
在今年3月写过一篇文章:又一次被震惊:从生成和细化需求到应用各种方法设计测试用例 ,展示了chatGPT生成测试用例,而且可以用不同的方法生成测试用例,在我们的引导下它还能补充测试用例、完善测试用例。半年之后,chatGPT的能力强大许多,而且是多模态的,如下面例子所表现,所以我们更能借助LLM完成从生成验收标准、生成测试计划、生成测试用例、生成测试脚本到生成测试报告等全测试周期所需的交付件。

(基于简单的描述生成非常规范、完整的测试用例。)

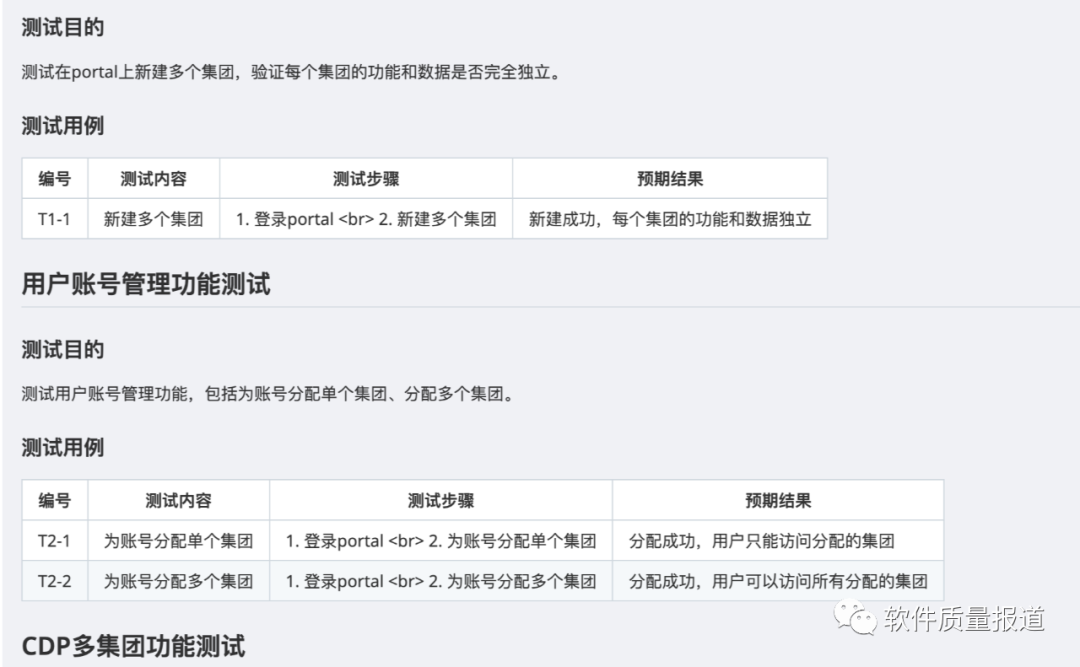
(基于流程图生成E2E的测试用例)
自然不能用这些相对简单的例子(基于流程图生成E2E的测试用例也不简单,是真实案例)或几行字来回答标题所提出的问题:大模型真的会让软件测试人员下岗吗?即使大模型真的有潜力让软件测试人员下岗,也不是现在,而是3-5年后。为什么这么说呢?那是因为在长沙、在沈阳,一些专家和学者在讨论“大模型会成为软件工程的银弹吗?” 多数人认为很有可能,而且在未来3-5年或更长时间(10年)这一时刻会出现。
类似开发人员,人们会说:大模型会淘汰码农,但不会淘汰软件工程师。也就是说,如果你只是一个平庸的程序员,缺乏业务素质、工程能力、沟通协调能力,只会写代码、完成具体功能的代码实现,很有可能被淘汰,因为具体任务的代码很有可能由AIGC自动生成。虽然现在代码采用率不高,但可以由资深程序员来review和完善,因为有40-50%的工作被LLM干了,人员是可以优化的。如果要优化,那么上面说的“码农”被优化掉的可能性很大。
测试人员也有类似的场景,如果只是能干一些简单的测试设计、测试执行的工作,那很有可能会被淘汰。因为在普遍使用LLM情况下,大量的验收标准、测试用例、测试脚本、测试计划、测试报告被自动生成,测试团队自然也会被优化,而能力弱的、只会干简单工作的测试人员被优化掉的可能性也是很大的。
从这个角度看,其实是会用大模型的测试人员淘汰不会用大模型的测试人员。
我们如何成为会用大模型的测试人员呢?简单地说,就是拥抱大模型,躬身入局,不断实践、应用大模型,不断学习新的知识和新的工具,与时俱进,持续进取。具体说,分三步走。
第一步就是一面学习提示工程、一面在chatGPT或相应的工具上去实践。
提示工程,可以好好理解下面两张图,理解提示的结构和技巧(Few-shot Prompting)。如果可能,可以进一步了解思维链(CoT)等内容。还可以加约束,设置输出模板或Markdown格式。
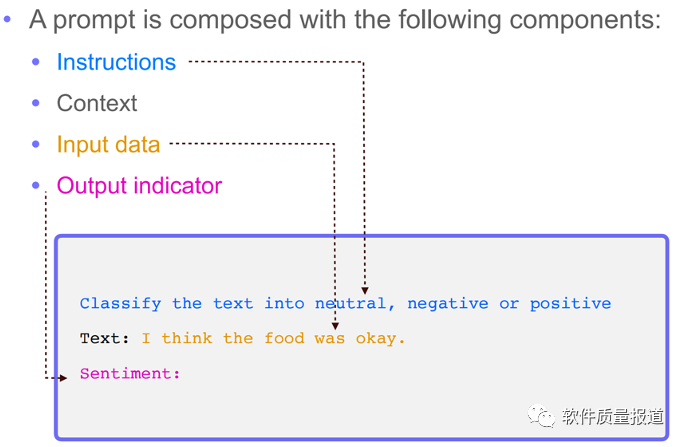
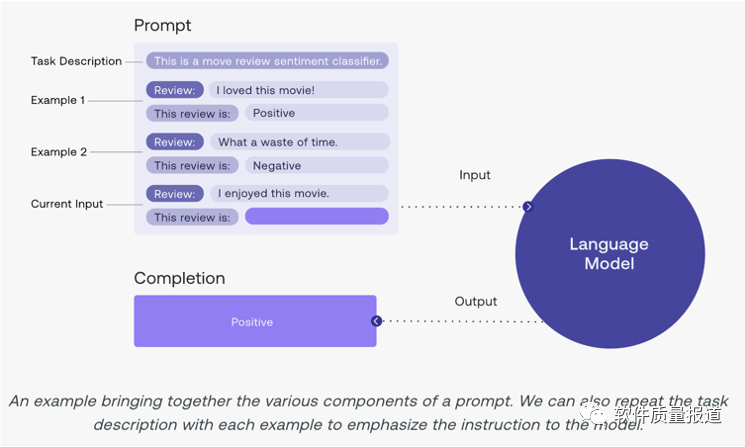
例如,生成按文档模板要求的、规范的测试计划、测试用例。
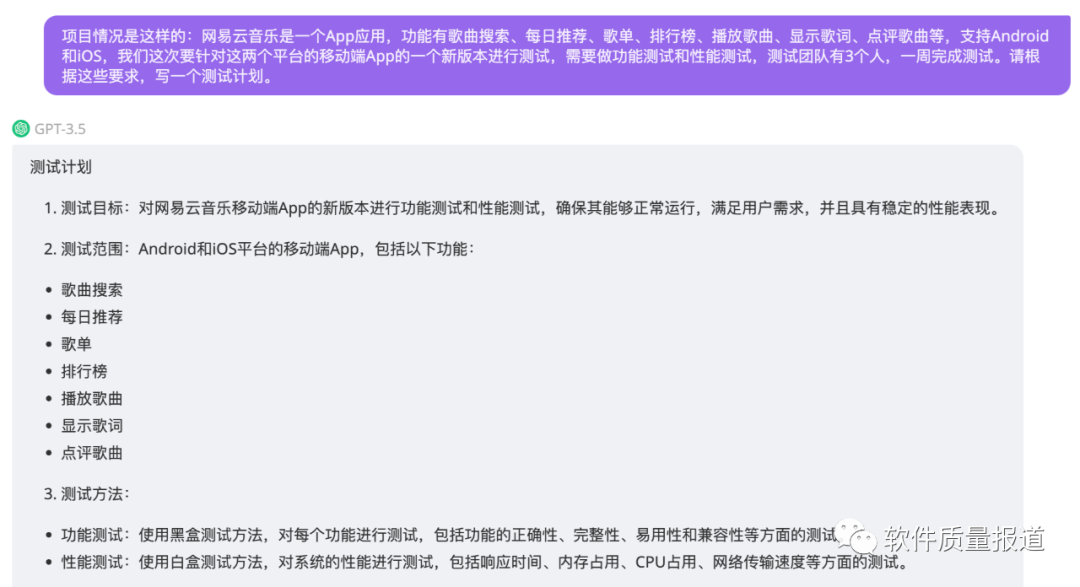
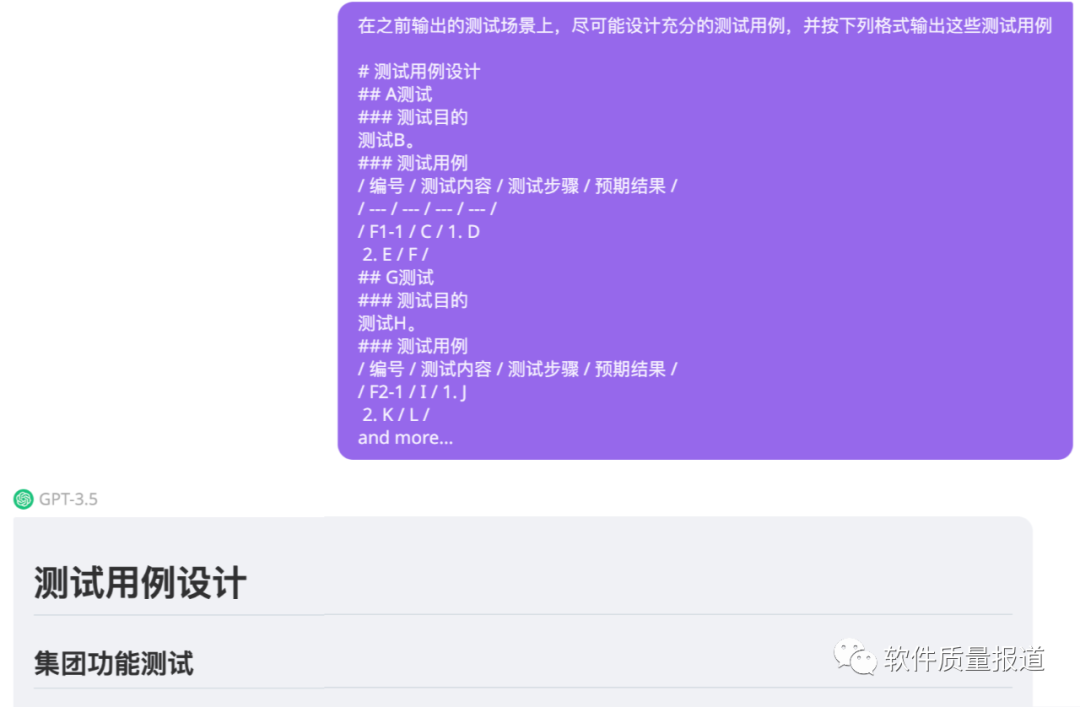
第2步,在这基础上,可以多了解其他同事、其他公司的一些优秀实践,或多看一些和测试领域应用大模型技术相关的论文,例如Adaptive Test Generation Using a Large Language Model,了解Transformer机制、预训练和fine-tuning等方面的知识,深度了解如何训练出一个测试大模型,提升自己的理论水平。

第3步,尝试部署开源大模型(如Llama 2),在此基础上,尝试用自己的测试数据精调(fine-tuning)出自己的测试大模型,应用于实际工作中。这一步,的确有挑战,从数据的准备、清洗和优化到数据构造,然后开始进行fine-tuning。在fine-tuning过程中,可以调整模型的超参数,如温度系数、学习率、窗口大小等,甚至可以学习高效微调技术(如LoRA)。然后使用验证数据集对fine-tuning后的模型进行验证,以评估模型的性能。这个过程会经过多次训练、验证,最终达到一个好的性能才算结束,最后将模型部署到研发环境中,供大家使用。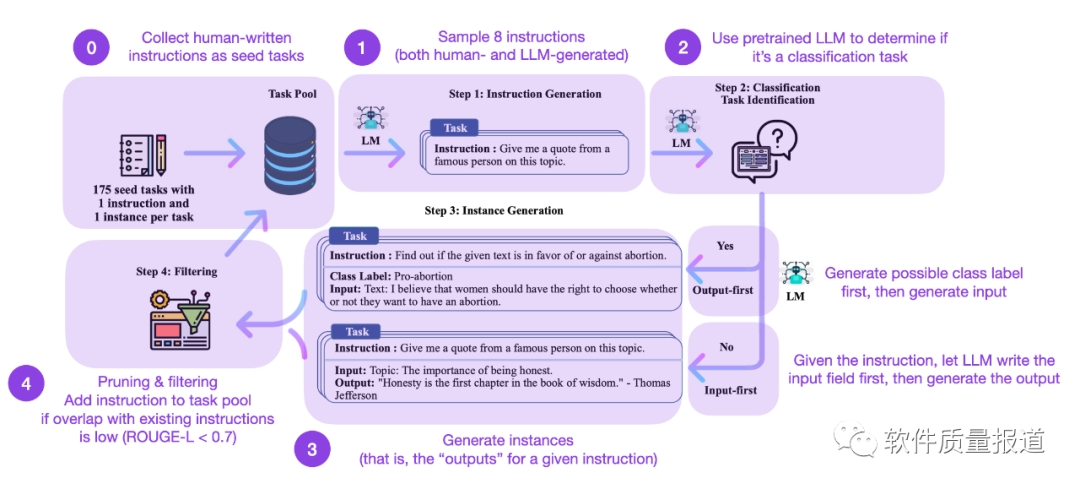
经过这样一个过程,自己以后就拥有了一个强大的测试助手,自然对公司的价值更大,使自己立于不败之地。
当然,也没有这么简单,看了一篇简单的文档,自己就飞起来了,不可能。需要在工作中要脚踏实地去实践、去思考、再实践;需要走出去,多取经、多学习。
