有一家网站,全球流量排名第56位,但是只有23台服务,这是什么神奇的软件架构在支持,它是如何做到的?这家公司就是StackOverflow,程序员应该都知道,不知道的码农以后一定会用到的,特别是一些诡异Exception的查找,很多线索都在StackOverflow。
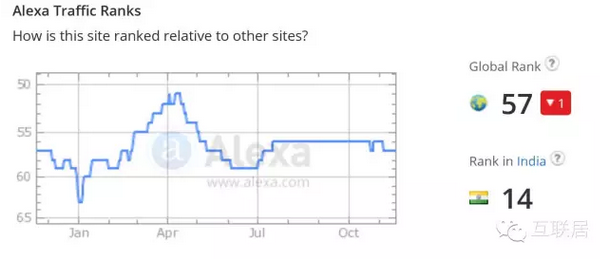
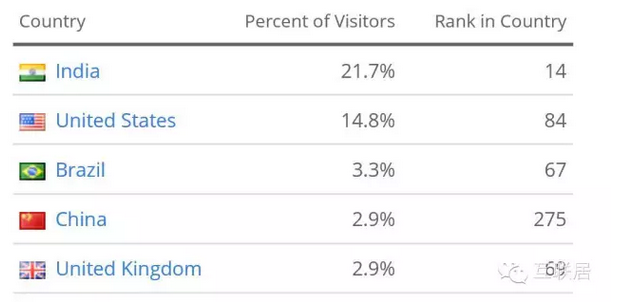
StackOverflow的全球流量排名是56名,比较类似流量的网状还有(jd.com78名,sohu.com 43名)。该网站在印度的排名是14名,美国排名是84,中国的排名是275名,看起来还是印度的码农多啊,中国赶双十一买东西的人多。
废话少说,一种图看懂它的23台服务器,2台接入服务器,9台Web服务器(64G Windows),4台MySQL(384G,1.2T SSD, Linux),2台Redis(96G),3台ElasticSearch(196G,Linux),3台标签服务器(32G)。不用介绍,几个模块各司其职,逻辑都在Web服务器,Redis当作Cache,ES服务做搜索索引,Tag服务用于文章的标签管理。

StackOverflow的技术VP David在回答他们是如何做到的,总结了2点:
1.这个软件架构是很"烂"(Boring)的
2.保持一个很“烂"的架构是非常有趣的
在这么“烂”的架构下,这么少的机器数量,居然能够支持巨大的访问量,而且所有机器的CPU都不到10%,真是有些羡慕嫉妒恨啊:
-9.4M 问题
-16M 回答
-45M 月活跃人数
-用户 QPS 顶峰3000/s
-SQL QPS 顶峰8000/s
再看看他们的研发团队,34个开发人员(全栈工程师),6系统管理员,6个设计人员。75%的人都是远程工作,分布在世界各地。
他们的架构理念是什么?David总结了三部曲
1. 从自己熟悉的技术开始
公司开始的时候,程序员熟悉.NET,那么他们采用ASP.NET,不断的用精,用深,一直到现在。最初使用的技术包括,ASP.NET MVC, LINQ2SQL 。他们也曾经考虑过转型,但是现在的架构,能够支持业务的发展,为什么不用呢? 不用云也可以做的很出色的。
2. 在产品中的度量(Measure it live)
性能是非常重要的功能(Feature),性能测试需要在产品中进行,才能真正得到靠谱的数据,这也是在产品中测试的概念(Testing in Production)。设计好测量方法,通过数据结果进行判断。下面就是一个性能示意图。
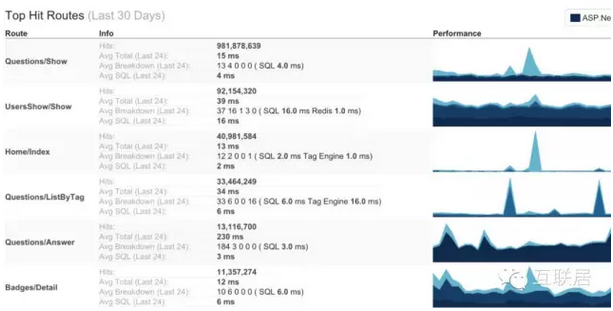
3. 修复性能问题
当局部的性能有问题,就应该开始修复,不要等到整个系统都变慢的时候才开始考虑性能问题。提早发现和解决性能问题,将会避免整个产品的悲剧。StackOverflow也通过引入很多新技术和模块,提升了性能,例如通过Redis增加Cache能力,通过ElasticSearch提升搜索的性能。部署的时候也是通过增大内存,保证所有的数据内存可用,无需访问磁盘或者SSD。
虽然,整个架构看起来很Low,但是对他们业务来说,已经用的很好了,任何一个架构都是为业务服务的。这虽然是一个朴素的“单体”架构,通过增加内存Scale Up,最简单的方法解决业务增长的问题。
给自己的几个思考
-
业务是推进架构的演化和升级的原动力
-
加大数据度量,数据是所有决策的基础,不要赶时髦,人云亦云
-
利用自己熟悉的技术解决问题,数据化衡量新技术引入复杂度和新问题
参考文章:
《Scaling Stack Overflow》David Fullerton, VP Engineering • QCon NYC • 2015-06-12
