1 相关说明
1.1 背景简介
随着一个产品的自动化工作不断深入,自动化的case积累数量持续增长,绝大部分毫无依赖关系的case由于串行运行,测试执行时间达到小时界别,且不易于优化。另外,ci运行时所需机器资源的抢占互斥,运行机器的不稳定等问题也逐渐扩大。
Hadoop分布式测试执行方案正是为了解决以上问题而产生,通过分布式执行,可以达到并行运行,提高执行效率的目的;另外,hadoop提供调度,重试等机制功能,可以提供给用户一个相对透明的计算资源池,减少用户对机器运行环境的依赖。

1.2 分布式平台的选择
本方案采用hadoop来作为分布式平台。首先是Hadoop是一个开源项目,有非常好的技术支持,二就是hadoop有成熟的分布式调度算法,可以很好的利用每台机器的cpu和内存资源,达到计算资源最优分配,三就是hadoop程序易于编写,便于维护。
1.3 名词解释
:apache基金会的开源分布式框架。
Mapreduce :hadoop的计算模型,由map任务和reduce任务组成。
Jobtracker :hadoop计算系统的总控。
Tasktracker :hadoop计算系统的子节点。
Slot(槽位) :tasktracker的最小计算分配单元,一个槽位可以对应一个map任务,一个机器启动一个tasktracker,槽位的话按照机器的cpu核数来分配,一般是”核数-1”。
<2 分布式测试执行方案
2.1 传统的单机测试执行流程
一般的单机测试流程分为5步,如下图所示:
1、lib库安装。包括测试框架的lib库安装以及基于该测试框架的产品业务层lib。
2、测试环境安装。主要指被测对象的测试环境安装,包括数据库安装,server端安装等。
3、case下载。从svn或者case库获取需要执行的case。
4、case运行。
5、发送报告。
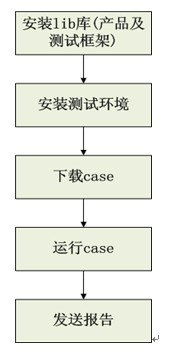
单机测试执行的优点在于逻辑简单,易于实现,缺点就是case要串行执行,无法有效里有机器的cpu和内存资源。举个例子,现在有一个8核16G的测试机,每个case的平均cpu使用率为10%,内存消耗1G,在这样的情况,一般可以做到至少6个case并行化,优化效率是不言而喻的。
2.2 从单机测试到分布式测试执行的逻辑
有了以上的五个步骤及相关分析,我们考虑其中可以并行执行来进行优化的就是测试执行这块了,其他lib库安装,测试环境安装等都基本是最小单元,不易切分了。
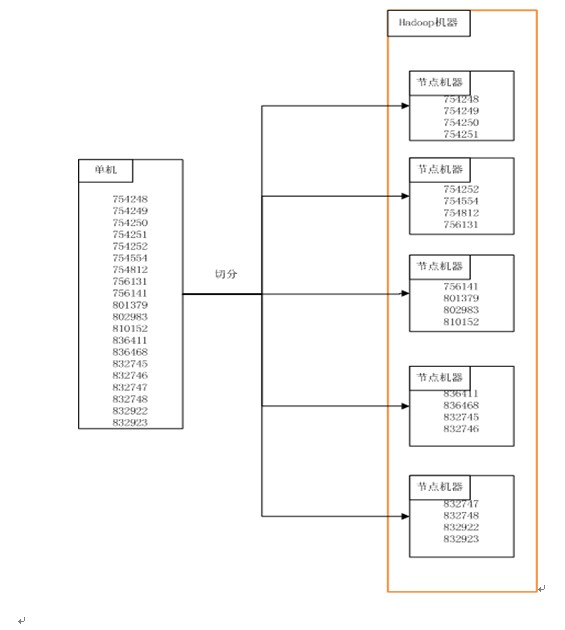
所以从单机到分布式主要是Case执行集合的一个拆分。所以简单说,单机和分布式的区别就是case输入集合有变“而已,其他单机的测试执行过程基本不变。对于测试工程师来说,这个过程是透明的,只是执行case的环境从单机切换到多机。
下图简要的表示了case从单机到多机的变化(6位的数字是caseid)。
2.3 分布式运行逻辑
这里的逻辑主要是两块,一部分是本地部分,一部分是分布式节点机器部分。我们将分布式测试执行过程封装到一个hadoop job里。
本地部分:
1、获取计算资源。这里的计算资源指可用的tasktracker的槽位数,这个槽位是case切分的分母。
2、根据计算资源生成case列表。有了槽位数,最简单的切分算法就是:每节点case数=总case数/槽位数。
3、业务层自定义操作。例如业务层测试执行时需要的程序或者配置获取,依赖的大数据推送到hdfs等。
4、配置hadoop的job。包括input,output,执行job所需的文件或者tar包等。这里的input就是case列表。
5、执行测试执行job。这个实际是个hadoop job。
6、发送报告。汇总每个节点的运行结果,并发出报告。
每个tasktracker的map任务输入是切分后的case列表,通过这种方式将整个测试执行部分分发到每个tasktracker上。
节点部分:
1、准备case列表。从map的input获取。
2、根据case列表下载case。,这里类似于本地单机版的case获取,来源仍然是SVN或者CASE库。
3、安装lib库。同本地单机版。
4、安装测试环境。同本地单机版。
5、执行case。同本地单机版。
6、推送报告。
这里hadoop还会根据每个map任务的返回值,来进行重试运行的调度。
从以上的描述可以看到,在hadoop集群节点机器上(tasktracker),测试执行的逻辑和单机版基本无差别,所以整个改造的过程也是比较简单的

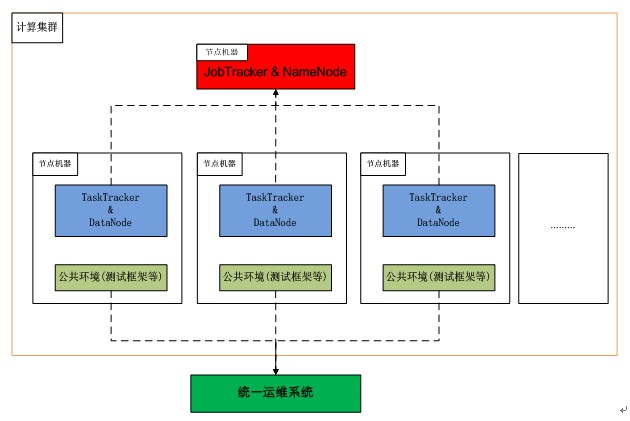
2.4 分布式测试集群架构设计
整个分布式测试执行依托于一个公共的计算集群,这个计算集群由两部分组成,一部分是hadoop相关的,包括hadoop的总控,子节点的tasktracker服务。另外一部分就是公共环境,包括测试框架,公共工具例如valgrind等。前者通过jobtracker来管理,后者通过统一运维系统来管理,其功能基本就是公共环境的安装和维护。
3 收益
经过我们的实际项目实践,这部分的收益主要体现在如下两点:
1、测试执行时间大幅优化。15台机器的情况,所有原测试执行时间要1-2小时的模块,优化到10分钟以内。
2、机器资源的节省。通过公共集群的维护,保证所有机器cpu满负荷运作,避免了以往单机测试执行的cpu浪费。
4 准入原则及发展方向
4.1 分布式改造的准入原则
并不是所有的测试执行都可以分布式化,在我们的实际操作过程中,总结出以下几点准入原则,供参考:
1、空白机器可运行。通过一个总控脚本就可以做到依赖环境准备,lib库安装,测试case执行等。
2、测试框架允许case并行。
3、业务层case对外部不存在固定依赖,例如依赖于某个写死的目录。
4、业务层case依赖的server端口,最好是随机的。
5、不允许业务层去操作公共环境。
4.2 后续可能的技术方向
1、case按照执行时间切分。按照时间切分来替代按照case数切分。
2、从分布式测试执行过渡到云测试服务。
