

现如今有许多方法可以提高我们的编程技能,例如:
● 学习线上免费或付费的课程;
● 阅读编程书籍;
● 挑选个人项目,然后像自己书写代码的过程一样,边修改边学习;
● 学习网上的指导项目(tutorial project);
● 持续关注相关的编程博客;
不同的人可能会选择不同的方法去学习,但是不管是使用哪个方法,您都可以从中学到一些编程知识和技巧从而获得自身能力的提高。如果您是中级或高级的程序员,我敢肯定,上面这些方法您几乎都尝试过。
然而,其实还有另外一个非常好的方法但是大部分开发者可能会忽略,那就是通过阅读、分析和理解其他一些高质量的代码库来提高自己的编程技能。
我们很有幸生活在这个时代,因为我们可以相对容易地去获得一些高质量的开源项目。从Github或者Bitbucket将代码克隆到我们本地机器简直可以说是轻而易举。
而且,现代的版本控制系统(例如Git)也允许我们查看开发历史中任意一个时间点处的代码。这对我们来说简直是一大笔财富。
在这篇文章中,我们会以原始版本的Git代码库做示范,讨论如何阅读已有代码库来提高编程技能。
我们也会讨论为什么Git的代码值得阅读学习,以及如何获取Git代码,并且还会回顾一些相关的C语言编程概念。
我们还会介绍Git代码库的文件结构然后学习Git的核心函数是如何在代码里实现的。
最后我们会为希望进一步学习Git代码或者其他项目的读者提供下一步建议。
为什么要学习Git的代码
对于中级开发者来说,如果想提高自己的编程技能,Git代码库是一个非常好的学习资源。为什么Git代码值得深入研究,这里至少有7个原因:
1. Git或许是当今最流行的开发工具。简而言之,如果你是一个开发者,不可避免地您会用到Git。通过阅读Git的代码,你会对这个工具有更深入的了解;
2. Git本身非常有趣!在协作开发中,Git解决了许多有棘手的问题。作为一个时常有好奇心的人,我非常想要去一探究竟;
3. Git的代码是用C语言写的,对于之前没有过多接触过这门重要开发语言的开发者来说,阅读Git的代码是一次拓展C语言知识的重要机会;
4. Git中用到了许多重要的编程概念,例如内容可寻址数据库,文件压缩/解压缩,哈希函数,缓存以及简单数据模型。Git的代码中展示了如何将这些概念应用到真实的项目中;
5. Git的代码和设计是相当优美的。这是一个功能强大,但代码简洁的一个很好的示例,这份代码以清晰有效的方式实现了其目标;
6. Git的初始提交很小:它仅由10个文件组成,包含少于1,000行代码。与大多数其他项目相比,这是非常小的,并且很容易在一个相对可以接受的时间内理解它;
7. Git初始提交中的代码可以成功编译和执行。这意味着您可以使用并测试Git代码的原始版本,以了解其工作原理;
现在,让我们看一下如何获取Git代码的原始版本。
检出Git的初始提交
Git代码库的副本托管在GitHub上。我创建了Git代码库的分支,并在源代码中添加了许多注释,希望帮助开发人员轻松地逐行阅读它。
由于我是基于第一次Git的代码提交进行注释,因此我将此项目命名为Baby Git. Baby Git代码库位于BitBucket上。
建议您通过在终端中运行以下命令将Baby Git代码库克隆到本地计算机:

如果您想使用Git的原始代码库(没有我添加的注释),可以使用以下命令克隆代码库:

通过运行cd git命令进入新创建的git目录,您可以随意浏览这里的文件和文件夹。
很快您就会注意到,在当前版本的Git代码中(当前在工作目录中检出的版本),有很多文件包含很多很长且看起来很复杂的代码。
显然,当前的Git版本太大,单个开发人员甚至无法在一个可以接受的时间内熟悉它。
现在,为了让事情变得容易处理,让我们检出Git的初始提交。

这条命令将从Git的初始提交开始,以时间顺序的方式显示Git的提交记录。注意,列表中的第一个提交ID为e83c5163316f89bfbde7d9ab23ca2e25604af290.
通过运行下面命令将此提交的内容检出到工作目录中:

这条命令使Git处于分离头指针状态,并将Git的原始代码文件放置到工作目录中。
现在执行ls命令列出这些文件,您可以看到实际上只有10个文件中包含代码(第11个只是自述文件README)。对于中级开发人员来说,应该能够相对容易地理解这些文件中的代码!
注意:如果您使用的是Baby Git存储库,则需要运行命令git checkout master将HEAD指针重新指向master分支的最近提交,这样您又能够查看到所有注释,这些注释逐行描述Git的代码如何运作!
Git代码中重要的C编程概念
在深入研究Git的代码之前,先回顾一下出现在代码库中的一些C编程概念将有助于我们理解Git代码。
头文件
C语言中头文件是一个以.h为扩展名结尾的文件。头文件用于存储变量,函数和其他C对象。开发人员可以在.c文件中使用#include "headerFile.h"指令导入头文件。
这和Python或Java中导入文件的过程是类似的。
函数原型(函数签名)
函数原型或函数签名告诉C编译器有关函数定义的信息(包括函数名称、参数数量、参数类型和返回类型),而暂时无需提供函数体。它们帮助C编译器实现在出现函数体前识别对函数的调用。
下面是一个函数原型的示例:

宏
C中的宏本质上是一个预定义变量( rudimentary variable),宏会在C代码编译之前进行处理。宏是使用#define伪指令创建的,例如:

这里将创建一个名为TESTMACRO发宏,它的值定义为asdf. 无论TESTMACRO这个占位符在哪里使用,都会被预处理器(代码编译之前)替换为asdf.
通常在下面几种情况中会使用宏:
● 检查某个宏是否定义来作为true或false的开关;
● 保存一个可能在多个代码位置会被替换的整数或字符串;
● 保存一个简单的(通常是单行)代码片段,以便在代码多个位置被替换;
宏是方便的工具,因为它使开发人员可以只更新一行代码,而影响多个位置的代码行为。
结构体
C语言中的结构体是与单个对象相关联的一组属性的集合。
您可能熟悉Java和Python等语言中的类。struct是类的前身,您可以将其视为没有方法的原始类。
该结构体通过将ID字段以及该人的姓和名组合在一起来表示一个人。变量可以从结构体实例化,如下所示:

可以使用.检索结构体的属性,例如:

指针
指针是变量的内存地址,它是存储该变量值的内存地址。
可以使用&符号获取指向现有变量的指针,并将其存储在用*符号声明的指针变量中,例如:

此代码段定义了变量age,并将其赋值为21。然后,定义了一个指向整数的指针变量age_pointer,并使用&来获取age变量的内存地址。
指针也可以使用*来取消引用(即获取存储在内存地址中的值),例如:

继续前面的示例,我们使用*age_pointer来获取存储在指针中的值(21),然后将其加10赋值给new_age变量,因此new_age的值为31。
现在,我们对C编程概念的一些简短讨论已经完成,让我们回到Git的代码。
Git代码库结构概述
Git的初始提交只包含了十个代码文件。首先我们会从讨论Makefile和cache.h开始,因为这两个文件稍稍有点特别。
Makefile是一个构建文件,其中包含了将其他源代码构建为可执行文件的命令。
当您从命令行运行make all命令时,Makefile将编译源代码并产生与Git命令相关的可执行文件。我写了一篇关于深入理解Git的makefile的文章,如果您有兴趣,可点击链接阅读。
注意:如果您确实想在本地编译Git的代码(我建议您这样做),则需要使用上述代码的Baby Git版本。在Baby Git中我对makefile做了一些调整,以允许Git的原始代码在现代操作系统上编译。
接下来是cache.h文件,这是Baby Git代码库中唯一的头文件。如上所述,头文件定义了会在.c源代码文件中使用的许多函数签名、结构体、宏以及其他设置。如果您有兴趣,有我另一篇关于深入理解Git头文件的文章可供您阅读参考。
其余8个.c代码文件分别为:
● init-db.c
● update-cache.c
● read-cache.c
● write-tree.c
● commit-tree.c
● read-tree.c
● cat-file.c
● show-diff.c
每个文件(除了read-cache.c外)均以Git命令名命名,并且每个文件包含了该命令的具体实现代码,其中有些您可能会很熟悉。例如,init-db.c文件包含用于初始化新Git仓库的命令init-db的代码。您可能已经猜到了,这就是git init命令的前身。
实际上,每个.c文件(除read-cache.c外)各包含原始的8个Git命令之一的代码。构建过程将编译每个文件,并为每个文件创建一个可执行文件(可执行文件具有对应的名称)。一旦将这些可执行文件添加到系统路径中,即可像任何现代Git命令一样执行它们。
使用make all命令编译代码后,将产生以下可执行文件:
● init-db:初始化一个新的Git仓库,等同于git init;
● update-cache:将文件添加到暂存区,等同于git add;
● write-tree:根据当前索引内容在Git仓库中创建树对象(tree object);
● commit-tree:在Git仓库中创建一个新的提交对象,等同于git commit;
● read-tree:从Git仓库中打印出树的内容;
● cat-file:从Git仓库中检索对象的内容,并将其存储在当前目录中的临时文件中,等同于git show;
● show-diff:显示索引中暂存的文件与当前文件系统中的文件之间的差异,等同于git diff;
这些命令按序独立执行,执行过程类似于Git命令作为标准开发流程中的一部分。
我们尚未讨论的一个文件是read-cache.c。该文件包含一组函数,其他.c源代码文件可使用这些函数来从Git仓库中检索信息。
现在我们已经接触了Git初始提交中的每个重要文件,下面让我们讨论一些让Git发挥作用的一些核心编程概念。
Git核心编程概念的实现
在本节中,我们将讨论有关实现Git神奇能力的编程概念,以及Git的原始代码中是如何实现它们的:
● 文件压缩
● 散列函数
● 对象
● 当前目录缓存(暂存区)
● 内容可寻址数据库(对象数据库)
文件压缩
文件压缩,用于提高Git中的文件存储的性能。使用文件压缩会减小Git存储在磁盘上的文件的大小,而且当Git需要通过网络传输这些文件时,也会提高数据检索的速度。
Git的本地和网络操作需要尽可能快,这一点尤其重要。作为数据检索过程的一部分,Git需要对文件进行解压缩以获取其内容。
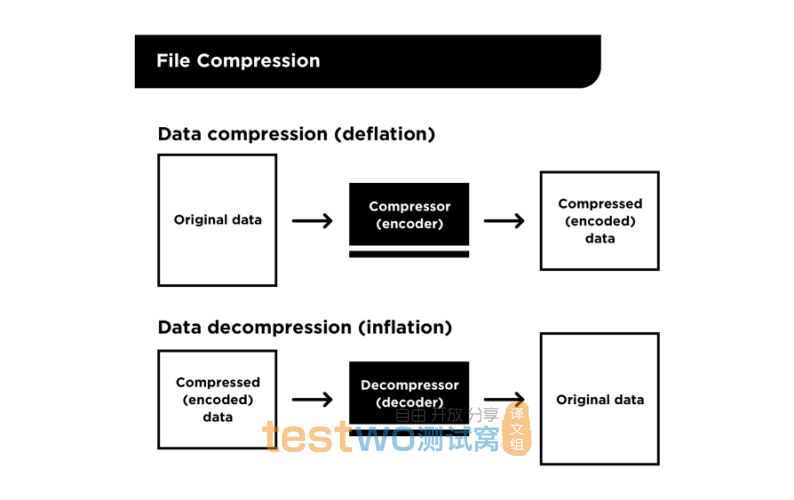
Git的原始代码中使用流行的代码库zlib.h去实现文件的压缩和解压缩。该代码库中包含了用于压缩和解压缩的函数、结构体和其他一些属性设置。具体来说,Zlib定义了一个名为z_stream的结构体,该结构体用于引用要压缩或解压缩的内容。
下面zlib的函数用于初始化z_stream以对其内容压缩或解压缩:

下面zlib函数用于执行实际的压缩和解压缩操作:

实际的压缩/解压缩过程要复杂得多,并且涉及设置z_stream的若干参数,我们在这里不做更多详细介绍。
接下来,我们将讨论哈希函数的概念以及在Git的原始代码是如何实现它们的。
散列函数
哈希函数是一种可以将输入转换为唯一输出的函数,但是反转这个操作非常困难或者说是不可能的。换句话说,它是单向函数。当今的技术做不到根据哈希函数的输出来推断用于生成该输出的输入。
Git使用哈希函数(特别是SHA-1哈希函数),为需要跟踪的文件生成唯一标识符。
作为开发人员,我们使用文本编辑器对代码库中的代码文件进行修改,并在告诉Git跟踪这些修改。此时,Git会使用这些文件修改作为哈希函数的输入。
哈希函数的输出称为hash值。hash值是长度为40个字符的十六进制值,例如47a013e660d408619d894b20806b1d5086aab03b.
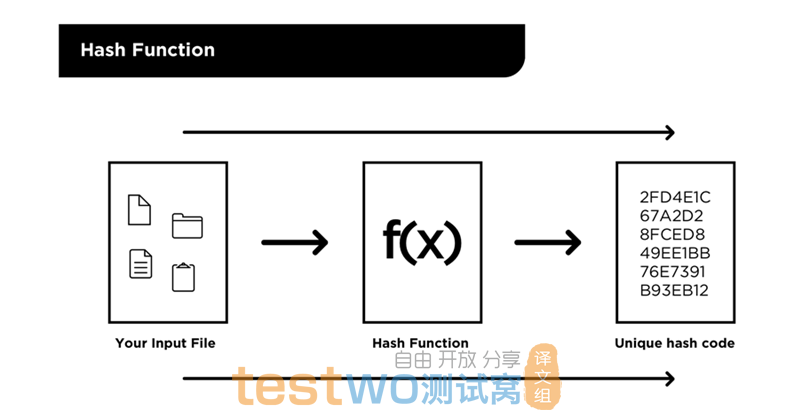
Git将这些hash值用于各种目的,我们将在以下各节中再次看到它们。
对象
Git使用简单数据模型(结构化的相关对象集合)来实现其功能。这些对象是一个一个的信息块,而就是这些信息块使Git能够跟踪对代码库文件的修改。Git使用的三种对象类型是:
● Blob
● Tree
● Commit
下面让我们将逐个进行讨论。
Blob
Blob是Binary Large Object的缩写。当使用update-cache 命令(git add命令的前身)告诉Git跟踪某个文件时,Git会使用该文件的压缩内容创建一个新的blob.
Git使用我们上面描述的zlib中的功能对文件内容进行压缩,并将此压缩后的内容用作SHA-1哈希函数的输入。这会创建一个40个字符的hash值,Git会使用该hash值来识别blob.
最后,Git将blob作为二进制文件保存在称为对象数据库的特殊文件夹中(稍后将对此进行详细介绍)。Blob的文件名称是生成的hash值,并且blob文件的内容是压缩后文件内容。
Tree
树对象用于将多个一同添加的blob链接在一起。因为blob除了提供哈希和压缩的二进制文件内容外,不提供其他任何信息,因此树对象还用于将blob与文件名(以及其他文件元数据,如权限)相关联。
例如,如果使用update-cache命令添加了两个被修改的文件,则将创建一个树对象,其中包含这些文件的哈希值以及每个blob所对应的文件名。
Git接下来要做的事情非常有趣。请注意,Git使用树本身的内容作为SHA-1哈希函数的输入,SHA-1哈希函数之后会生成40个字符的hash值。该hash值用于标识树对象,Git将其与blob放在一起保存,就是我们将在稍后讨论的对象数据库。
Commit
相比blob和树,您可能会对提交对象(commit object)更熟悉。提交表示由Git保存的一组文件修改,以及有关修改的描述信息,例如提交信息,作者和时间戳。
在Git的原始代码中,提交对象是执行commit-tree命令后生成的结果。生成的提交对象包括指定的树对象(该树对象代表一个或多个由blob表示的文件修改的集合),以及上一段中提到的描述信息。
像Blob和树一样,Git通过使用SHA-1哈希函数对提交的内容进行哈希处理并将其保存在对象数据库中从而标记一次提交。重要的是,每个提交对象还包含其父提交的hash值。这样,提交就形成了一条链,Git可以使用它来表示项目的历史记录。
当前目录缓存(暂存区)
您可能知道Git的暂存区,即使用git add命令后已修改文件所保存的位置,暂存区的文件等待使用git commit进行提交。但是暂存区到底是什么?
在Git的原始版本中,暂存区称为当前目录缓存(current directory cache)。当前目录缓存只是存储在仓库的.dircache/index路径中的一个二进制文件。
如上一节所述,在使用update-cache(git add)命令将被修改的文件添加到Git之后,Git生成与这些修改关联的Blob和树对象,然后把与暂存文件关联的树对象添加到index文件中。
之所以称其为缓存 ,是因为它只是在提交前临时保存修改的存储位置。当用户通过运行commit-tree命令进行提交时,就可以使用当前目录缓存中生成的树。当然一并提交的还包括其他信息,例如用于Git创建新提交对象的提交信息(commit message)。
之后,index文件就会被删除,这样就会腾出空间来保存新的修改。
内容可寻址数据库(对象数据库)
对象数据库是Git的主要存储位置。这就是我们上面讨论的所有对象(Blobs,trees,以及commits)的存储位置。在Git原始版本中,对象数据库只是指.dircache/objects/目录。
当Git通过update-cache,write-tree以及commit-tree命令创建对象时,这些对象被压缩,散列,并存储在对象数据库。
每个对象的名称是其内容的hash值,因此这也是为什么对象数据库也称为内容可寻址数据库的原因。Git使用根据内容本身生成的标识符来存储以及检索内容(blob,tree或commit)。
现代版本的Git的工作方式几乎与之相同。不同之处在于,现代版本的Git已经对存储格式进行了优化(尤其是针对网络数据传输这方面),使用了更有效的方法,但是基本原理是相同的。
总结
在本文中,我们借Git代码的原始版本,讨论如何阅读现有代码库以帮助提高编程技能。
我们介绍了Git为什么是一个值得学习的好项目,以及如何获取Git的代码,并回顾了一些相关的C编程概念。最后,我们提供了Git初始代码库结构的概述,并深入探讨了Git代码所依赖的一些概念。
下一步
如果您有兴趣了解有关Git代码的更多信息,我们还编写了指南,您可以在此处查看。本书详细介绍了Git的原始C代码,并直接说明了该代码的工作方式。
我鼓励所有开发人员探索开源社区,以尝试找到您感兴趣的高质量项目。您可以在几分钟内克隆这些代码库。
花一些时间来探究一下代码,您可能会有一些意想不到的收获。
{测试窝原创译文,译者:lukeaxu 如有问题欢迎评论区交流}
