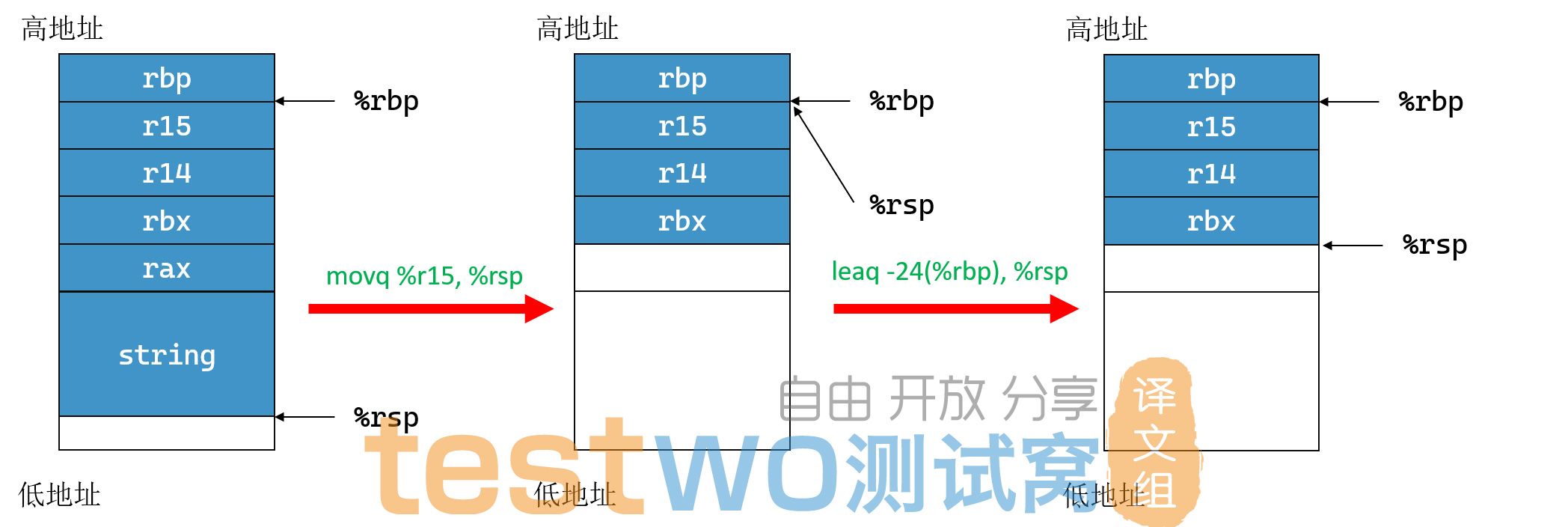
这段代码中,为了释放变长数组,我们先用leaq治理恢复栈指针。后面四条popq指令将我们在函数序言部分保存的寄存器弹出栈,最后通过retq返回函数调用。
下面再来分析一下当%rax > 1024时候,此时我们将跳转到标号.LBB0_2位置处继续执行。逻辑相对直接一些,我们看到这里先调用了operator new[], 然后将返回的结果从%rax保存到%rbx,之后像我们之前那一段代码一样,调用copyUppercase和puts函数。但是在这种情况下,我们的函数结尾看起来有点不同:

第一个mov指令将我们在堆上分配的数组指针赋值到%rdi。之后和上面的函数尾声一样,我们恢复栈指针并且将之前入栈保存的寄存器出栈。最后,我们有一个新的而指令:jmp operator delete[](void *). jmp指令像goto一样:无条件的将控制转向指定的标号位置或者函数。与callq不同的是,jmp不会把返回地址放到栈上。所以,当operator delete[] 执行结束后将直接返回到调用printUpperCase的位置。本质上来说,相当于是使用callq指令调用operator delete[] 但是函数执行结束后使用本函数的retq地址。这就是尾调用优化,编译器注入的# TAILCALL注释也能够帮助我们理解这一点。
实际应用:出人意料的转换
在最前面介绍里面说过,阅读汇编让隐含的复制和销毁操作变得显而易见。我们已经在前面的例子中看到这一点,但是最后我想使用一个常见的C++ 移动语义分析来结束这篇文章。直接通过传值调用来避免重载带左值引用参数的构造函数和带右值引用参数的构造函数可以吗?有一种观点可能会说:“可以的,因为对于使用左值的情况会发生复制,而对于使用右值的情况,只要参数类型能够花费较小的代价去移动(cheap to move)也是没有问题的”。下面我们来看一个使用右值的例子,我们可以看到花费较小的代价进行移动并不意味着没有代价(free to move)。如果我们想要优化程序性能,使用重载的方案可以帮助我们达到目的,而传值调用则不能。(当然,如果我们不想写额外的代码提高性能,传值调用可能也能满足你的性能需求)

如果我们看一下上面这段C++程序生成的汇编代码9(即使我已经显式地外联10构造函数但是生成的汇编代码还是太长没有办法放到正文中),我们可以看到createRvalue1做了一次移动操作(在MyString::MyString(std::string&&)这个方法体中)和一次std::string::~string()函数调用(函数结束前执行的operator delete指令)。createRvalue2这个方法生成的汇编代码很长:它总共做了两次移动操作(一次是MyOtherString::MyOtherString(std::string s)函数调用时发生在s参数上,一次是在构造器中)和两次std::string::~string调用(一次是前面说到的参数s上,一次是发生在成员MyOterhString::str上)。实际上,移动和销毁std::string都不会有太多性能损耗,但是对于CPU时间和代码体积来说绝不是没有代价。
延伸阅读
汇编语言的历史可以追溯到1940年代后期,因此有很多资源可供学习。就我个人而言,我第一个要介绍是我的母校密歇根大学的 EECS 370: Introduction to Computer Organization初级课程。不幸的是,该网站上链接的大多数课程资料都是不公开的。关于“计算机是如何运行的”这方面课程,可以参考伯克利(CS 61C)、卡内基·梅隆(15-213)、斯坦福(CS107)和麻省理工学院(6.004)的以下课程。(如果我错误的推荐了这些学校中的任何课程,请读者反馈我!)Nand to Tetris似乎也涵盖了类似的材料,并且可以免费获得项目和书籍章节 。
我第一次接触x86汇编是在有安全漏洞的背景下,或者像有些人所说的那样学会了成为“ l33t h4x0r”。如果这也能成为您学习汇编更有趣的理由,那就太好了!该空间中的经典作品是Smashing the Stack for Fun and Profit. 遗憾的是,现代计算机安全保护措施使您在自己环境中运行该文章中的示例变得非常困难,因此,我建议找到一个更现代的实践环境。Microcorruption 是一个由行业创建的示例,或者您可以尝试从大学安全课程中找到一个安全项目应用,以作为后续工作(例如,伯克利的CS 161项目1 ,该项目目前似乎已公开)。
最后,总是有Google和Hacker News。Pat Shaughnessy从2016年更新的“阅读x86汇编语言”从Ruby和Crystal的角度介绍了该主题,最近(2020年)也讨论了如何学习x86_64汇编。
祝您好运,happy hacking!
关于作者
Scott Wolchok
我是软件工程师。我致力于性能,可靠性和效率的研究。我还致力于JavaScript,Python和Rust的开发人员工具。文章里陈述是我自己的的观点,而不是我雇主的观点。
-----------------------------
1. 我使用AT&T语法,因为它是Linux工具中的默认语法。如果您喜欢Intel语法,请在Compiler Exporer的Output下进行切换。本文中的Compiler Explorer链接将同时显示AT&T和Intel语法。两者的差异简单来说,Intel语法更加明确内存引用,不使用b/w/l/q后缀,并把目标操作数放在第一个位置而不是最后一个位置。
2. 如果您查看此示例的ARM64汇编代码,则会看到一条madd指令:madd x0, x0, x0, x8。这条指令实现乘加运算:x0 = x0 * x0 + x8。
3. 大多数整数指令使用的64位寄存器。实际上 ,浮点数和指令集扩展里面使用了更多的寄存器。
4. 额外的8个字节的堆栈空间是因为System V x86_64 ABI的3.2.2节要求调用函数时,堆栈帧必须与16字节边界对齐。换句话说,每个编译器都犯了这个“错误”,因为这是必需的!
5. 还要假设我们没有像absl :: FixedArray这样的东西 。我不想让这个例子变得更加复杂。
6. 我在编译命令中加入-fno-exceptions以删除异常路径来简化该示例。它出现在尾声之后,我认为这可能会造成混淆。
7. 这可能是因为入栈指令比sub 8, %rsp指令要小和/或快。
8. 我认为这movq %rsp, %r15是没有必要的。直到movq %r15, %rsp指令%r15寄存器才再次被使用,但是该指令后面紧跟着leaq -24(%rbp), %rsp,该指令立即覆盖上一步更新的%rsp。我认为我们可以通过删除movq %rsp, %r15和movq %r15, %rsp这两条指令来改进代码。另一方面,英特尔的icc编译器似乎也是这么做的 ,因此要么有充分的理由这样做,要么就是清理变长数组的栈指针操作是一项相当困难的工作,或者仅仅是被忽略了的编译器中的问题。如果您知道是什么原因,请随时与我们联系!
9. 再次说明,我使用-fno-exceptions来避免复杂的异常清除路径。
10. 如果我们对MyString和MyOtherString的构造函数进行内联,则可以在createRvalue2中节省很多操作:我们会最多可以调用一次operator delete。但是,我们仍然执行2次移动操作,并且需要额外32字节的堆栈空间。
-----------------------------
{测试窝原创译文,译者:lukeaxu 如有问题欢迎评论区交流}
