大概在五六年前,有一次我在Google美国总部参加一次技术交流,有一个演讲让我印象深刻,让我至今一直记忆犹新的不是其演讲内容,而是演讲开始的第一页PPT:“别人眼中的Google VS Google人眼中的Google”。我们对Google的软件工程能力可以说是趋之若鹜的,但是Googler对自己的评价确是如此的中肯和朴实。

从『农业时代』向『工业时代』进化
虽然软件研发过程从一开始就是数字化的,但从某种程度上来说,软件生产过程仍然处于相当原始的状态。我们将软件研发模式归纳为三个发展阶段:
石器时代
一位或少数几位开发者即可完成软件研发工作,个人英雄主义盛行。
农业时代
随着软件规模与复杂度不断提升,开始出现群体协作,但协作仍然是以“手工作坊”的形式进行。这个时候的软件开发很像外科手术的协作模式,由一位技术和资历过硬的主刀医生带着一帮人一起进行,当然,这个这帮人的人数不会太多,手术的成功率与质量强依赖于主刀医生的能力。
工业时代
如今,软件体量动辄几十万行代码,用户规模达数亿,且与民生息息相关。开发者接收任务、各自造零件再进行组装的模式已经变得举步维艰。随着一个项目参与的人越来越多,分工越来越细,人和人之间需要的沟通量,也指数增长。很快你会发现,沟通花费的时间,渐渐地就比分工省下来的时间还要多。说白了,过了一个临界点,人越多不是越帮忙,而是人越多越添乱。一个人12个月能完成的事,不见得上12个人1个月就能完成,甚至12个月也未必能完成。此时就需要用工业化的思想来做软件。
研发效能的现状与挑战
业务发展一段时间后,增长趋势放缓,企业很自然地会期待通过研发效能提升开启第二增长曲线。
- 然而残酷的事实是,随着业务的发展,软件架构复杂度不断提高,软件与人员规模不断扩大,协作成本变高,加人加班式的粗放增长不再奏效。
- 概括而言,软件的复杂度提高了。研发效能不仅难以提升,反而会逐步恶化。
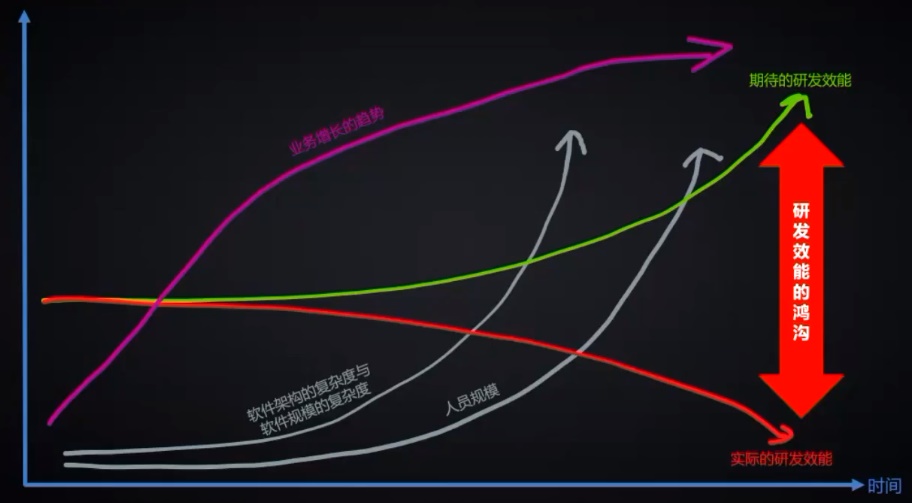
所谓『效能提升』实践,并不能扭转这一恶化趋势,而仅能减缓它。前面提到研发模式向工业时代进化,正是减缓效能恶化的重要实践之一。
软件研发的复杂性困局
复杂性的来源
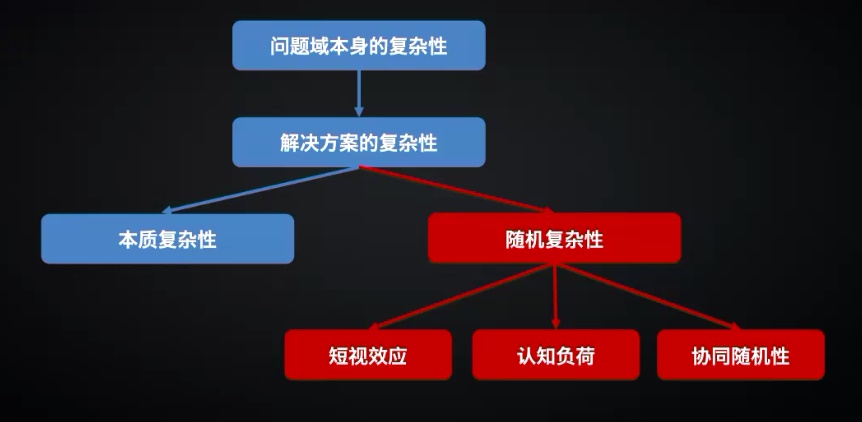
随着业务发展,软件产品所需要解决的问题领域愈发复杂,带动软件本身的复杂度也不断提高。这里复杂性来自两个方面:
本质复杂性:对应的是软件产品的能力提升,是理想情况下的复杂性下限。
随机复杂性:往往带来影响深远的危害,是复杂性中可管控、可优化的的部分。具体包括:
-
- 短视效应,急功近利、快糙猛地完成交付,留下隐患
-
- 认知负荷,知识未沉淀,学习理解成本高
-
- 协同随机性,更多点对点的、准确性难以保障的沟通与协同
以架构腐化为例
架构腐化是随机复杂度带来的负面影响之一。在开发过程中,技术债务被不断引入,到架构腐化被感知的时候,情况往往已经相当严重且不可逆。
针对这一问题,唯一有效的应对方法是防范于未然,预防架构腐化,减缓腐化速度。

技术债务可分为代码级和架构级两类:
代码级技术债务
由于随机复杂度,开发者不断引入代码级技术债务,尤其当团队规模庞大时,代码级技术债务的增长非常快。更糟的是,由于技术债不直接影响产品功能,往往非常隐蔽难以发现。
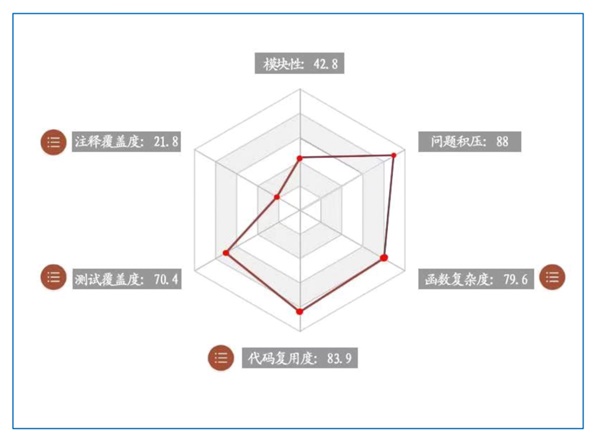
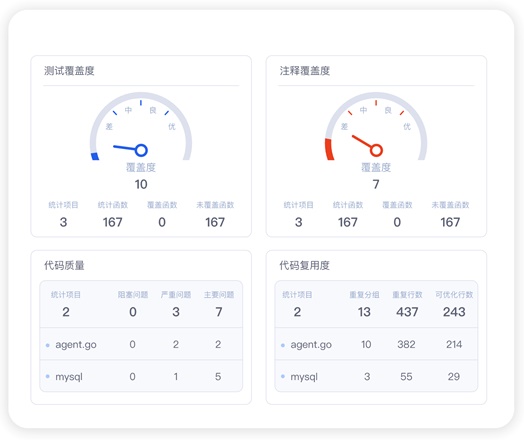
针对代码级技术债务,可以通过代码分析来持续跟踪,度量指标包括代码重复度、注释覆盖度、圈复杂度等指标,在开发者引入技术债的第一时间识别并解决。在思码逸产品中,这些指标组成了软件工程质量度量的多个维度。
架构级技术债务
架构级技术债务的危害比前者更甚,需要通过持续度量软件系统的可维护性,提前识别反模式。例如:
架构解耦度(decoupling level)度量的是软件系统在多大程度可以被拆分为独立、可替换模块。
不稳定接口(unstable interface)度量的是接口共同修改的关联度,识别影响范围过广的架构热点。
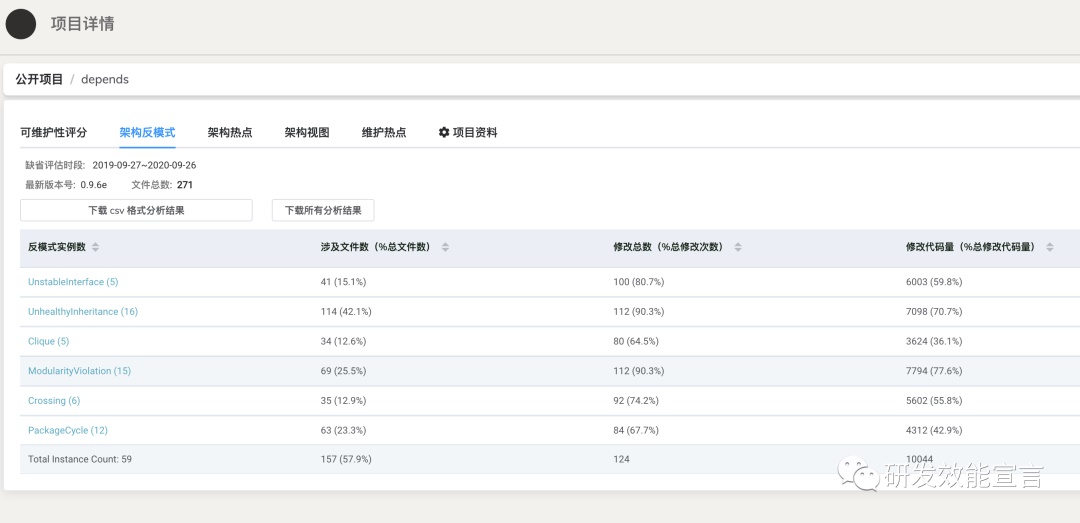
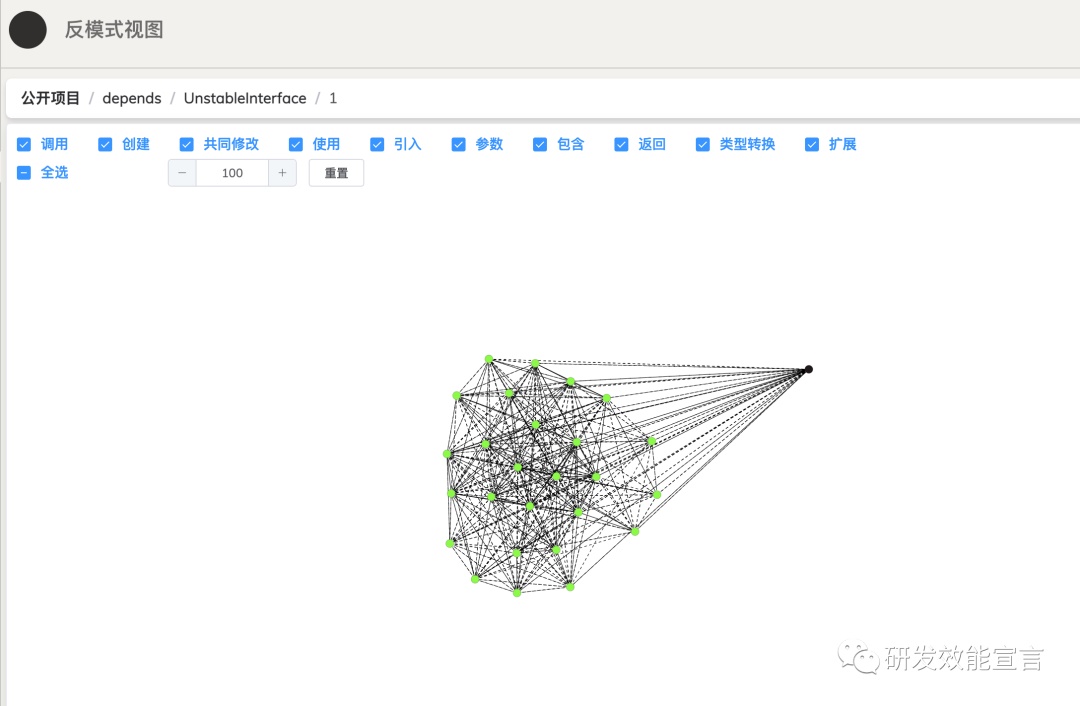
随机复杂性与效能的关系
值得注意的是,随机复杂性也并不全然是坏事。个体失误引入随机复杂性,虽然给系统带来未知风险,但同时也带来可以借鉴的经验和教训。经过有效复盘和学习,软件系统将变得更加健壮。
因此,我们将研发效能的本质归纳为:以可接受的成本,将随机复杂性降低至可控范围。
双流模型
那么软件研发行业如何通过优秀的实践和工具来降低随机复杂性呢?这里我们引入双流模型的概念。
什么是双流模型?
以两个视角去观察研发过程,我们可以拆分出两条流:
需求价值流
需求状态的流转过程,主要关注者是项目经理、产品经理等角色
研发工程流
软件研发流程中的具体操作和阶段性工作产品,主要关注者是开发工程师、测试工程师、运维工程师等角色。
简而言之,双流模型就是将需求价值流与研发工程流关联起来。
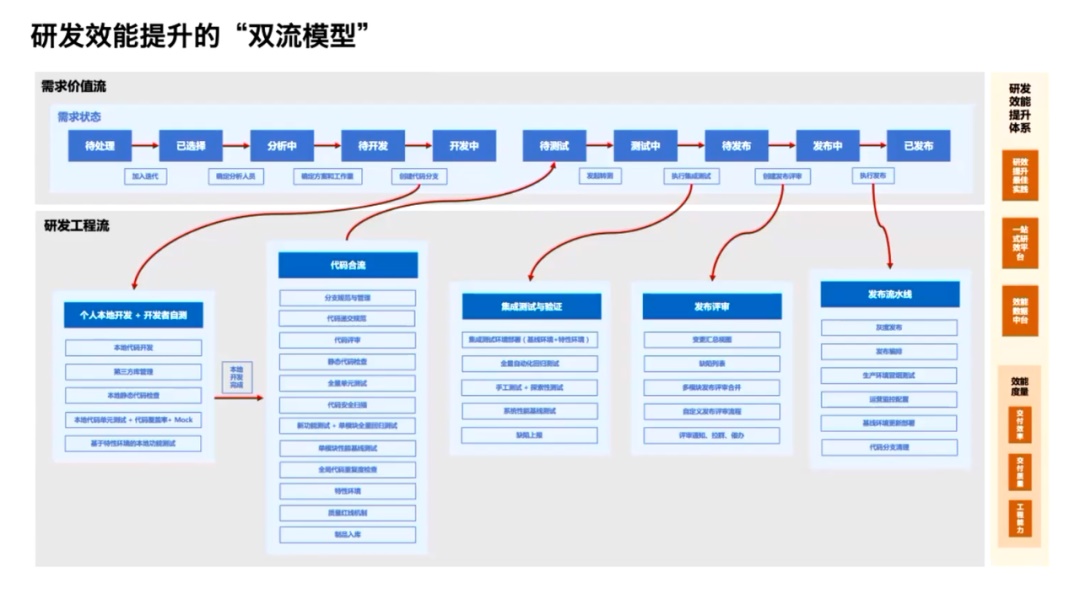
双流模型的价值
提升工程师体验 + 降低随机复杂性
以往,需求价值流和工程价值流没有关联关系。工程师完成任务后,需要离开工作系统,到项目管理工具上做手动流转。
这种繁琐、重复的事务性工作一方面挤占工程师的时间、体验不佳,另一方面给效能数据有效性打了问号。
一个常见的例子是需求燃尽图的折线并非平稳下降,而是迭代最后一天断崖式下跌,因为工程师们都赶在最后一天更新状态。基于这样的工程数据做度量必然不可靠,微观的、以天为单位的研发过程管理不再有效,问题和隐患可能因此被掩盖。
当需求价值流和研发工程流自动双向联动,事情就轻松了许多——举两个例子:
当工程师认领开发任务时,不需要离开 IDE 界面通过插件即可领取任务,平台自动完成- 需求状态流转、分支创建、代码拉取等工作;
工程师开发完成并完成本地测试后,提交代码合并请求,平台触发 CI 流水线,自动完成静态代码检查、质量门禁检查、质量测试等等,并更新需求状态。
工程师更加专注高效地开展工作 + 工具自动、准确、及时地处理事务性工作,随机复杂性随之降低。
不同阶段的效能提升实践不同阶段的效能提升实践
以下分享双流模型中需求阶段和个人本地开发和测试阶段的几个典型研效实践。
需求阶段
需求阶段的效能提升至关重要,因为它影响到研发团队是否将宝贵资源投入到了正确方向上。
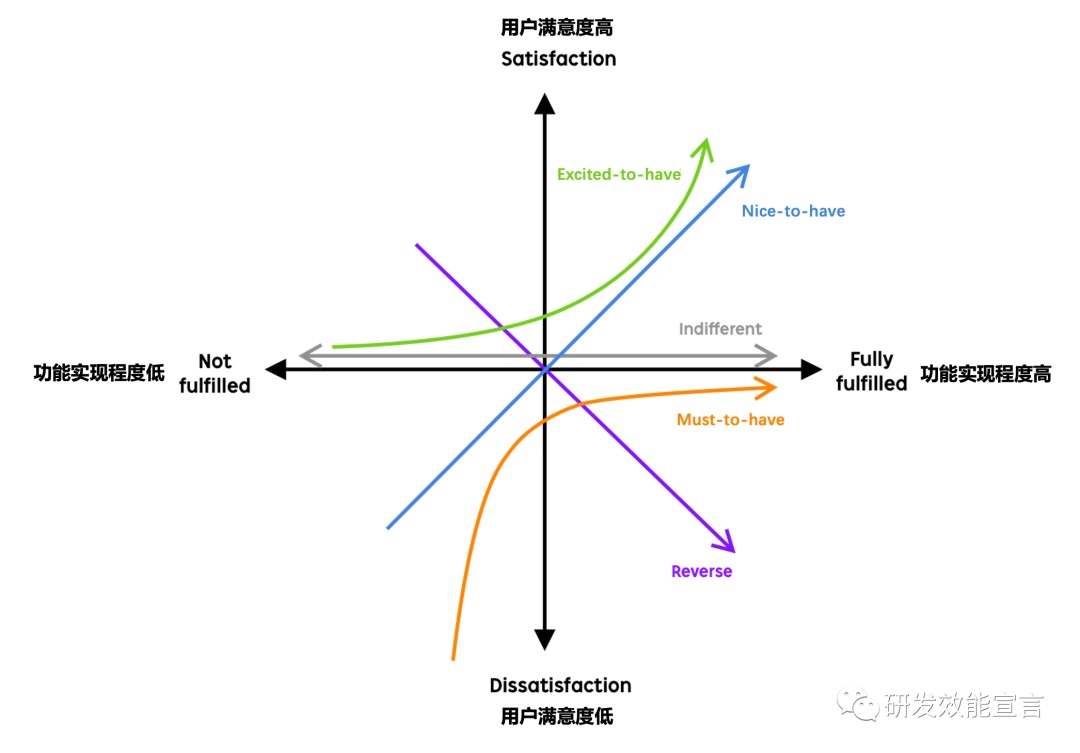
在需求阶段,我们可以使用 Kano Model,从功能实现程度和用户满意度两个维度对需求进行分析,为需求排期提供客观依据。简单列出几个类型:
Must-to-have:基本需求,质量如果不达标用户会立刻离开,例如手机的通话功能;这一类型的需求往往需要优先排期
Excited-to-have:实现这类功能的时候满意度增长很快,容易引发口碑传播;可从这一类型中选择成本较低或技术壁垒较高的需求
Reverse:尽管从模型来看,这一类型需求是最不理想的,但实际上往往是产品的盈利点,例如信息流广告;针对这类需求,需要结合业务阶段判断优先级
个人本地开发和测试阶段
- 高效获取开发环境
使用云端 IDE,工程师可以在任何一台带有浏览器的设备上进行编码,节约下载代码、编译代码、连接远端调试环境等工作;研发团队可以统一插件版本,保障一致体验,缩短新成员上手周期。
- IDE 精准代码提示
基于机器学习,IDE 插件能够主动学习代码上下文,给出更加精准、符合逻辑的代码提示,不仅提高效率,也降低工程师失误的随机复杂度。让工程师更容易进入“人码合一“的心流状态。典型的工具是AiXCode。

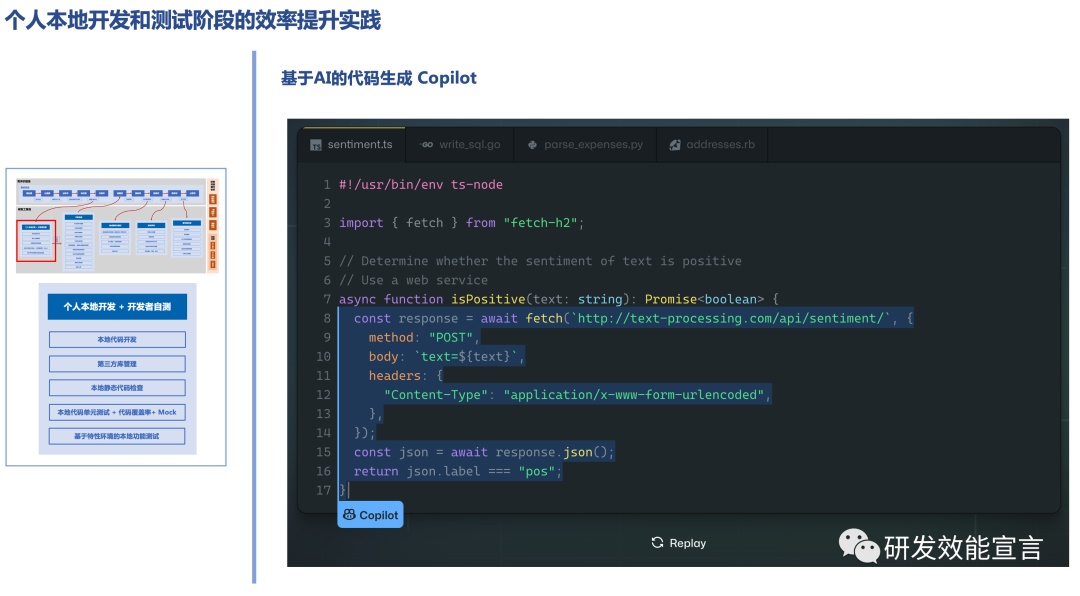
- 精准代码填充
其中,比较著名的是微软在 2021 年发布的Copilot,这个插件能够根据函数名、注释和代码本身的上下文判断代码意图,自动生成可运行的代码,辅助编程。
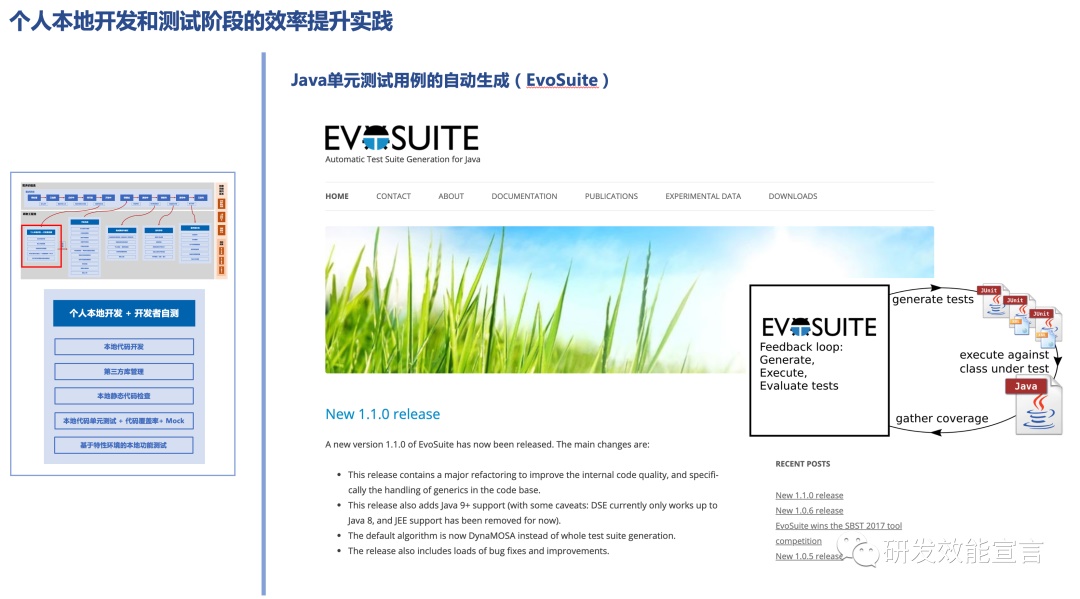
- 单元测试的自动生成
可以使用工具直接对被测代码生产单元测试用例,可以大幅度提升单测的开发成本。简单逻辑的单测由工具自动生成,人可以聚焦在复杂逻辑的部分。目前主流的工具有EvoSuite和基于AI的Diffblue Cover。
- 轻量级的Mock工具
选择轻量级并且功能强大的Mock工具会让单元测试的过程变得十分顺畅。比如阿里的TestableMock就是一款很不错的Mock提效工具。

- 更多的实践
本地开发和测试件阶段还有很多优秀的实践可以提效效能,降低随机复杂性,比如本地集成测试的特性环境能力、代码提交前的强制本地检查、静态代码本地集成、规范化的第三方库管理、本地构建提速等,由于篇幅关系就不再展开了。
