
二月份,Meta的研究人员发表了一篇名为《使用大型语言模型在Meta中自动改进单元测试》的论文,介绍了一款他们称之为TestGen-LLM的工具。这种完全自动化的增加测试覆盖率的方法“保证了对现有代码库的改进”,在软件工程界引起了轰动。
Meta没有发布TestGen-LLM的代码,所以我们决定将其作为我们开源Cover Agent的一部分来实现,并且今天发布了它!
我将分享一些关于我们如何实现它的信息,分享我们的发现,并概述在实际使用TestGen-LLM与现实世界代码库时遇到的一些挑战。
**自动化测试生成:基线标准 **
使用生成式AI进行自动化测试生成并不是什么新鲜事。大多数能够生成代码的语言模型,例如ChatGPT、Gemini和Code Llama,都可以生成测试。当使用语言模型生成测试时,开发人员遇到的最常见的陷阱是大部分生成的测试甚至不能运行,并且许多测试没有增加价值(比如它们测试的功能已经被其他测试覆盖了)。
为了解决这个挑战(特别是对于回归单元测试),TestGen-LLM的作者提出了以下标准:
1、测试是否能够正确编译和运行?
2、测试是否增加了代码覆盖率?
如果没有回答这两个基本问题,可以说接受或分析由语言模型提供的生成测试是没有意义的。 一旦验证了测试能够正确运行并且增加了我们正在测试的组件的覆盖率,我们可以开始手动审查:
1、测试编写得怎么样?
2、它实际上增加了多少价值?(我们都明白有时候代码覆盖率可能只是一个代理指标甚至是虚荣指标)
3、 它是否满足我们可能有的额外要求?
**方法和报告的结果 **
TestGen-LLM(以及Cover-Agent)完全无头运行(好吧,某种程度上来说是这样的;我们稍后再讨论)。
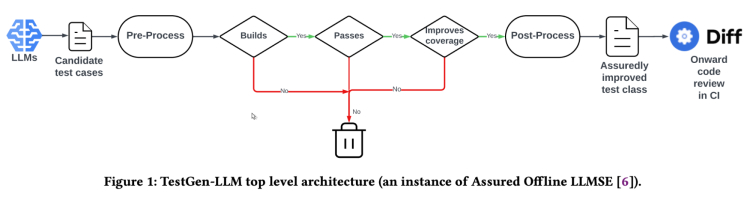
首先,TestGen-LLM会生成一批测试,然后过滤掉那些无法构建/运行的测试,并丢弃那些未通过的测试,最后丢弃那些没有增加代码覆盖率的测试。在高度受控的情况下,生成测试与通过所有步骤的测试的比例为1:4,在真实场景下,Meta的作者报告的比例为1:20。
在自动化过程之后,Meta有一名人工评审员接受或拒绝测试。作者报告的平均接受比例为1:2,在最好的报告案例中,接受率为73%。
重要的是要注意,如论文所述,TestGen-LLM工具每次运行生成一个单一测试,该测试添加到由专业开发人员先前编写的现有测试套件中。此外,并不一定为给定的测试套件生成测试。
从论文:“总共,在三次测试马拉松活动中,成功改进了196个测试类,而TestGen-LLM工具应用于总共1,979个测试类。因此,TestGen-LLM能够自动改进其应用的约10%的测试类。”
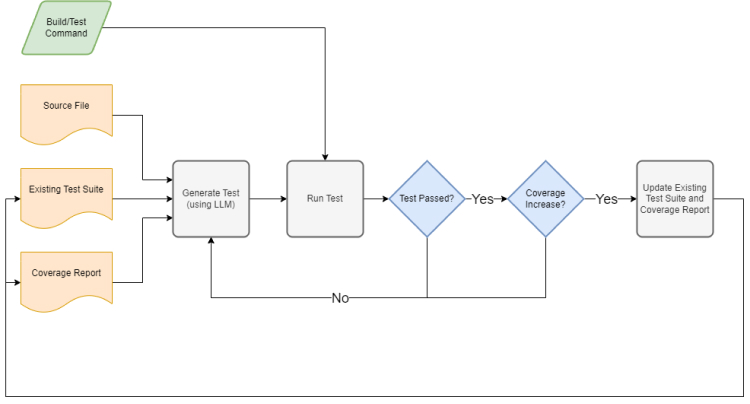
**Cover-Agent Cover-Agent v0.1 流程 Cover-Agent v0.1 实现如下:**
1. 接收以下用户输入:
1. 待测代码源文件
2. 需要增强的现有测试套件
3. 覆盖率报告
4. 构建和运行测试套件的命令
5. 代码覆盖率目标及最大运行次数
6. 附加上下文和提示选项
2. 生成更多相同风格的测试
3. 使用您的运行环境验证这些测试
1. 它们能构建并通过吗?
4. 通过查看诸如增加的代码覆盖率之类的指标来确保测试增加了价值
5. 更新现有测试套件和覆盖率报告
6. 重复直到达到标准:要么达到代码覆盖率阈值,要么达到最大运行次数
**在实现和审查TestGen-LLM时遇到的挑战 当我们致力于将TestGen-LLM论文付诸实践时,遇到了一些令人惊讶的挑战。**
论文中提到的例子使用Kotlin编写测试——一种不使用显著空白的语言。然而,像Python这样的语言,Tab和空格不仅重要而且是解析引擎的要求。不太复杂的模型,如GPT 3.5,不会返回始终正确缩进的代码,即使明确提示也是如此。例如,当涉及到每个测试函数都需要缩进的Python测试类时,我们就必须在整个开发周期中考虑到这一点,这给预处理库带来了更多的复杂性。仍有大量工作需要完成以使Cover-Agent在这种情况下更加健壮。
鉴于检索增强生成(RAG)在基于AI的应用程序中越来越普及的趋势,我们发现提供更多的上下文有助于生成高质量的测试和更高的通过率。我们为希望手动添加额外库或文本设计文档作为上下文的用户提供了`–included-files`选项,以增强测试生成过程中的语言模型。
复杂的代码需要多次迭代,这对语言模型提出了另一个挑战。随着未通过(或未增加价值)的测试的生成,我们注意到一个模式,即后来的迭代中反复建议相同的未被接受的测试。为了解决这个问题,我们在提示中增加了一个“失败测试”部分,以向语言模型传递反馈,确保它生成独特的测试,永远不会重复我们认为不可用(即损坏或没有增加覆盖率)的测试。
在这个过程中出现的另一个问题是,当扩展现有测试套件时,无法添加库导入。开发人员有时会在测试生成过程中过于狭隘,只使用单一的测试框架方法。除了许多不同的模拟框架外,其他库可以帮助实现测试覆盖。由于TestGen-LLM论文(和Cover-Agent)旨在扩展现有的测试套件,所以重新构造整个测试类的能力超出了范围。在我看来,这是测试扩展而非测试生成的一个限制,我们计划在未来版本中解决这个问题。
重要的是要区分TestGen-LLM的方法中,每次测试都需要开发人员手动审查才能建议下一个测试。而在Cover-Agent中,我们生成、验证并尽可能多地提出测试,直到达到覆盖率要求(或达到最大迭代次数),而无需在此过程中进行人工干预。我们利用AI在后台运行,创建了一种不干扰自动测试生成的方法,允许开发人员在过程完成后一次性审查整个测试套件。
结论与未来展望
虽然许多人,包括我自己,对TestGen-LLM论文和工具感到兴奋,但在本文中我们也分享了它的局限性。我认为我们仍然处于AI助手的时代,而不是运行完全自动化工作流的AI队友。
同时,良好的工程流程,我们计划在Cover-Agent中开发和共享的流程,可以帮助我们自动地生成测试候选,从而在短时间内增加代码覆盖率。
我们打算继续开发并将与测试生成领域相关的前沿方法整合到Cover-Agent的开源仓库中。 我们鼓励任何对用于测试的生成式AI感兴趣的人员合作,帮助扩展Cover Agent的功能,并希望激发研究人员利用此开源工具探索新的测试生成技术。
在GitHub上的Cover-Agent开源仓库中,我们添加了一个开发路线图。我们非常欢迎按照路线图或者根据自己的想法为仓库做出贡献!
我们对Cover-Agent的愿景是,未来它将为每个预/后拉取请求自动运行,并自动建议经过验证有效且能增加代码覆盖率的回归测试改进。我们设想Cover-Agent将自动扫描您的代码库,并为您打开包含测试套件的PR。
让我们利用AI来帮助我们更高效地应对那些我们不喜欢做的任务吧!
附言: 我们仍在寻找类似工具的良好基准。你知道有吗?我们认为这对于进一步开发和研究至关重要。 请查看我们的AlphaCodium工作,有关“流程工程”的进一步阅读示例,以及一个竞争编程基准,还有一个名为CodeContests的精心设计的数据集。
