

我想分享我在一个传染病流行病学团队担任“ DevOps 专家”的 18 个月中学到和完成的一些事情。在这份工作之前,我有四年的网站开发经历,日常工作对我来说已经变得非常常规。Web 开发是一个成熟的领域,大部分难题都已解决。为了寻找新的东西,我于 2020 年初在当地一所大学开始了一份新工作。我的同事在编写了大约 20k 行 Python 代码后,发现维持一个中等规模的代码库是一件痛苦的事情,所以产生了我现在的这个职位。可以想象:代码支离破碎,执行很慢,容易出错,并且很难做维护。我不认为这种情况一定是什么人的错:随着代码量的增加,这些问题自然而然地就会显现。
在这篇文章的其余部分,我将讨论我们开发的应用程序中那些比较好的实践:
明确工作流程
自动化测试
提升性能
自动化任务
可视化工具
数据管理
如果您是一名 Web 开发人员,通过本篇文章,您会了解到这些您熟悉的那些做法如何应用到不同的领域中。如果您是一名在工作中使用计算机的研究学者,您会了解到软件开发中的一些实践是如何帮助您提高效率的。
应用程序的现状
我们正在研究一种传染病模型来模拟结核病的传播。2020 年 3 月左右,该团队迅速转向对 COVID-19 进行建模研究。如果您想进一步了解可以看下我们的文档和示例。
简而言之,工作大概是这样的:为模型提供目标区域的一些数据(人口、人口统计、疾病属性),然后模拟未来会发生什么(感染、死亡等)。这种建模对于探索不同的场景很有用,例如“如果我们关闭所有学校会发生什么?” 或“我们应该如何推出我们的疫苗?”。这些结果通过 PowerBI 仪表板呈现给通常来自一些国家卫生部门的利益相关者,或者,结果以图表的形式包含在学术论文中。
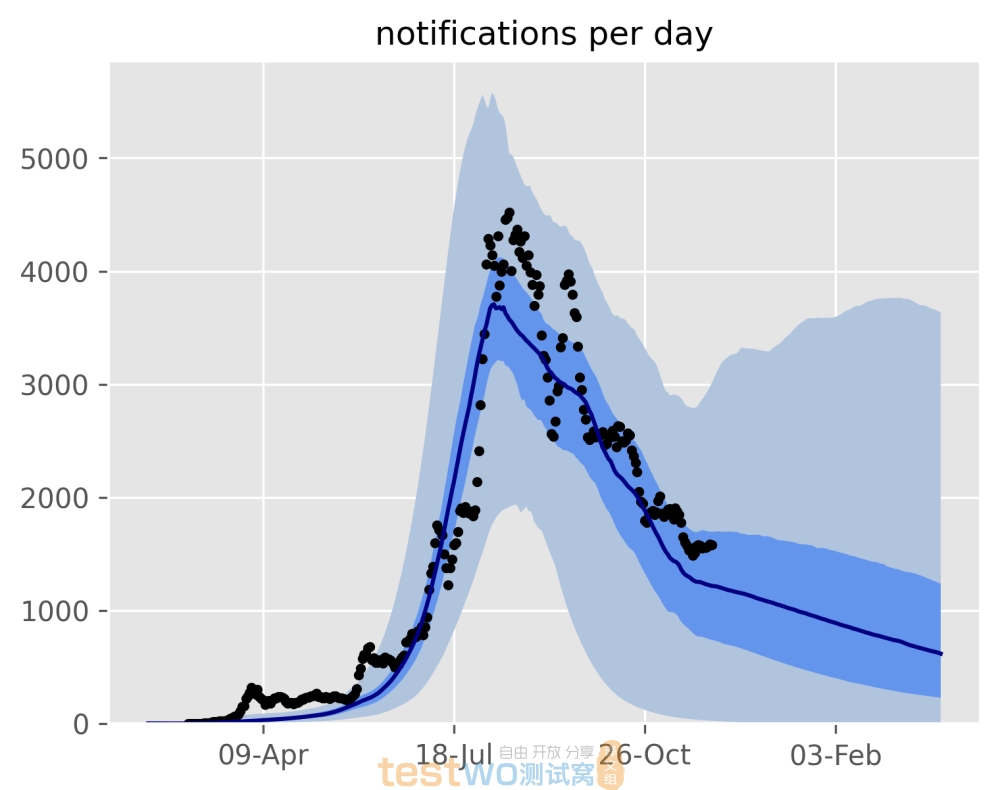
我们工作流程的很大一部分是模型校准。这里,我们建立一个具有可变输入参数的疾病模型,例如“接触率(contact rate)”(与疾病的传染性成正比),然后再给定一些历史数据(例如不同时间统计的病例数)。我们使用一种称为马尔可夫链蒙特卡罗 (MCMC) 的技术进行校准。MCMC 有许多很好的统计特性,但需要运行模型 1,000 到 10,000 次——计算成本是相当高的。

这听起来很酷!但当我着手工作时,问题也随之显现。鉴于其大小和复杂性,代码库并没有得到应有的重视。阅读和理解代码的过程着实让我痛苦万分。
此外,模型校准很慢。可能需要几天或几周的时间,这个过程需要有人将应用程序上传到计算机集群,照看运行并下载输出,然后再对结果进行后续处理,这需要大量的人工操作。如果是提交学术论文,然后审稿人要求“您做个小改动重新运行所有内容”时,这意味着需要花费几天或几周的时间。
所以,这里有痛点也肯定有很多改进的空间。
引入 DevOps 到工作流程
团队每个人都知道我们工作流程存在问题,并且每个人都想改进我们的工作方式。如果要我指出我们后来成功的关键因素,那就是团队中每个人都愿意改变以及他们对新事物所持的开放态度。
我将 DevOps 引入工作中,我所说的 DevOps 是什么意思呢?下面这段文字总结得很好:
DevOps 是用于自动化和集成 [不同团队] 流程的实践,因此可以更快、更可靠地构建、测试和发布软件。
传统上,这指的是软件开发人员和 IT 运营人员所做的工作,但我认为它可以应用得更广泛。现在,我们有一名软件开发人员、一名数学家、一名流行病学家和一名数据可视化专家在这份代码库上工作。
DevOps 的关键是考虑整个系统如何完成工作。DevOps 将工作流程视为一种优化的端到端管道,而不是仅仅关注个人的工作效率。DevOps 关注从始至终的所有过程,任务从哪里来?它需要经过哪些阶段才能完成?瓶颈在哪里?最重要的是:系统的目标是什么?
我们的目标是以发表的论文或报告为目的进行稳健的学术研究。关键指标是尽量减少“进行一项新研究所花费的时间”,团队最大的限制是时间,而不是材料、金钱、想法或其他东西。另一个关键指标是“不能出现错误的分析结果”:发表不正确的研究是不好的。
如果您想了解更多关于 DevOps 的信息,建议查看 The Phoenix Project 以及 The Goal .
明确工作流程
正如前面提到的,应该将团队的工作设想为一种管道。那么我们的管道是什么样的?在向同事做了充分的探讨后,我得出的流程像下面这样: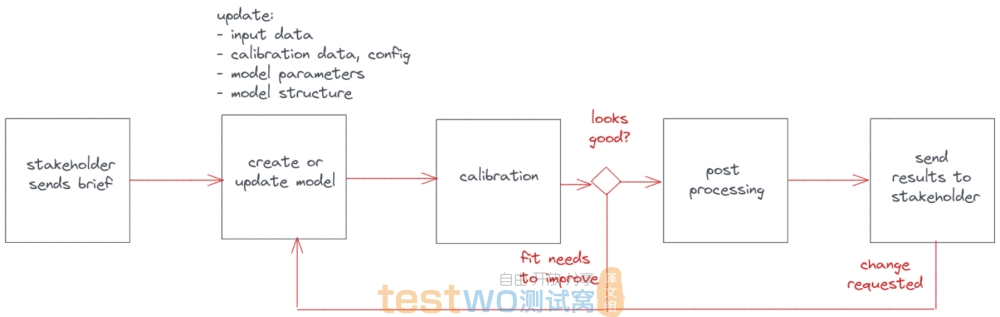
人们通常会在脑海中浮现关于他们如何工作的模型,但明确地写出来并不容易。将这个工作流程写在纸上为我们提供了明确的分析对象,并得出了明确的改进方面。例如:
- 更新模型需要繁琐的手动测试来检查模型是否向更好的方向演化
- 更新和校准的周期太长是瓶颈所在,因为校准运行缓慢,并且需要很多手动的步骤才能在计算集群上运行
- 再后续处理是手动完成的,通常只能由创建任务的人去完成
代码测试
我首先关心的是测试。代码刚开始没有任何自动化的测试。有一些小脚本和“测试功能”可以手动运行,但没有任何东西可以作为持续集成的一部分去运行。
这是一个不容忽视的问题。如果没有测试,错误将不可避免地被引入到代码中。随着代码库的复杂性增加,手动检查一切是否正常会越来越不可行,因为要检查的东西太多了。一般来说,书写正确的代码并不太难,但是保证后面绝对不会被破坏是困难的。
在这个建模的背景下,输出的正确性不容易被验证,自动化测试就变得比平时更加重要。相比于 Web 开发中所有的动作或输出均易于验证的确定性编程,该系统计算人类无法产生的输出。
冒烟测试
那么我要从哪里开始准备测试呢?从头开始为数千行代码添加测试?不不,这太可怕了。简单地坐下来为每一点功能编写单元测试需要数周时间,所以我写了“冒烟测试”。冒烟测试只运行一些代码并检查它是否崩溃。例如:
def test_covid_malaysia():
"""Ensure the Malaysia region model can run without crashing"""
# Load model configuration.
region = get_region("malaysia")
# Build the model with default parameters.
model = region.build_model()
# Run the model, don't check the outputs.
model.run_model()
这可能看起来非常蠢,但这些测试带来了惊人的回报。他们不会告诉你模型输出是否正确,但这些测试代码只需要几分钟就可以写出来。这些测试会捕获各种愚蠢的错误:比如有人试图将数字添加到字符串、未定义的变量、错误的文件路径等。它们在减少语义错误方面没有多大帮助,但有助于提高开发速度。
持续集成
人们往往意识不到添加测试是工作的分内之事。当你告诉某人“嘿,我们需要开始编写测试了!” 典型的反应是“嗯,是的,我猜,听起来不错……”,而他们内心在想“……但我还有更重要的事情要做”。您可以告诉他们不写测试是多么不负责任来恐吓他们,但这实际上还是不太可能让他们编写和运行测试。
那么如何让人们相信测试是有价值的呢?您可以通过✨持续集成✨的魔力向他们展示。我们的代码托管在 GitHub 中,因此我设置了 GitHub Actions 以在每次提交到 master 时自动运行新的冒烟测试。我在这里写了一个关于如何做到这一点的简短指南。
此设置使每个人都可以看到测试。每个提交旁边都有一个小勾号或叉号,重要的是,破坏代码的人的名字就在旁边。

有了这个系统,我们最终制定了关于保持测试通过的新规范。人们会说“哎呀!我的代码测试没通过!” ,之后在本地运行测试并修复就变成了工作的一部分。仅仅通过鼓励让人们花时间编写新测试有点困难。
我对代码库更加熟悉后,我为关键模块编写了集成测试和单元测试。我写了很多关于我在这里使用的一些测试方法的文章。
在这个过程中让我印象深刻的是,也许我在这份工作中所做的最有价值的事情却是最容易做的事情。在 GitHub 上建立持续集成流程花了我一到两个小时,但从那以后的至今的 2 年我们仍在享受它带来的好处。一件事情做起来有多难并不和它有多少价值成正比。
提升性能
代码执行太慢,因此提高性能的理由很充分。执行太慢可能是主观的,我写过一些关于后端 Web 开发中“慢”的不同含义的文章。在当前这种情况下,必须等待 2 天以上才能获得模型校准结果显然是太慢了,并且是我们最大的生产力瓶颈。
问题的核心是 MCMC 校准必须运行模型超过 1000 次。最开始时,一个模型运行大约需要 2 分钟。这样做 1000 次意味着每次校准大约需要 33 小时的运行时间。我们团队的数学家致力于让 MCMC 算法更高效地采样,而我则尝试如何从代码层面压缩每次执行的时间。
我使用了 Python 的 cProfile 模块,以及一些可视化工具来查找代码的关键点并优化它们。这篇文章是我的救命稻草,概括地说,提高性能的方面有:
- 避免在 for 循环中进行多余的重复计算
- 使用更高效的数据结构以实现更高效的值查找(例如,将列表转换为字典)
- 将 for 循环转换为矩阵运算(向量化)
- 使用 JIT 优化纯数值函数 ( Numba )
- 缓存函数返回值(memoization)
- 缓存从磁盘读取的数据
这项工作非常有趣。感觉就像我在玩电子游戏。修改,执行,分析性能,再修改,再执行,再分析性能。最初有很多简单的、显著的性能提升,但随着时间的推移,它变得越来越难提高。
几个月的时间之内,代码速度提高了 10 到 40 倍,在 10 秒或更短的时间内便能运行一遍模型,这意味着我们可以在几个小时内运行 1000 次迭代,而不是一天。我们的测试运行得更快,持续集成变得更加敏捷,人们更乐意在本地运行测试,因为它们现在需要 10 秒而不是 2 分钟才能完成。开发工作变得更快了,因为您可以调整代码、运行它并在几秒钟内查看输出。总的来说,这些性能改进为更好地工作开辟了机会,而如果代码维持原来的性能,可能并不会有那样的机会。
随着时间的推移,代码库的进一步壮大,代码的性能出现了一些下降。为了尝试解决这些减速问题,我在持续集成管道中添加了自动基准测试。
自动化任务
我们的校准过程可以在几小时而不是几天内运行,这之后,我们开始注意到工作流程中的新瓶颈。值得注意的是,运行校准涉及许多没有文档记录的手动步骤,这意味着只有创建模型的人知道如何去做校准。
与我们大学所建设的 Slurm 集群交互也是一种痛苦。计算资源是免费的,但我们受调度程序的支配,它决定了我们的代码何时被真正地运行,而用于运行和监控作业的 API 既神秘又笨重。
校准并不总是运行良好,因此这个循环可能会重复几次,然后才能得到我们想要使用的可接受的结果。
最后,没有系统的方法来记录给定模型运行的输入和输出数据。模型运行的结果将很难重现。
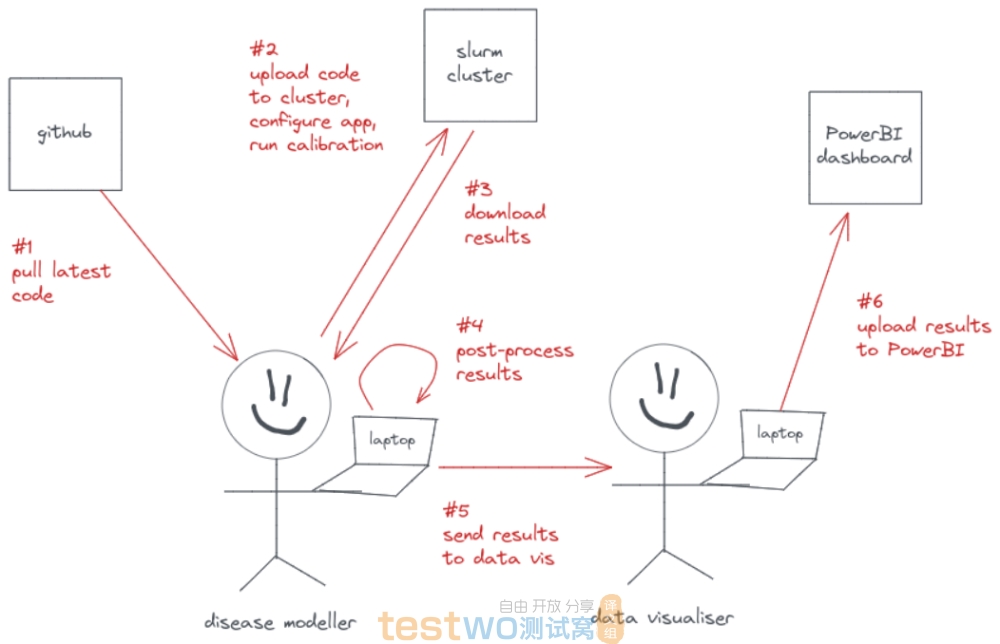
最开始的时候,工作流程是这样的:
经过我的折腾,将某些步骤中的大部分自动化,我们最终得到了一个看起来像这样的工作流程:
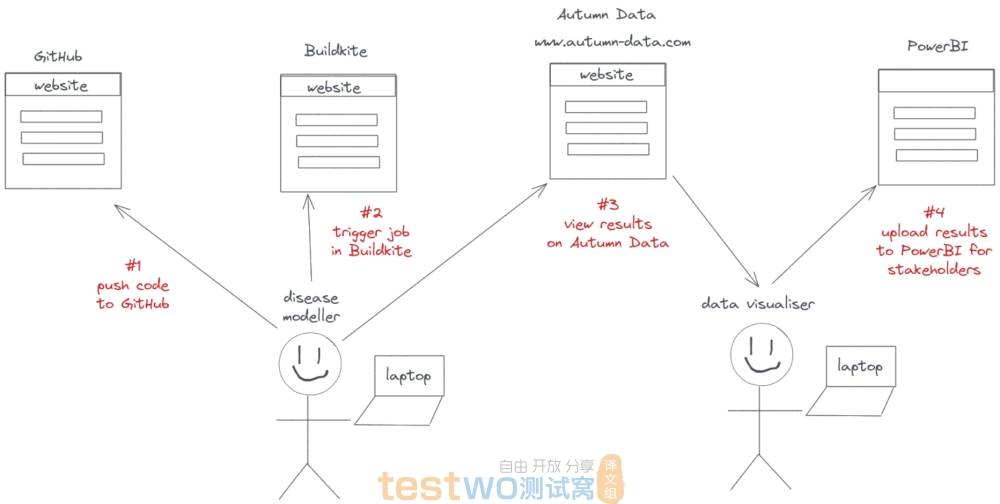
简单来说:
- 建立模型的人会更新代码并将其推送到 GitHub
- 然后,他们可以在网页通过填写表格来触发工作
- 校准和任何其他后续处理将在“云端”运行
- 最终,结果将显示在网站上
- 数据访问者可以下载结果并将它们发送到 PowerBI
新的工作流程有很多好处:没有太多的手动操作,该过程可以由团队中的任何人完成,可以轻松地并行运行多个校准。我们为每次校准自动生成标准诊断图(类似于机器学习的权重和偏差)。例如,这些图显示了模型参数在 MCMC 校准运行过程中的变化。
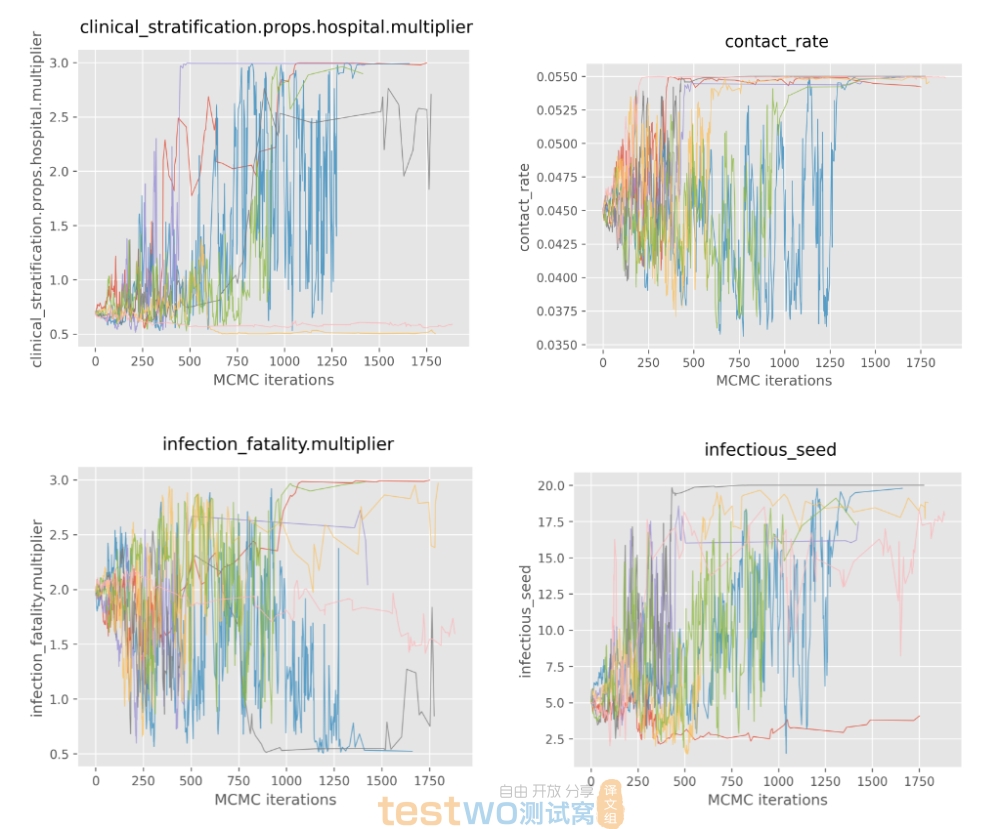
我不会详细介绍这个管道的具体实现。虽然这还不是我最好的工作,但它确实有效。它是一组 Python 脚本,将几个工具组合在一起:
- Buildkite 用于自动化执行任务
- AWS EC2 用于执行计算
- AWS S3 用于存储数据
- boto3 用于管理服务器
- NextJS 用于构建静态网站
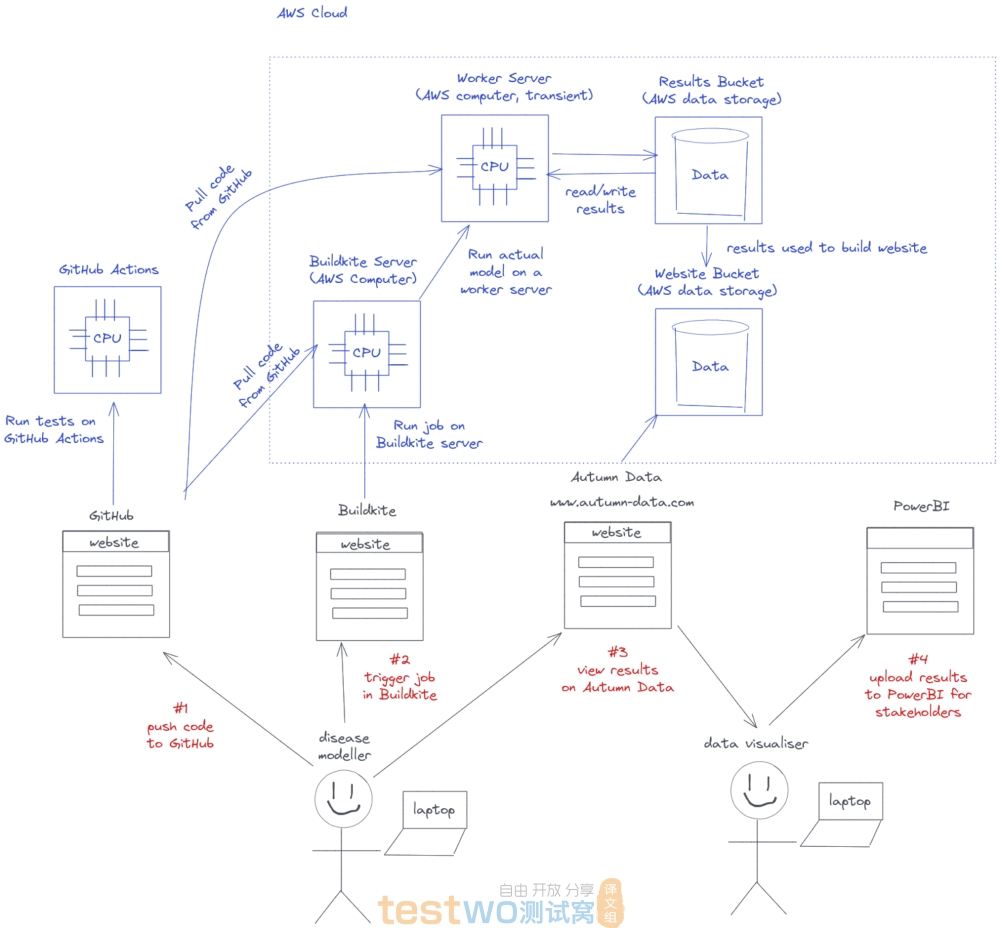
如果后面再重构,我还会考虑使用 Azure ML pipelines 之类的东西。如果您对云架构感兴趣,请看下面这张图。
可视化工具
我们的模型中有很多需要可视化的东西:输入、输出和校准参数。我们之前的方法是运行一个 Python 脚本,该脚本使用 matplotlib 将绘图转储到一个文件夹中。所以可视化的开发流程是:
- 编辑模型代码,运行模型
- 在输出结果上运行 Python 脚本
- 查看文件夹下生成的图表
看起来并没有太多不妥,但这里还是有很多不必要的手动操作。
Jupyter notebook 是这个方面的得力的工具,但我最终选择使用 Streamlit ,因为我们的许多绘图都是常规和标准化的。借助 Streamlit,您可以使用 Python 构建基于用户输入生成绘图的 Web 仪表板。这对于建模建立者来说很有用,他们可以在电脑上处理模型时快速检查一堆不同的诊断图。鉴于它全是 Python(没有 JavaScript),我的同事们能够独立添加他们自己想要的图表。仅在几个月的时间里,这个工具从一个有趣的想法彻底变成了我们工作流程不可或缺的一环。
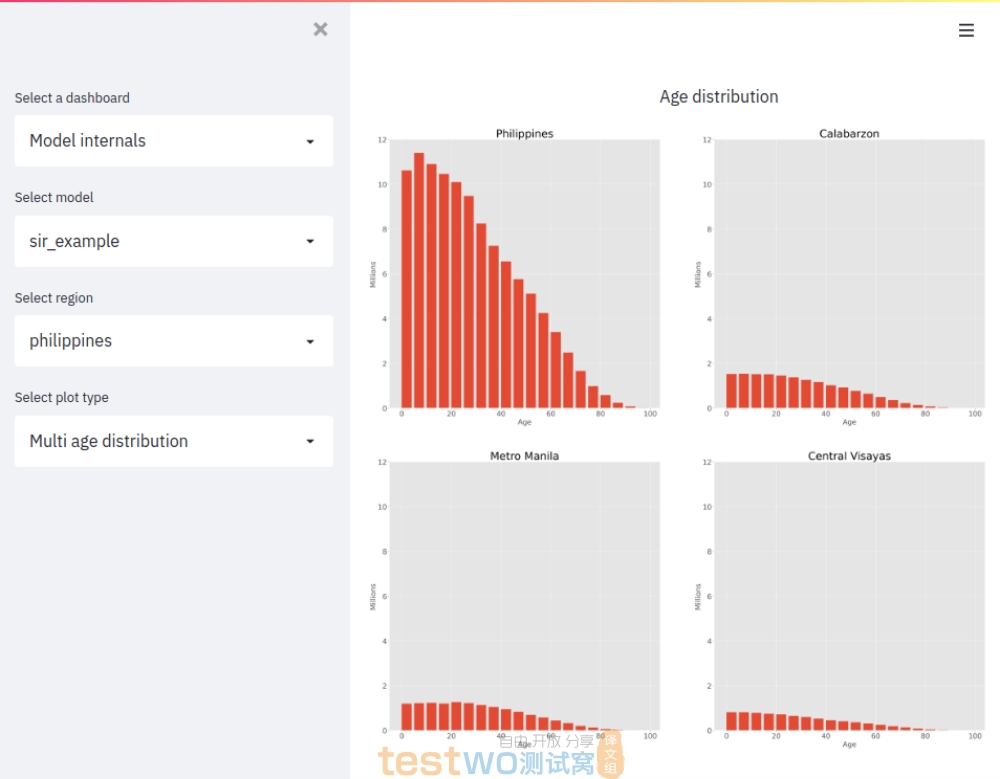
Streamlit 的一个关键特性是 “hot reloading” 。这意味着您可以通过编辑 Python 代码来调整绘图,点击“保存”后,更改将直接显示在您的网络浏览器中。这种快速反馈大大加快了绘图的进度。
注:下面这张图与本文并没有特别相关,我只想展示这个可视化效果。
数据管理
实际应用中我们有各种各样的数据。人口统计输入,如人口规模、模型参数、校准目标和模型输出。
我们有很多模型输入参数存储为 YAML 文件,但是很难程序保证按照预期的类型载入参数。当我离开团队时,差不多有一百个 YAML 文件。为了尽早发现错误,我使用 Cerberus 和 Pydantic 来验证从磁盘加载的参数。我编写了在持续集中运行的冒烟测试,以确保这些文件是正确的。我写了很多关于这种方法的文章,现在我更喜欢 Pydantic 而不是 Cerberus,因为前者更简洁。
我们的模型有很多第三方输入,例如来自谷歌的数据、联合国世界人口信息等。最初,这些数据作为未被记录的 .csv 和 .xls 文件的随机分散地保存在源代码。预处理是使用一些 Python 脚本手动完成的。后来,我推动团队将所有源数据正确记录并合并到一个文件夹中,并试图采用一个的标准框架,用一个统一的脚本预处理所有输入。随着输入数据增加到 100 MB 时,这时的存储库已经变得非常庞大且下载速度很慢了(>400MB),所以我将这些 CSV 文件移动到了 GitHub 的Git LFS.
顺便提一点,如果您想组织和标准化所有输入数据,建议查看 Data Version Control.
最后,我使用 AWS S3 保存任务产生的所有输出、中间值、日志文件和绘图。每个任务都使用一个键存储,其中包括模型名称、区域名称、时间戳和 git commit。这对调试非常有帮助,也方便团队中的每个人通过网站访问结果。缺点是我不得不偶尔每次从 AWS S3 手动删除约 100GB 的结果,以减少服务器的租用成本。
结束语
总的来说,我喜欢这份工作。学术环境有一些“缺点”,强调产出新的成果,特别是在 2020 年的 COVID 的背景下,因此有很多“一次性”的任务和分析。代码库在不断发展,感觉就像我一直在努力追赶或者被追赶。还有一点,不得不说,在不知道解决方案是什么的情况下,从事一件我以前从未做过的事情着实让人兴奋,就这次经历而言,我也从中学习到了许多关于机器学习和数据科学的知识。
最后,感谢阅读。
{测试窝原创译文,译者lukeaxu}
