

发现拆解代码覆盖率指标的简单证明
代码覆盖率是衡量软件产品质量的一个强有力的指标,多年来,技术领导者们对此深信不疑。从表面上看,其理由似乎很充分:测试越彻底,代码覆盖率就越高,因此,我们的软件就应该越健壮,越能防止错误。这就是我们脑海中根深蒂固的想法。但是,如果我有证据证明代码覆盖率从根本上就是错误的呢?如果我能向你展示这样一个简单的想法,让你不再怀疑呢?那么,请做好准备,振作起来。
代码覆盖范围
代码覆盖率的最简单形式就是衡量测试 “触及 “或 “覆盖 “了多少代码。我们假设,在我们的产品中,我们至少在每次发布之前都测试并运行了这些测试。当这些测试执行时,它们会对产品执行操作,使代码得以执行。很快,我们就会意识到,如果跟踪测试执行了哪些代码,我们就可以开始衡量执行了多少代码。对于已执行代码与产品中代码总量的比率,我们称之为 “代码覆盖率”:
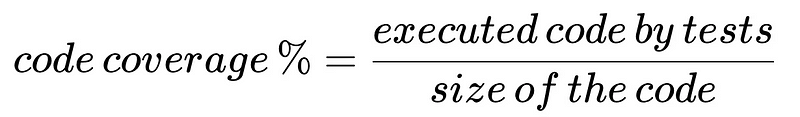
这是一个非常简单的指标。如果我们有100行代码,但测试只执行了其中的75行,那么我们的代码覆盖率就是75%。但很快,我们就意识到了更大的问题。如果代码覆盖率不是100%,那么我们的代码就不会被测试执行,或者换句话说:我们的代码未经测试!
因此,未经测试的代码是危险的,因为它可能包含错误。此外,它还可能包含关键业务功能,如果我们触碰这些代码,就会失去这些功能。所以,代码覆盖率高是必须的。
代码覆盖谬误
但是,现在我们要面对一个谬误:我们知道,揭露代码意味着我们的测试会遗漏重要的情况,但事实并非如此。例如,在前面的例子中,我们的代码覆盖率为75%。换句话说,该指标显示有25%的代码行没有通过任何测试,这就指出了一个风险区域。我们可以肯定地说,任何测试都没有验证这25%的代码库,因此,这可能会成为问题和维护问题的温床。
然而,就在这时,我们有可能陷入谬误:虽然我们可以肯定地说,未经测试的代码隐藏着潜在的错误和对未来开发的阻碍,但我们也可以相信,事实恰恰相反。我们可能会认为,代码被覆盖就意味着它的错误和维护问题更少。但是,这种看似合乎逻辑的直觉可能会被证明是不正确的。现实情况是,我们可以拥有100%的代码覆盖率,但仍然会有错误百出、难以维护的代码。
一个基本例子
试想一个计算两个数字之和的简单函数:
function addition(a, b) {
return a + b;
}
最简单的测试是什么?只需增加一项,就能执行所有代码:
test('the addition function', () => {
addition(3, 4);
});
该测试覆盖了 100% 的代码。然而,它却毫无用处。为什么呢?如果我们把加法的实现改成这样:
function addition(a, b) {
return a - b;
}
测试仍然通过!
如果您是程序员,您可能已经知道问题所在。问题不在于代码覆盖率,而在于测试本身。测试覆盖了100%的代码,但并没有断言或检查任何东西。这就是为什么错误的实现(减法而不是加法)仍能通过测试的原因。所以,这似乎是个坏例子……其实不然。
事实证明,对于这个非常简单的小例子,我们很容易就能发现测试中存在的问题。但是,如果代码库有成千上万行代码,情况会怎样呢?会有人能轻易找出没有正确验证结果的测试吗?这种可能性很小。因此,测试可能有问题,断言可能有错误,场景可能被忽略,但我们仍然可以夸耀100%的代码覆盖率。这正是问题所在。
根本原因
造成这一问题的根本原因在于,代码覆盖率是一个关于代码而非业务的指标。虽然这是一个很好的指标,可以发现代码中可能未经测试的部分,但它对业务以及项目在多大程度上满足业务目标的说明却很少。
代码覆盖率侧重于软件测试的技术方面,而不一定考虑软件所要实现的更广泛的业务目标和要求。它衡量的是已测试代码的范围,但无法深入了解软件是否达到了预期目的、满足了用户需求或符合更广泛的业务战略。代码覆盖所做的唯一一件事就是评估在测试过程中是否执行了所有代码。而这是很容易实现的:
规则 1:运行所有方法。为每个函数编写一个执行它的测试。这将涵盖所有方法。因此,如果有两个函数,就写两个测试。
function one() {
// ...
}
test('function one', () => {
one();
});
function two() {
// ...
}
test('function two', () => {
two();
});
规则 2:运行所有分支。为每个条件创建一个额外的测试,以确保它满足条件。这将涵盖任何分支内的所有代码。
function conditional(condition) {
if (condition) {
// ...
} else {
// ...
}
}
test('condition true', () => {
conditional(true);
});
test('condition false', () => {
conditional(false);
});
请注意,并非一定要编写额外的测试才能实现 100% 的代码覆盖率:
function conditional(condition) {
if (condition) {
// ...
}
// ...
}
test('conditional', () => {
conditional(true);
});
不需要更多的规则。我已经展示了 “if “语句,但 “while “和 “switch “也是如此。对其他函数的调用已经包含在规则 1 中,所以就到此为止。这些规则说明了什么?什么也没说。这就是问题所在。
真实经历
我想讨论两个代码覆盖有欺骗性的案例。
几年前,在一次聚会上,我遇到了一位在软件开发公司工作的开发人员,他向我介绍了他为 FDA(美国食品和药物管理局,隶属于美国卫生与公众服务部的一个联邦机构)准备产品的经历。情况如下:FDA 要求 60% 的代码覆盖率,而他们的产品没有测试,因此代码覆盖率为 0%。当 FDA 要求 60% 的代码覆盖率时,他们希望看到至少 60% 的软件代码在测试过程中得到验证。这是一种保证软件在不同条件下正确运行的方法。至少,这就是他们的初衷。
所以到底发生了什么?由于没有测试,他们开始创建测试。起初,他们试图创建有意义的测试,彻底检查最关键的功能,验证各种条件下的正确行为。但随着时间的推移,创建这些测试变得越来越困难,代码覆盖率也几乎没有提高。很快,他们意识到自己在与时间赛跑。
绝境需要绝招。他们将重点从创建有价值的测试转移到提高代码覆盖率上。他们执行测试,查看代码覆盖率报告,调整测试以通过代码的最大部分,从而快速提高代码覆盖率。他们放弃了对有用测试的任何考虑,将数量置于质量之上。历时三个月,他形容这是他整个开发人员生涯中最糟糕的经历。
现在,你可能会想,这是一种极端的情况,他们的行为至少是有问题的,而且,这肯定不是软件行业的普遍做法。那么,请再想一想。事实证明,每个开发人员在每次交付时都会遇到同样的定时炸弹。因此,如果开发人员被迫交付带有测试的代码,具有一定的最小代码覆盖率,并满足任意的截止日期要求(即使他们已经估计了截止日期),那么之前的经验也同样适用。
这就是我的第二次经历。前段时间,我的一位客户要求我协助他的团队进行一项测试。当时有很多关于测试的讨论,大家都觉得测试既费钱又费时。公司要求至少有 80% 的代码覆盖率,整个情况让我想起了之前的经历。
于是,我做了唯一合乎逻辑的事情:我下载了代码,查看了测试,一个小时后,我发现自己无法理解其中的任何内容。我进行了测试,测试通过了,于是我开始做实验。因为我不明白测试到底是如何进行的,所以我拿到了代码,并故意把它弄坏了。结果让我大吃一惊:虽然代码被破坏了,但测试仍然通过了。之所以能实现代码覆盖率,不是因为测试工作做得很彻底,而是因为他们不小心运行了代码。这两次经历都给了我一个明确的提示:强迫代码覆盖率并不是一种好的管理方法。
实验
按照约定,我将介绍一个简单而有效的实验,它将证明代码覆盖率作为管理指标毫无疑问是无用的。
它是基于艾伦-霍卢布的以下观点:
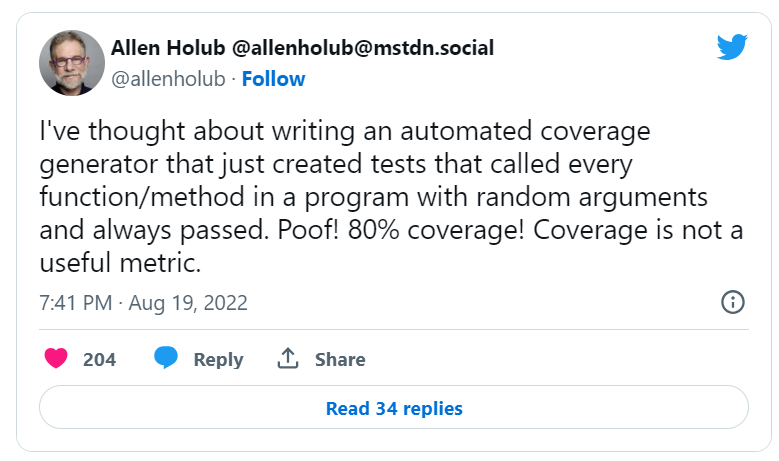
这个想法很简单,对吗?正如我前面提到的,要实现100%的代码覆盖率,我们只需满足两条规则:1) 执行所有函数,2) 执行所有分支。事实证明,Allen Holub的建议正是如此:1)让测试执行所有函数/方法;2)使用随机参数覆盖分支。
如果我们这样做了,那么这种测试会对我们的业务目标产生什么影响呢?什么都没有!它只会无情地运行所有代码,而不会考虑我们的业务。这将是懒惰的开发人员的终极表现。
那么,问题来了:Allen Holub说得对吗?创建自动代码覆盖可能很有挑战性,但如果我们仅限于随机输入,而不需要分析代码分支,其复杂性就会大大降低。那么,让我们开始吧!在第一种方法中,我选择了Java。由于具有反射功能,Java是一种相当容易实现自动测试的语言,而且我已经有了一些公共代码库,可以用来检查生成器。因此,我在这里做了第一个概念验证:
这段简单的代码只创建所有带有公共构造函数且不带参数的类实例,并执行所有不带参数的方法。虽然它很简单,但已经实现了11%的代码覆盖率。虽然远低于80%,但这是意料之中的。
此时,我需要开始执行带有参数的构造函数和方法。此外,我还可以通过“作弊”的方式直接执行私有方法,使用Spring或JPA所依赖的相同机制。这就打开了一个新的兔子洞。因此,在这一点上,有了正确方向上的第一个概念证明,以及作为大学老师将此实验转化为最终学位项目的机会,我决定将此实验列入提供的最终学位项目中。
在此,我不得不说,我非常感谢Gerard Torrent。他接受了挑战,虽然他们的学位几乎没有编译器理论方面的知识,但他创造了一种不同的方法,让我们更好地理解了编译器理论。他建立了一个代码生成器,为每个方法和可能的参数创建一个测试,而不是做一个走遍所有代码的测试。他不断增加功能,比如当方法需要其他对象时,他就创建这些对象,一次又一次地迭代,从而提高了代码的整体覆盖率。有时,他独自工作。有时,他独自工作;有时,我们联手进一步提高代码覆盖率。
结果
我们实现了80%的代码覆盖率,甚至更高。我请Gerard进行迭代,一步一步地得出结果,以便更深入地了解代码覆盖的工作原理。因此,一步步实现的代码覆盖率是:
- 我的首次参考实施:11%
- 执行所有以空值作为参数的构造函数:20%
- 只执行公共无效方法:23%
- 执行所有公共方法:50%
- 执行所有方法,包括公共方法和私人方法:50%
- 创建所需参数的实例(不再有空值):65%
- 为所需实例创建实例(嵌套):69%
- 测试每个参数的三个不同值:69%
- 尽可能使用Spring对类进行实例化:85%
请注意,测试私有方法是一种反模式,不要这样做,但它是本演示的一部分,因为它有助于人为地增加代码覆盖率。
因此,最终的结果是:85%的代码覆盖率。这就是在不考虑任何业务因素的情况下生成代码。那么,现在怎么办?
结论
Allen Holub之所以在评论中将80%作为目标,并不是因为他认为这是一个合理的目标—他可能会这么认为—— 因为80%是大多数公司的共同要求。他在寻找一种方法来驳斥强制代码覆盖率最低的必要性。因此,现在我们知道,我们可以构建一个简单的库,无论你的业务是什么,它都可以执行大部分代码,并人为地提高代码覆盖率。我们不需要人工智能,不需要花哨的LLM,不需要代码复杂性分析,只需执行随机函数,就能满足任何公司对最低代码覆盖率的大部分要求。
即使在代码覆盖率可以稍高一些的公司,也可以通过手工测试来达到额外的覆盖率要求。那么,将代码覆盖率作为管理指标的结果是什么呢?一无所获。以前,我们知道开发人员可以通过伪造代码来提高代码覆盖率,而无需进行测试。现在,我们也知道快速自动工具可以迅速提高覆盖率。因此,如果仅仅随机执行代码就能达到很高的代码覆盖率,那么这个指标就失去了作用。
下一步
下一步该怎么做?既然代码覆盖率对管理毫无用处,我们现在能做什么?
首先,也是最重要的一点:代码覆盖率对开发人员来说仍然很重要。Martin Fowler等许多人早就说过这一点。他在这篇文章中解释说,代码覆盖的唯一目的是找到未经测试的代码。这有助于开发人员发现自己在创建代码时的错误和错误的假设。如果应用得当,代码覆盖失败可以引发重要的业务对话,从而发现新的功能或误解。
其次是TDD或BDD。毫无疑问,这可能是创建测试的唯一合理方法。当开发人员被迫创建测试,而且是在代码之后创建测试时,主要的问题是没有人能确保这些测试能正确工作。我们需要观察它们的失败,看看新代码是如何纠正这些失败的,只有这样才能让我们确信我们创建的测试是正确的。
最后,我们应该专注于业务。期间。只有当测试有助于验证业务主张是否按预期运行时,测试才有意义。因此,与其依赖只关注代码的晦涩指标,我们可以选择其他更关注业务的指标。业务规则覆盖率就是一个例子:
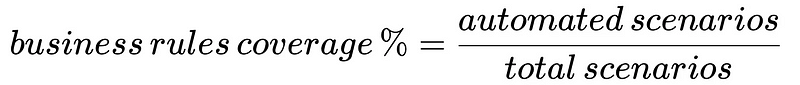
这是一个相当简单的指标,类似于代码覆盖率,但也存在一些问题。
“工作软件是衡量进步的主要标准”——《敏捷宣言》原则。感谢你的阅读。我通常喜欢通过写故事来思考我们是如何理解和应用软件工程的,并让我们思考可以改进的地方。
